Zookeeper 的基本使用
维基百科对 Zookeeper 的介绍如下所示:
Apache ZooKeeper是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册
ZooKeeper 的架构通过冗余服务实现高可用性。因此,如果第一次无应答,客户端就可以询问另一台ZooKeeper主机。ZooKeeper节点将它们的数据存储于一个分层的名字空间,非常类似于一个文件系统或一个前缀树结构。客户端可以在节点读写,从而以这种方式拥有一个共享的配置服务。更新是全序的
简单来讲,Zookeeper 就是一个在分布式应用中用于管理多个服务主机的应用(比较粗略)
Zookeeper 的安装
首先从 Zookeeper 的 官网 下载需要的 Zookeeper 的版本,直接下载二进制版本即可,如下图所示:

进去之后,再点击对应的下载链接即可:

下载完成之后,会得到一个
.tar.gz的文件,需要对这个文件进行解压,如果是在 Linux 环境下的话,直接使用命令tar -zxvf *.tar.gz即可完成解压,但是如果使用的是 Windows 的话,那么就需要下载对应的解压缩工具,7z 是一个十分优秀的压缩工具,能够完成这个任务解压完成之后,现在还是不能直接运行 Zookeeper 的,首先需要为启动 Zookeeper 创建一个配置文件,在解压完成之后的
conf目录下会有一个zoo_sample.cfg的文件,这个文件是一个配置文件的示例文件,首先,在conf目录下后创建一个名为zoo.cfg的文件,将zoo_sample.cfg文件中的内容复制到zoo.cfg文件中,此时再编辑zoo.cfg中的配置内容,最后配置的具体解释如下所示:# Zookeeper 的时间配置(单位:ms)
tickTime=2000 # 允许 follower(子节点)初始化连接到 leader(领导者)的最大时长,这个属性表示 tickTime 的倍数
# 以 10 为例,表示最大时长为 tickTime 的 10 倍
initLimit=10 # 允许 follwer 与 leader 数据同步的最大时长,该属性也是表示 tickTime 的时间倍数
syncLimit=5 # zookeeper 的数据存储目录和日志保存目录,如果没有指定这个属性,
# 那么 /tmp/zookeeper 目录将是默认的存储目录
dataDir=/tmp/zookeeper # 对客户端提供的连接端口
clientPort=2181 # 对单个客户端提供的最大并发连接数
maxClientCnxns=60 # 保存的数据快照的数量,超过这个数量的数据快照将会被删除
autopurge.snapRetainCount=3 # 自动发生清除任务的时间间隔,以小时为单位,如果设置为 0 则表示不清除
autopurge.purgeInterval=1 # 以下是一些指标的配置信息,不是特别重要,忽略。。。
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
现在,就可以启动 Zookeeper 了(前提是已经安装好了 JDK 并且设置了
JAVA_HOME的环境变量),执行bin目录下对应的启动脚本./bin/zkServer.sh start即可:
启动成功的结果如下图所示

此时再执行脚本查看 Zookeeper 的状态,可能会看到类似下面的输出:

其中,Mode 为 “standalone” 表示当前的启动模式为单机模式
如果此时想要连接到 Zookeeper,可以执行./bin/zkCli.sh的脚本,这个脚本执行之后就会自动连接到localhost:2181即 Zookeeper 的默认端口
如果需要停止 Zookeeper 的话,执行./bin/zkServer.sh stop命令即可
以上操作均在 Linux 环境下执行,如果是 Windows 系统的话,可以转换成对应的*.cmd执行
数据模型
数据存储结构
Zookeeper 的数据保存在节点(znode)上多个 znode 之间能够形成一个树形的结构,如下图所示:

注意,这里的树只表示结构,没有大小之分
- 在树中,树是由节点组成的,Zookeeper 的数据存储结构和树结构类似,在 Zookeeper 的树结构中,将这些节点称之为 znode
- Zookeeper 对于数据的查找类似于文件的查找,以上图为例,假设现在需要查找
/b节点,那么最终的查找结果将会是/a/b,而不是单纯的一个/b - 使用这种类似于文件树的结构,使得每个节点之间都被隔离,同时还能够加快查找的速度
znode 的结构
一个 znode 包含下面四个部分:
data:当前节点保存的具体数据内容
acl:权限信息,定义只有用于具体权限的客户才能够操作这个节点,具体存在以下几个权限:
- c(create):创建权限,允许在当前节点下创建子节点
