KingbaseES垃圾回收参数优化之maintenance_work_mem
maintenance_work_mem 参数说明与vacuum过程
maintenance_work_mem , autovacuum_work_mem。
如果没有设置autovacuum_work_mem,默认值是-1,则使用maintenance_work_mem的设置值。
首先这部分内存最大的用处是用于vacuum进程操作。过程如下:
(1) 从指定的表中获取每个表。
(2) 获取表的ShareUpdateExclusiveLock锁。该锁允许从其他事务中读取。
(3) 扫描所有页面以获取所有死元组,必要时冻结旧元组。
(4) 如果存在死元组,则删除指向相应死元组的索引元组。
(5) 对表的每一页执行以下任务,步骤 (6) 和 (7)。
(6) 移除死元组并重新分配页面中的活元组。
(7) 更新目标表各自的FSM和VM。
(8) 通过 index_vacuum_cleanup() 函数清理索引。
(9) 如果最后一页没有任何元组,则截断最后一页。
(10) 更新与目标表的vacuum处理相关的统计信息和系统目录。
(11) 更新与vacuum处理相关的统计和系统目录。
(12) 如果可能,删除不必要的文件和阻塞页面。
首先,数据库扫描一个目标表以构建一个死元组列表,并在可能的情况下冻结旧元组。该列表存储在本地内存中的autovacuum_work_mem或maintenance_work_mem中。冻结处理又分慵懒模式和饥饿模式,这里不做赘述。
扫描后,数据库通过引用死元组列表来删除索引元组。 此过程在内部称为“清理阶段”。不用说,这个过程是昂贵的。在KingbaseESV8R6 或更高版本中,如果目标索引为 B-tree,则是否执行清理阶段由配置参数Vacuum_cleanup_index_scale_factor决定。
当maintenance_work_mem已满且扫描未完成时,数据库进行步骤(4)至(7);然后返回步骤(3)并进行余数扫描。也就是开始INDEX的扫描,当所有索引都扫描并清理了一遍后,继续从刚才的内存满的点开始扫描表。如此反复,当多次maintenance_work_mem满后,会出现索引扫描多次。
如图:vacuum扫描索引,删除索引的过程。
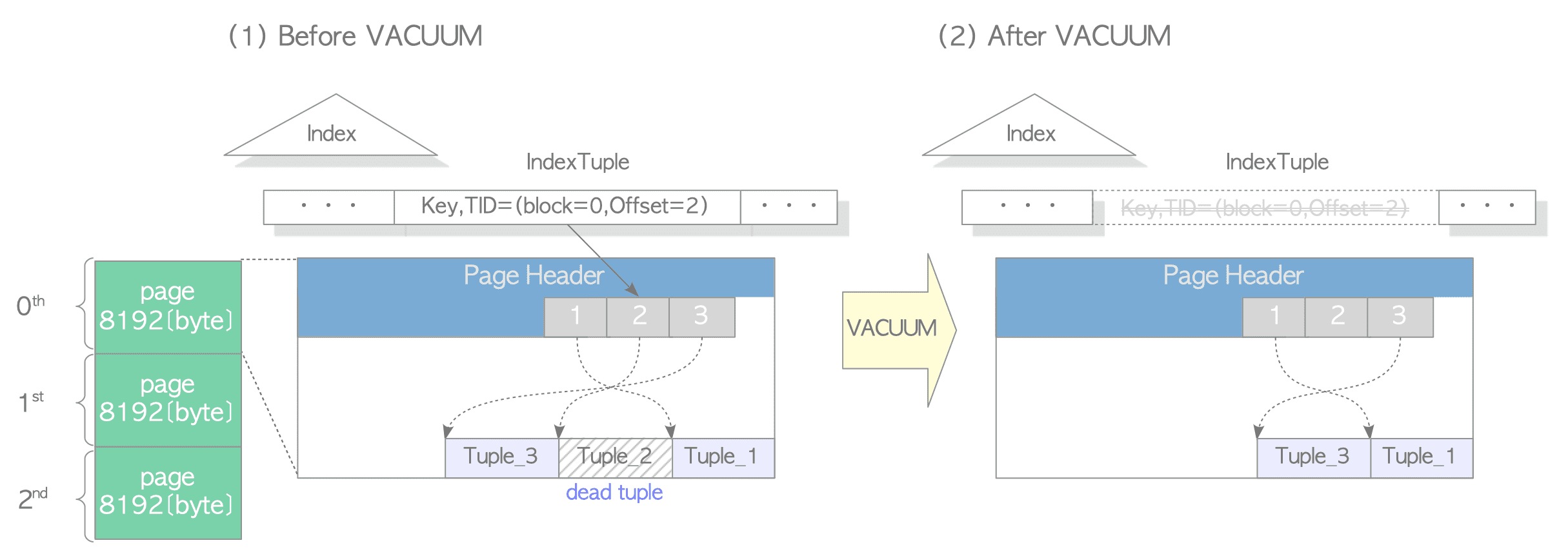
(8)至(10)步骤在删除索引后执行清理,并更新与每个目标表的vacuum处理相关的统计信息和系统目录。
此外,如果最后一页没有元组,则将其从表文件中截断。
显然,步骤中看出重要问题是autovacuum_work_mem太小,INDEX会被多次扫描,非常浪费资源,时间。对于一个大表,多次扫描索引的代价非常昂贵,特别是在表中有很多索引的情况下。如果maintenance_work_mem设置太低,甚至需要多次索引扫描。那将非常考验性能。因此,需要将maintenance_work_mem设置得足够高,这样就避免多次索引扫描。VACUUM VERBOSE TABLE 可以看到详情索引被扫描了几次。
关联重要提示:
1)客户现场遇到的问题是autovacuum_work_mem或maintenance_work_mem内存太小会导致autovacuum进程忙不过来,直观感受就是对于大表有很多dead_tuple的情况,last_autovacuum为空或者很久不触发autovacuum进程工作。当调大maintenance_work_mem,问题得到解决。
