基于Word2Vec的诗词生成器
基于Word2Vec制作的诗词生成器
1、什么是Word2Vec?
Word2vec 是 Word Embedding 方式之一,属于 NLP 领域。它是从大量文本预料中以无监督方式学习语义知识的模型,被广泛地应用于自然语言处理中。
Word2Vec是将词转化为“可计算”“结构化”的向量的过程,是用来生成词向量的工具,而词向量与语言模型有着密切的关系。
2、基于Word2Vec的诗词生成器的结构
|——GUI诗词生成器.py
|——w_poem.py
|——mo.txt
|——诗词库.txt
GUI诗词生成器.py :GUI界面,用来获取用户输入关键字和作者名,和获取w_poem.py生成的诗词并转换成标签显示在GUI界面
w_poem.py :两个函数,save_model函数用来保存训练数据,write_poem函数调用Word2Vec生成的训练数据,查找与用户输入的关键字相似度最高的词语,根据要求组装成诗词。
mo.txt :保存训练数据
诗词库.txt :原始数据
3、成品
还没有加别的规则和算法,所以得到的诗词并不优美。
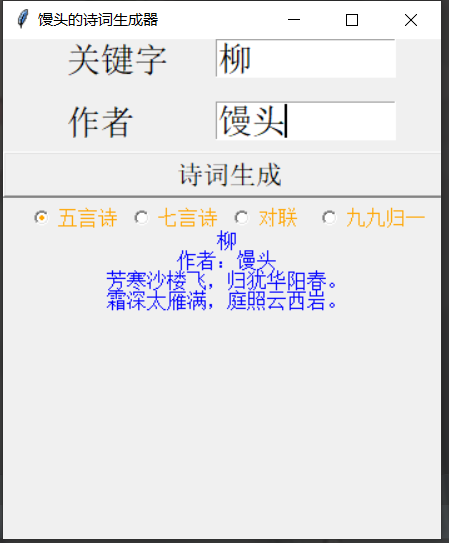
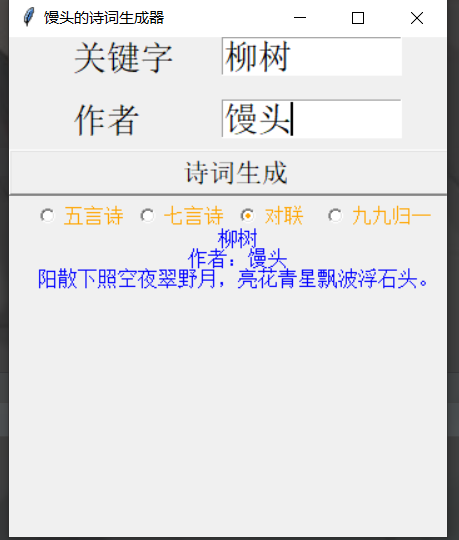
4、代码
GUI诗词生成器.py
from tkinter import *
import w_poem # 创建窗口:实例化一个窗口对象。
class TKK:
def __init__(self):
self.root = Tk()
# 窗口大小
self.root.geometry("350x400+374+182")
# 窗口标题
self.root.title("馒头的诗词生成器")
# 添加关键字标签控件
label = Label(self.root, text=" 关键字 ", font=("宋体", 20))
label.place(x=20,y=0)
# 关键字输入框
self.entry1 = Entry(self.root, font=("宋体", 20), width=10 )
self.entry1.place(x=170,y=0)
#添加作者标签
label = Label(self.root, text=" 作者 ", font=("宋体", 20))
label.place(x=20,y=50)
# 作者输入框
self.entry2 = Entry(self.root, font=("宋体", 20), width=10)
self.entry2.place(x=170,y=50)
# 添加点击按钮
button = Button(self.root, text="诗词生成", width=32,font=("宋体", 16), command=self.getpoem) # command=textt
button.place(x=0,y=90)
# 单选按钮
self.radio = IntVar()
r1 = Radiobutton(self.root, text="五言诗", font=("宋体", 12), fg="orange", variable=self.radio, value=0)
r1.place(x=20,y=130)
r2 = Radiobutton(self.root, text="七言诗", font=("宋体", 12), fg="orange", variable=self.radio, value=1)
r2.place(x=100,y=130)
r3 = Radiobutton(self.root, text="对联", font=("宋体", 12), fg="orange", variable=self.radio, value=2)
r3.place(x=180,y=130)
r5 = Radiobutton(self.root, text="九九归一", font=("宋体", 12), fg="orange", variable=self.radio, value=3)
r5.place(x=250,y=130) # 显示窗口
self.root.mainloop() def getpoem(self):
list_radio = ["五言诗", "七言诗", "对联", "九九归一"]
types = (list_radio[self.radio.get()])
kw = self.entry1.get()
xx = [20 if types=="对联" else 80]
poem_name = self.entry2.get()