- w(write):更新权限,允许更新该节点的数据
- r(read):读取权限,允许读取该节点的内容以及子节点的列表信息
- d(delete):删除权限,允许删除该节点的子节点
- a(admin):管理员权限,允许对该节点进行 acl 权限设置
stat:描述当前 znode 的元数据,具体如下表所示:
名称 解释 cZxid 创建该节点的事务 id ctime 节点的创建时间 mZxid 修改节点的事务 id mtime 节点最近的修改时间 pZxid 添加和删除子节点的事务 id cversion 当前节点的子节点版本号,初始值为 -1,每对该节点的子节点进行操作,这个值都会增加 dataVersion 当节点的数据版本号,初始版本为 0,每对该节点的数据进行操作,这个 dataVersion 都会自动增加 aclVersion 此节点的权限版本 ephemeralOwner 如果当前节点是临时节点,那么这个值就是当前的 sessionId;如果不是临时节点,那么这个值就是 0 dataLength 节点内数据的长度 numChildren 该节点的子节点个数 child:当前节点的子节点
znode 的类型
- 持久节点:新创建出的节点,在会话数据之后依旧存在,会保存数据,直接在会话中通过
create命令创建的节点就是持久节点 - 持久序号节点:具有持久节点的特性,同时在创建时会根据先后顺序,在节点之后带上数值,越靠后执行这个数值将会越大,适合使用分布式锁。通过在
create命令后加上-s选项即可创建持久序号节点 - 临时节点:创建一个临时节点之后,如果创建节点的会话结束,那么该节点将会自动地删除,通过这个特性,Zookeeper 可以实现服务的注册与发现;临时节点通过心跳机制,向 Zookeeper 服务告知自己的存活情况。通过为
create命令加上-e选项即可创建一个临时节点 - 临时序号节点:临时节点 + 序号节点,通过为
create命令加上-s -e选项即可创建临时序号节点 - 容器节点(Container Node):Zookeeper 3.5.3 新增的节点,当创建完容器节点之后,如果该节点下面没有任何子节点,那么 60 s 之后,该节点将会被删除。通过为
create命令加上-c选项即可创建容器节点 - TTL 节点:可以指定节点的到期时间,到期之后将会被 Zookeeper 删除,需要通过在配置文件中添加
zookeeper.extendedTypesEnabled=true开启。开启之后重启 Zookeeper,通过为create命令添加-t选项即可创建 TTL 节点,-t选项之后需要添加过期时间
- 持久节点:新创建出的节点,在会话数据之后依旧存在,会保存数据,直接在会话中通过
数据持久化机制
由于 Zookeeper 的数据运行在内存中,因此需要将数据持久化到磁盘上,Zookeeper 提供了两种持久化的方式将数据持久化到磁盘:
- 事务日志:Zookeeper 把执行的命令以日志的形式保存在
dataLogDir指定的文件中,如果没有设置dataLogDir,那么将会保存到dataDir指定的目录下 - 数据快照:Zookeeper 会在一定的时间间隔内做一次内存数据的快照,把这段时间内的内存数据保存到快照文件中
实际上,Zookeeper 会结合使用两种持久化的方式,在恢复数据时首先恢复快照文件中的数据到内存中,再利用日志文件中的数据做增量恢复,从而提高了恢复数据的速度
- 事务日志:Zookeeper 把执行的命令以日志的形式保存在
基本使用
一般情况下,使用 Java 直接与 Zookeeper 进行交互是痛苦的,使用第三方框架是一个很好的选择。
Curator 是 Netflix 公司开源的一套 Zookeeper 客户端框架,Curator 封装了大部分 Zookeeper 的功能,比如:Leader选举、分布式锁等等,极大的减轻了开发者在使用Zookeeper时的底层细节开发工作。
使用时首先需要加入对应的依赖,以 maven 项目为例,添加如下的依赖:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>${zk.version}</version> <!-- 当前 zk 版本为 3.7.2,需要与使用的版本对应 -->
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>${curator.version}</version> <!-- 当前 curator 版本为 5.2.0 -->
<exclusions>
<!-- 这里的排除是必须的,否则可能会出现 zk 版本冲突的问题 -->
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
随后创建一个配置类,配置相关的属性,如:超时时间、连接地址等。可以手动在 Bean 中完成设置,但是为了更加通用,使用属性配置类的方式来配置相关的属性。