2)maintenance_work_mem的总内存消耗等于maintenance_work_mem*autovacuum_max_workers。当然理论是不会达到内存上限。
这部分内存是随用随分配,并不是直接全部用掉maintenance_work_mem或autovacuum_work_mem设置的全部内存。也就是说maintenance_work_mem设置的是实际上限值。这部分内存不包括你可能手工发起的VACUUM或 CREATE INDEX操作所需的内存。那么就要求maintenance_work_mem足够高。注意autovacuum_max_workers进程的数量和表的数量相对应,如果autovacuum_max_workers设置3,那么只能同时并行vacuum3张表,对于分区表将以子分区为单位进行vacuum。至此,有没有发现大的服务器内存和ssd存储对于vacuum性能至关重要。
maintenance_work_mem的另外一个用途,它控制构建索引时使用的最大内存量。构建B树索引时,必须对数据排序,如果要排序的数据在maintenance_work_mem内存中放置不下,它将会溢出到磁盘中。在执行CREATE INDEX命令之前,你可以在本地会话中使用SET命令临时增加该值。``
maintenance_work_mem的内存空间优化
之前发了一篇文章讨论没有及时autovacuum的原因,现在补充一条原因,这是近期的发现。有时候即使该表触及到了20%的阈值,autovacuum进程可能也没有启动,比如它正在忙于处理其他一些表,由于受到autovacuum_max_workers进程的影响,清理进程可能在该表触及20%阈值之前就开始工作了,没有多余的进程或者内存空间再去执行后续触及阈值的表的清理工作。
如果你确实有非常大的表,可以做一件事,将autovacuum_vacuum_scale_factor减少到一个更小的值。你可以在死亡元组到达表大小的1%时就清理,甚至是表大小的0.1%。还可以分别针对每个表进行配置,这样可以规避vacuum造成的IO高峰的问题,与设置大的触发阈值相比,更频繁地清理表并每次只扫描一遍索引,与较少扫描表但每次扫描多遍索引相比,并不一定会节省I/O时间。然而,我们需要考虑对前台进程的影响。但是别忘了特别是对于非常大的表,频繁清理往往会显著提升查询性能,因为每次顺序扫描扫的是全表,包括死亡元组的行。
建议将log_autovacuum_min_duration设置为非默认值,因为它将告诉你autovacuum进程正在做什么工作,这对故障诊断很有用。把这个参数值设置为0,但会记录autovacuum进程执行的每个操作,但是很可能生成巨大的日志量,不建议这样设置。建议把它设置成表级参数,这样不仅能排查问题,还有效规避了日志量巨大的问题。日志消息中,如果看到“index scans: 2”或更大的值,则表示maintenance_work_mem内存快用完了,应该考虑增加该配置值。
maintenance_work_mem的内存计算
设置maintenance_work_mem=1GB,最多有1GB的内存,用于记录一次vacuum时,一次可存储的垃圾tuple的tupleid,tupleid为6字节长度。
1G可存储约1.7亿条dead tuple的tupleid。
test=# select 1024*1024*1024/6;
?column?