te = w_poem.witer_poem(kw ,types,poem_name)
text = Label(text=te,font=("宋体", 12),fg="blue")
text.place(x=xx, y=150) if __name__ == '__main__':
tkk = TKK
tkk()
w_poem.py
from random import choice
from gensim.models import Word2Vec def save_model():
# 保存训练数据
with open("诗词库.txt", 'r', encoding='utf-8') as f:
words = [list(line.strip()) for line in f]
##window=16滑窗大小, min_count = 60过滤低频字
model = Word2Vec(sentences=words, min_count=60, vector_size=200, window=16,)
model.save("mo.txt") def witer_poem(kw, types, poem_name):
typp = {"五言诗": (4, 5), "七言诗": (4, 7), "九九归一": (9, 9), "对联": (2, 9)}
types = typp[types]
shici = list(kw)
# 调用训练数据
model = Word2Vec.load("mo.txt")
for row in range(types[0]):
for col in range(types[1]):
# 查找相似度最高的100个字-topn
pred = model.predict_output_word(context_words_list=shici, topn=100)
# 去除特殊符号
fu = [",", ".","?","‘","“","-","+","=","。","/",";",";",":","[","]",
"{","}","!","@","#","$","%","^","&","*","(",")","、","《","》"]
number = ["1","2","3","4","5","6","7","8","9","0"," ","!"]
rs = [w[0] for w in pred if w[0] not in shici + fu + number]
char = choice([c for c in rs if c not in kw])
shici.append(char)
# 添加标点符号
shici.append("," if row % 2 == 0 and types[0] % 2 == 0 else "。\n")
# 分段显示
sclen = types[0] * (types[1] + 1) # 计算诗词的长度,然后使用-sclen,来找到诗词标题的位置
# 如果是偶数句,则两句一行,否则一行一句
if types[0] % 2 == 0:
# 排版----->第一行题目 第二行作者 剩下的为诗词
last = "%s" % "".join(shici[:-sclen]) + "\n" + \
"作者:" + poem_name + "\n" + \
"".join(shici[-sclen:])
else:
last = "%s" % "".join(shici[:-sclen]) + "\n" + \
"作者:" + poem_name + "\n" + \
"".join(shici[-sclen:])
return last

基于Word2Vec的诗词生成器的更多相关文章
- Silverlight信息加密 - 通过Rfc2898DeriveBytes类使用基于HMACSHA1的伪随机数生成器实现PBKDF2
原文: http://blog.csdn.net/xuyue1987/article/details/6706600 在上一篇文章当中,介绍到了通过Silverlight获取web.config中的值 ...
- 基于word2vec的文档向量模型的应用
基于word2vec的文档向量模型的应用 word2vec的原理以及训练过程具体细节就不介绍了,推荐两篇文档:<word2vec parameter learning explained> ...
- 基于word2vec训练词向量(二)
转自:http://www.tensorflownews.com/2018/04/19/word2vec2/ 一.基于Hierarchical Softmax的word2vec模型的缺点 上篇说了Hi ...