首先,定义配置属性类 ZkConfig:
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableConfigurationProperties // 开启配置属性的功能
@ConfigurationProperties(prefix = "curator") // 设置配置属性前缀
public class ZkConfig {
// 重试次数
private int retryCount;
// 重试的间隔时间(单位:ms)
private int sleepBetweenRetries;
// zk 的连接地址(多个 zk 的时候,使用 , 分隔)
private String connect;
// 会话超时时间(单位:ms)
private int sessionTimeout;
// 连接超时时间(单位:ms)
private int connectionTimeout;
// 省略部分 setter 和 getter 方法
}
再配置 application.yml 文件,配置对应的属性:
# 与 ZkConfig 的属性对应
curator:
retry-count: 5
sleep-between-retries: 30000
connect: 127.0.0.1:2181
session-timeout: 6000
connection-timeout: 5000
再将配置的属性放入到配置 Bean 中,创建一个新的配置类 CuratorConfig:
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryNTimes;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.Resource;
@Configuration
public class CuratorConfig {
@Resource
private ZkConfig zkConfig;
@Bean(initMethod = "start")
public CuratorFramework curatorFramework() {
// 重试策略。。。
RetryPolicy retryPolicy = new RetryNTimes(
zkConfig.getRetryCount(),
zkConfig.getSleepBetweenRetries()
);
// 使用工厂方法创建新的 CuratorFramework 对象
return CuratorFrameworkFactory.newClient(
zkConfig.getConnect(),
zkConfig.getSessionTimeout(),
zkConfig.getConnectionTimeout(),
retryPolicy
);
}
}
最后,使用创建的 CuratorFramework 类型的 Bean 操作 Zookeeper:
首先,定义一些以下的不可变属性:
static final Logger log = LoggerFactory.getLogger(ZkExampleApplicationTests.class);
private final static String NODE_NAME = "/curator-node";
private final static String EPHEMERAL_NODE_NAME = "/curator-ephemeral-node";
private final static String PARENT_NODE_NAME = "/animal/dog/whiteDog";
private final static byte[] VALUE_BYTES = "xhliu".getBytes();
private final static byte[] NEW_VALUE_BYTES = "xhliu-new".getBytes();
创建持久节点
// curatorFramework 由 Spring 完成依赖注入,下同
void createNode() throws Exception {
String path = curatorFramework.create()
.forPath(NODE_NAME, VALUE_BYTES);
log.info("Create Node Success, znode={}", path);
}
创建临时节点
void createEphemeralNode() throws Exception {
String path = curatorFramework.create()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(EPHEMERAL_NODE_NAME, VALUE_BYTES);