-----------
178956970
(1 row)
默认死亡元组约等于表大小的20%,触发垃圾回收。
那么1G总共能存下多大的含死亡元组的表呢?约8.9亿条记录的表。
test=# select 1024*1024*1024/6/0.2;
?column?
--------------------
894784850.00000000
(1 row)
总结
1、log_autovacuum_min_duration=0,表示记录所有表autovacuum的统计信息。这会使日志量巨大,建议对大表单独设置。
2、autovacuum_vacuum_scale_factor=0.01,表示1%的垃圾时,触发自动垃圾回收。这会使垃圾回收提前量,前面提到了,如果多表同时发生autovauum,会受到垃圾回收最大进程的影响,所以最好在表级别设置此参数,以达到频繁的运行autovacuum进程并不会发生io拥挤现象。最有效的作用是频繁vacuum帮助顺序扫描避免扫描过多死亡元组。
3、autovacuum_work_mem,maintenance_work_mem根据实际情况设定,确保不出现垃圾回收时多次INDEX SCAN的数值.可以表级别设置log_autovacuum_min_duration,在日志中观察INDEX SCAN的数量。或者手工vacuum verbose table也可看到。
4、当触发垃圾数据阈值的表很多,尤其是大表的情况,建议增加autovacuum_max_workers,避免有的表autovacuum不及时,但要注意总内存消耗。
5、当出现了index scans: 超过1的情况:
5.1、需要增加autovacuum_work_mem,或maintenance_work_mem增加到当前autovacuum_work_mem乘以index scans数量即可。
5.2、或者调低autovacuum_vacuum_scale_factor到当前值除以index scans即可,目的是让autovacuum尽可能早的工作。
KingbaseES垃圾回收参数优化之maintenance_work_mem的更多相关文章
- 五个Taurus垃圾回收compactor优化方案,减少系统资源占用
简介 TaurusDB是一种基于MySQL的计算与存储分离架构的云原生数据库,一个集群中包含多个存储几点,每个存储节点包含多块磁盘,每块磁盘对应一个或者多个slicestore的内存逻辑结构来管理. ...
- 案例实战:每日上亿请求量的电商系统,JVM年轻代垃圾回收参数如何优化?
出自:http://1t.click/7TJ 目录: 案例背景引入 特殊的电商大促场景 抗住大促的瞬时压力需要几台机器? 大促高峰期订单系统的内存使用模型估算 内存到底该如何分配? 新生代垃圾回收优化 ...
- 每日上亿请求量的电商系统,JVM年轻代垃圾回收参数如何优化? ----实战教会你如何配置
目录: 案例背景引入 特殊的电商大促场景 抗住大促的瞬时压力需要几台机器? 大促高峰期订单系统的内存使用模型估算 内存到底该如何分配? 新生代垃圾回收优化之一:Survivor空间够不够 新生代对象躲 ...
- jvm参数优化
一.HotSpot JVM 提供了三类参数 现在的JVM运行Java程序(和其它的兼容性语言)时在高效性和稳定性方面做的非常出色.例如:自适应内存管理.垃圾收集.及时编译.动态类加载.锁优化等.虽然有 ...
- Python内存管理方式和垃圾回收算法解析
在列表,元组,实例,类,字典和函数中存在循环引用问题.有 __del__ 方法的实例会以健全的方式被处理.给新类型添加GC支持是很容易的.支持GC的Python与常规的Python是二进制兼容的. 分 ...