- 基于word2vec训练词向量(一)
转自:https://blog.csdn.net/fendouaini/article/details/79905328 1.回顾DNN训练词向量 上次说到了通过DNN模型训练词获得词向量,这次来讲解 ...
- 结对作业--基于GUI的四则运算生成器
组员:201421123015 陈麟凤 201421123019 张志杰 201421123020 黄海鸿 coding 地址 :https://coding.net/u/zhang1995/p/wo ...
- 结队编程-基于gui的四则运算生成器
成员:卢少锐 201421123027.刘存201421033023 coding.net地址 1.需求分析:除了实现四则运算的功能外,还添加了计时器功能和语言选择功能 2.程序设计:这次作业是基于上 ...
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
- 基于PHP的颜色生成器
<?php function randomColor() { $str = '#'; for($i = 0 ; $i < 6 ; $i++) { ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- word2vec + transE 知识表示模型
本文主要工作是将文本方法 (word2vec) 和知识库方法 (transE) 相融合作知识表示,即将外部知识库信息(三元组)加入word2vec语言模型,作为正则项指导词向量的学习,将得到的词向量用 ...
随机推荐
- vue核心
VUE简介 vue--一套用于构建用户界面的渐进式JavaScript框架 vue特点 采用组件化模式--提高代码复用率--让代码更好维护 声明式编程--让编码人员无需直接操作DOM--提高开发效率 ...
- vue全家桶进阶之路13:生命周期
Vue2的生命周期是指Vue实例从创建.挂载.更新.销毁等各个阶段中所经历的一系列过程.Vue2的生命周期共有8个阶段,分别是: beforeCreate:Vue实例被创建之前的阶段,此时Vue实例的 ...
- Java程序设计复习提纲(下:图形界面)
目录 上:Java程序设计复习提纲(上:入门语法) - 孤飞 - 博客园 (cnblogs.com) 基本语法与编译运行 数据类型和关键字 常用语法 数组与字符串 异常处理 中:Java程序设计复习提 ...
- kafka生产者你不得不知的那些事儿
前言 kafka生产者作为消息发送中很重要的一环,这里面可是大有文章,你知道生产者消息发送的流程吗?知道消息是如何发往哪个分区的吗?如何保证生产者消息的可靠性吗?如何保证消息发送的顺序吗?如果对于这些 ...
- 2019年蓝桥杯C/C++大学B组省赛真题(迷宫)
题目描述: 下图给出了一个迷宫的平面图,其中标记为1 的为障碍,标记为0 的为可 以通行的地方. 010000 000100 001001 110000 迷宫的入口为左上角,出口为右下角,在迷宫中,只 ...
- celery笔记二之建立celery项目、配置及几种加载方式
本文首发于公众号:Hunter后端 原文链接:celery笔记二之建立celery项目.配置及几种加载方式 接下来我们创建一个 celery 项目,文件夹及目录如下: proj/__init__.py ...
- 一文吃透Java并发高频面试题
内容摘自我的学习网站:topjavaer.cn 分享50道Java并发高频面试题. 线程池 线程池:一个管理线程的池子. 为什么平时都是使用线程池创建线程,直接new一个线程不好吗? 嗯,手动创建线程 ...
- 三分钟免费将 Claude API 接入个人服务
首先我们介绍一下今天的主角 Claude Claude 是最近新开放的一款 AI 聊天机器人,是世界上最大的语言模型之一,比之前的一些模型如 GPT-3 要强大得多,因此 Claude 被认为是 Ch ...
- CF1770F Koxia and Sequence
一步都没想到,一定是状态不好吧,一定吧一定吧? 加训数数! 题意 给定 \(n, x, y\),定义好的序列 \(\{a_i\}_{i = 1}^n\) 满足 \(\sum\limits_{i = 1 ...
- 本地python调试 问题笔记
ImportError: cannot import name 'int_classes' from 'torch._six' 把 "from torch._six import stri ...