log.info("Create Ephemeral Node success, znode={}", path); Thread.sleep(10000); // 在这个线程(会话)的存活期间,这个临时节点都是有效的
}
创建父节点
void createWithParent() throws Exception {
String path = curatorFramework.create()
.creatingParentsIfNeeded() // 如果父节点不存在,则创建对应的父节点
.forPath(PARENT_NODE_NAME, VALUE_BYTES);
log.info("Create Node Success, znode={}", path);
}
获取节点的值
void getData() throws Throwable {
byte[] valueByte = curatorFramework.getData()
.forPath(NODE_NAME); log.info("getData()={}", new String(valueByte));
}
修改节点的值
void setData() throws Throwable {
curatorFramework.setData()
.forPath(NODE_NAME, NEW_VALUE_BYTES);
}
使用场景
Zookeeper 分布式锁
如果要直接使用 Zookeeper 来实现分布式锁,一般情况下还是建议直接使用成熟的第三方工具类,避免自己手动来实现,但是实现原理是一定要弄清楚的
Curator 也提供了关于 Zookeeper 分布式锁的实现,直接使用即可,使用之前需要添加以下的依赖项:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${curator.version}</version> <!-- 具体与上文的 Curator FrameWork 对应 -->
<exclusions>
<!-- 在上文中已经引入了 curator framework 的依赖,这里就不再需要了 -->
<exclusion>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
</exclusion>
</exclusions>
</dependency>
读写锁
读锁
多个客户端都可以执行读取的操作,彼此之间不会阻塞,在这个基础之上有一个前提条件:不存在对该资源加上了写锁的客户端
可以 Zookeeper 来实现分布式的读锁,可以按照如下步骤来实现:
- 首先创建一个
/lock的 znode,用于区分。在这个 znode 的节点下面创建临时序号节点/lock/READ-,表示将要获取的 “读锁” - 然后检查
/lock下面的所有子节点,按照临时节点的顺序进行排序 - 检查在这个读锁之前是否已经存在写锁,如果存在写锁则注册一个对前一个写锁的监听器,然后阻塞该读锁的获取
- 如果监听器检测到前一个写锁已经释放了,那么该读锁将会成功地被获取
使用 Curator 来直接使用 Zookeeper 实现的分布式读锁:
// 注入之前配置好的 CuratorFramework 配置类
@Resource
private CuratorFramework curatorClient; void getReadLock() throws Exception {
InterProcessReadWriteLock lock =
new InterProcessReadWriteLock(curatorClient, "/lock");
InterProcessMutex readLock = lock.readLock(); log.info("等待获取读锁.......");
readLock.acquire();
log.info("获取读锁成功,进入下一步的操作"); Thread.sleep(10000);
readLock.release();
log.info("任务完成,释放读锁");
}
- 首先创建一个
写锁
如果多个客户端同时去获取写锁,在同一时刻只能有一个客户端能够获得写锁,这些客户端之间会由于写锁的存在而相互阻塞。如果一个客户端想要获取一个写锁,在这之前也有一个前提条件:没有任何客户端对这个资源加上任意形式的锁(包括读锁和写锁)
Zookeeper 实现写锁的步骤如下:
- 首先,依旧是在
/lock的 znode 节点下,创建临时序号节点/lock/WRITE-,该节点就代表将要获取的 写锁节点 - 检查
/lock节点下的子节点,按照临时节点的序号进行排队 - 检查在该写锁之前是否存在锁(包括写锁和读锁),如果存在锁,那么先注册一个对前一个锁的监听器,然后阻塞该写锁的获取