- tomcat jvm参数优化
根据gc(垃圾回收器)的选择,进行参数优化 JVM给了三种选择:串行收集器.并行收集器.并发收集器,但是串行收集器只适用于小数据量的情况,所以这里的选择主要针对并行收集器和并发收集器. -XX:+Us ...
- .Net平台GC VS JVM垃圾回收
前言 不知道你平时是否关注程序内存使用情况,我是关注的比较少,正好借着优化本地一个程序的空对比了一下.Net平台垃圾回收和jvm垃圾回收,顺便用dotMemory看了程序运行后的内存快照,生成内存快照 ...
- JavaScript 之垃圾回收和内存管理
JavaScript 具有自动垃圾收集机制(GC:Garbage Collecation),也就是说,执行环境会负责管理代码执行过程中使用的内存.而在 C 和 C++ 之类的语言中,开发人员的一项基本 ...
- 《JavaScript 闯关记》之垃圾回收和内存管理
JavaScript 具有自动垃圾收集机制(GC:Garbage Collecation),也就是说,执行环境会负责管理代码执行过程中使用的内存.而在 C 和 C++ 之类的语言中,开发人员的一项基本 ...
- JVM实用参数(五)新生代垃圾回收
本部分,我们将关注堆(heap) 中一个主要区域,新生代(young generation).首先我们会讨论为什么调整新生代的参数会对应用的性能如此重要,接着我们将学习新生代相关的JVM参数. 单纯从 ...
随机推荐
- springboot集成腾讯cos实现文件上传
腾讯对象存储介绍 对象存储(Cloud Object Storage,COS)是腾讯云提供的一种存储海量文件的分布式存储服务,具有高扩展性.低成本.可靠安全等优点.通过控制台.API.SDK 和工具等 ...
- 数据抽取平台pydatax介绍--实现和项目使用
数据抽取平台pydatax实现过程中,有2个关键点: 1.是否能在python3中调用执行datax任务,自己测试了一下可以,代码如下: 这个str1就是配置的shell文件 try: resu ...
- 【LeetCode二叉树#12】合并二叉树(巩固层序遍历)
合并二叉树 力扣题目链接(opens new window) 给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠. 你需要将他们合并为一个新的二叉树.合并的规则是如果 ...
- 【应用服务 App Service】App Service 中部署Java项目,查看Tomcat配置及上传自定义版本
当在Azure 中部署Java应用时候,通常会遇见下列的问题: 如何部署一个Java的项目呢? 部署成功后,怎么来查看Tomcat的服务器信息呢? 如果Azure提供的默认Tomcat版本的配置跟应用 ...
- 浅入Kubernetes(9):了解组件
本篇主要介绍 Kubernetes 中的架构组成,在前面我们已经学习到了 kubeadm.kubectl,这两个命令行工具是 k8s 组成之一.而前面在搭建集群时,也学到了 master.worker ...
- 浅入 ABP 系列教程目录汇总
浅入ABP(1):搭建基础结构的 ABP 解决方案 https://www.cnblogs.com/whuanle/p/13675889.html 浅入ABP(2):添加基础集成服务 https:// ...
- 探索图片与Base64编码的优势与局限性
一.图片和Base64编码的关系: 图片是一种常见的媒体文件格式,可以通过URL进行访问和加载. Base64编码是一种将二进制数据转换为ASCII字符的编码方式,可以将图片数据转换为字符串形式. 图 ...
- 从 HPC 到 AI:探索文件系统的发展及性能评估
随着 AI 技术的迅速发展,模型规模和复杂度以及待处理数据量都在急剧上升,这些趋势使得高性能计算(HPC)变得越来越必要.HPC 通过集成强大的计算资源,比如 GPU 和 CPU 集群,提供了处理和分 ...
- Djiango视图层和模型层
Djiango 使用教程 目录 Djiango 使用教程 一. 视图层 1.1 HttpResponse,render,redirect 1.2 JsonResponse 1.3 form表单上传文件 ...
- 关于vue.js:iview-Bug-5114在iview的Poptip气泡提示内调用DatePicker出现遮挡或同时关闭窗口等冲突问题[转]
转自:https://lequ7.com/guan-yu-vuejsiviewbug5114-zai-iview-de-poptip-qi-pao-ti-shi-nei-diao-yong-datep ...