- 如果监听器检测到前一个锁已经释放,则成功获取该写锁
- 首先,依旧是在
相比较于使用 Redis 通过 RedLock 算法来实现的分布式锁,Zookeeper 实现的分布式锁更加地稳定,如果可以,选择 Zookeeper 来实现分布式锁是一个更好的选择
Zookeeper 注册中心
除了实现分布式锁之外,Zookeeper 也可以用来实现服务注册和发现的功能,在此之前,需要搭建一个 Zookeeper 集群,才能保证注册中心的稳定性
Zookeeper 集群
Zookeeper 集群中的角色介绍
- Leader:处理集群的所有事务请求,同一个集群中只能有一个 Leader
- Follower:只能处理读请求,同时也可以参与 Leader 的选举
- Observer:只能处理读请求
具体的集群搭建步骤可以参考:https://www.cnblogs.com/ysocean/p/9860529.html
Leader 的选举机制
由于 Zookeeper 通常是采用集群的方式部署,在集群中一般会以一对多的形式进行部署。为了保证数据的一致性,Zookeeper 采用了 ZAB (Zookeeper Atomic Broadcast) 协议来解决数据一致性的问题
在 ZAB 协议中定义了以下几种节点的状态:
- Looking:此时节点的状态处于选举中的状态,此时可能是由于 Leader 崩溃了,正在重新选举 Leader
- Following:Follower 节点此时所处的状态
- Leading:Leader 节点所处的状态
- Observer:观察者节点所处的状态
选举流程:
在进行 Leader 选举的过程中,一台机器无法完成 Leader 的选举,至少需要两台机器才能开始 Leader 的选举任务,这里以 3 台机器组成的服务器集群为例,介绍一下 Leader 的选举流程
第一轮 Leader 选举投票
假设此时只有 Server 1 和 Server 2 这两台机器启动了,在这种情况下,这两个 Server 都会将自己视为 Leader 参与选举,进行一次投票(给自身投票)。这次的投票会包含所推荐的 Server 的
myid和ZXID两个字段,假设此时 Server 1 对应的两个属性为 (1, 0),Server 2 的这两个属性为(2, 0),这两个投票信息会发送到集群中的其它机器投票结束之后,此时每个 Server 应该都会含有一个候选票的集合,按照如下的规则进行比较,选择合适的投票放入选票箱:首先对比
ZXID,优先选择ZXID较大的投票;如果ZXID相同,则再比较myid,优先选择myid较大的选票因此,最终两个 Server 中会将 Server 2 的投票作为第一次选票的结果
第二轮 Leader 选举投票
首先每个Server 将第一轮得到的选票结果再投出去,按照第一轮中选票的规则再选择一次投票,本次投票结束之后,将会统计投票的信息,判断是否已经有超过一半的机器收到了相同的投票信息,对于此时的 Server 1 和 Server 2 而言,此时集群中的两台机器都已经将
myid为 2 的机器作为了最优的投票,已经超过了集群中机器数量的一般,因此此时 Server 2 就是新选择出来的 Leader 节点如果此时第三台机器在选票完成之后再加入到集群中,发现已经有 Leader 节点了,那么自动将自己视为 Follower 节点
在 Leader 选举完成之后,会周期性的不断向 Follower 发送心跳,以检测 Follower 节点是否存活;当 Leader 节点崩溃之后,所有的 Follower 节点将会进入 Looking 状态,按照上面的选举流程重新选举一个新的 Leader,在这个选举的过程中,Zookeeper 集群不能向外界提供服务
数据同步策略
具体数据同步如下图所示:
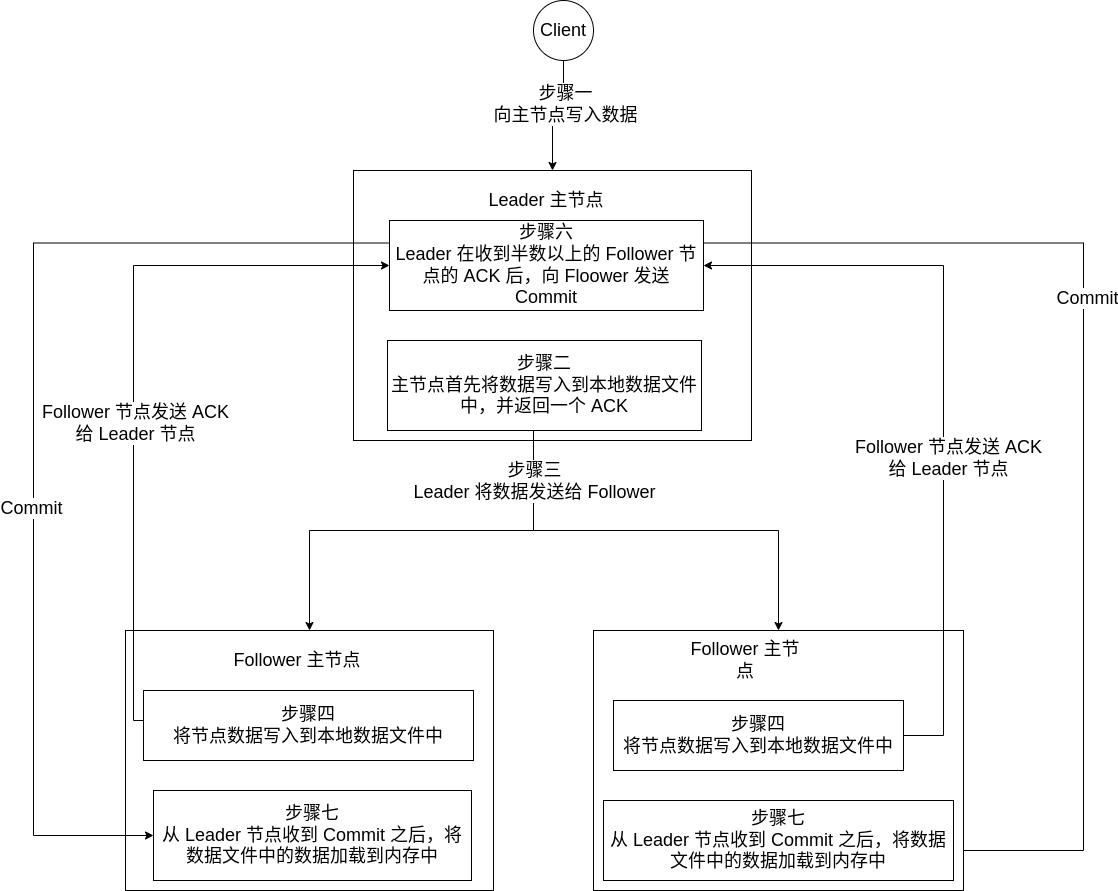
如果客户端已经连接了 Leader 节点,那么将会直接将数据写入到 Leader 节点;如果客户端连接的是 Follower 节点,那么 Follower 节点会将数据转发给 Leader 节点,Leader 节点再将数据写入到 Follower 节点中
参考:
[1] https://mp.weixin.qq.com/s/WW8vtEbRS3xQpx67kPmqTQ
[2] https://www.cnblogs.com/leesf456/p/6107600.html
Zookeeper 的基本使用的更多相关文章
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- [译]ZOOKEEPER RECIPES-Leader Election
选主 使用ZooKeeper选主的一个简单方法是,在创建znode时使用Sequence和Ephemeral标志.主要思想是,使用一个znode,比如"/election",每个客 ...
- zookeeper源码分析之六session机制
zookeeper中session意味着一个物理连接,客户端连接服务器成功之后,会发送一个连接型请求,此时就会有session 产生. session由sessionTracker产生的,sessio ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
- zookeeper源码分析之二客户端启动
ZooKeeper Client Library提供了丰富直观的API供用户程序使用,下面是一些常用的API: create(path, data, flags): 创建一个ZNode, path是其 ...
- zookeeper源码分析之一服务端启动过程
zookeeper简介 zookeeper是为分布式应用提供分布式协作服务的开源软件.它提供了一组简单的原子操作,分布式应用可以基于这些原子操作来实现更高层次的同步服务,配置维护,组管理和命名.zoo ...
- zookeeper集群的搭建以及hadoop ha的相关配置
1.环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 master作为active主机,data1作为standby备用机,三台机器均作为数据节点,yarn资源 ...
- 如何编译Zookeeper源码
1. 安装Ant Ant下载地址:http://ant.apache.org/bindownload.cgi 解压即可. 2. 下载Zookeeper源码包 https://github.com/ap ...
随机推荐
- 内网离线安装docker并配置使用nexus为docker私服
背景 本文简单记录下最近在内网服务器离线安装docker及配置nexus作为docker私服,踩的一些坑.docker和k8s这块技术我跟得不是很紧,18年的时候用过一阵docker,后来发现它并不能 ...
- 【Azure Function App】Python Function调用Powershell脚本在Azure上执行失败的案例
问题描述 编写Python Function,并且在Function中通过 subprocess 调用powershell.exe 执行 powershell脚本. import azure.fun ...
- 11g编译bbed
报错如下: make -f ins_rdbms.mk $ORACLE_HOME/rdbms/lib/bbed Linking BBED utility (bbed) rm -f /u01/app/or ...
- math库常用函数+产生随机数总结
math库常用函数+产生随机数总结 1.对x开平方 double sqrt(x)://返回值为double类型,输入的x类型随意,只要是数的类型 2.求常数e的x次方 double exp(x);// ...
- 虹科分享|虹科Redis企业版数据库带你跑赢MySQL数字时代!
数字革命悄然爆发,数据库也将成为率先破局的关键技术! 借着互联网爆发的东风,前几年MySQL以其过硬的产品能力及开源优势,一度成为全球最受欢迎的关系型数据库.然而,革命的漫长之路才刚开始,MySQL是 ...
- 定时重启Nginx、MySql等服务
利用 Linux Crontab,每天定时重启 Nginx.MySQL等服务. 命令行格式说明 f1 f2 f3 f4 f5 program 其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份 ...
- CodeTON Round 4 (Div. 1 + Div. 2)C
C. Make It Permutation 我们希望尽可能少地进行操作可以使代价最小,我们如果要排列的话,那些重复的元素我们无论如何都要进行删除的,所以我们可以先把去重的代价计算出来,然后依次枚举排 ...
- C++小练习:字符串分割的高性能实现
字符串分割是日常工作中比较常见的基础函数,通常大家会使用现成的基础库,基础库的性能是否是最佳的?本文基于一个周末小练习,研究如何最大限度的提升字符串分割的性能. 1.背景 字符串按照分隔符拆成多个子串 ...
- 用结构化思维解一切BUG(1):核心思路
面对万"卷"世界,有人选择拼命学习新技术,解决眼前的.点状问题:有人提升思维层级,解决未来的.系统问题.您选择什么? 背景 我有10多年编程经验和研发管理经历,虽很久不写代码,但有 ...
- sed 原地替换文件时遇到的趣事
哈喽大家好,我是咸鱼 在文章<三剑客之 sed>中咸鱼向大家介绍了文本三剑客中的 sed sed 全名叫 stream editor,流编辑器,用程序的方式来编辑文本 那么今天咸鱼打算讲一 ...