CVPR 2023 | RCF:完全无监督的视频物体分割
TLDR: 视频分割一直是重标注的一个task,这篇CVPR 2023文章研究了完全不需要标注的视频物体分割。仅使用ResNet,RCF模型在DAVIS16/STv2/FBMS59上提升了7/9/5%。文章里还提出了不需要标注的调参方法。代码已公开可用。
Paper title: Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
arXiv: https://arxiv.org/abs/2304.08025
作者机构:UC Berkeley, MSRA, UMich
Project page: https://rcf-video.github.io/
Code and models: https://github.com/TonyLianLong/RCF-UnsupVideoSeg
视频物体分割真的可以不需要人类监督吗?
视频分割一直是重标注的一个task,可是要标出每一帧上的物体是非常耗时费力的。然而人类可以轻松地分割移动的物体,而不需要知道它们是什么类别。为什么呢?
Gestalt定律尝试解释人类是怎么分割一个场景的,其中有一条定律叫做Common Fate,即移动速度相同的物体属于同一类别。比如一个箱子从左边被拖到右边,箱子上的点是均匀运动的,人就会把这个部分给分割出来理解。然而人并不需要理解这是个箱子来做这个事情,而且就算是婴儿之前没有见过箱子也能知道这是一个物体。
运用Common Fate来分割视频
这个定律启发了基于运动的无监督分割。然而,Common Fate并不是物体性质的可靠指标:关节可动 (articulated) /可变形物体 (deformable objects) 的一些part可能不以相同速度移动,而物体的阴影/反射 (shadows/reflections) 始终随物体移动,但并非其组成部分。
举个例子,下面这个人的腿和身子的运动是不同的(Optical Flow可视化出来颜色不同)。这很常见,毕竟人有关节嘛 (articulated),要是这个处理不了的话,很多视频都不能分割了。然而很多baseline是处理不了这点的(例如AMD+和OCLR),他们把人分割成了几个部分。
还有就是影子和反射,比如上面这只天鹅,它的倒影跟它的运动是一致的(Optical Flow可视化颜色一样),所以之前的方法认为天鹅跟倒影是一个物体。很多视频里是有这类现象的(毕竟大太阳下物体都有个影子嘛),如果这个处理不了的话,很多视频也不能分割了。
那怎么解决?放松。Relax.
长话短说,那我们的方法是怎么解决这个问题的呢?无监督学习的一个特性是利用神经网络自己内部的泛化和拟合能力进行学习。既然Common Fate有自己的问题,那么我们没有必要强制神经网络去拟合Common Fate。于是我们提出了Relaxed Common Fate,通过一个比较弱的学习方式让神经网络真正学到物体的特性而不是noise。
具体来说,我们的方法认为物体运动由两部分组成:物体总体的piecewise-constant motion (也就是Common Fate)和物体内部的segment motion。比如你看下图这个舞者,他全身的运动就可以被理解成piecewise-constant motion来建模,手部腿部这些运动就可以作为residual motion进行拟合,最后合并成一个完整的flow,跟RAFT生成的flow进行比较来算loss。我们用的RAFT是用合成数据(FlyingChairs和FlyingThings)进行训练的,不需要人工标注。
Relaxed Common Fate
首先我们使用一个backbone来进行特征提取,然后通过一个简单的full-convolutional network获得Predicted Masks $\hat{M}$(下图里的下半部分),和一般的分割框架是一样的,也可以切换成别的框架。
那我们怎么优化这些Masks呢?我们先提取、合并两帧的特征,放入一个residual flow prediction head来获得Residual Flow $\hat{R}$ (下图里的上半部分)。
然后我们对RAFT获得的Flow用Predicted Masks $\hat{M}$进行Guided Pooling,获得一个piecewise-constant flow,再加上预测的residual flow,就是我们的flow prediction了。最后把flow prediction和RAFT获得的Flow的差算一个L1 norm Loss进行优化,以此来学习segmentation。
在测试的时候,只有Predicted Masks $\hat{M}$ 是有用的,其他部分是不用的。
这里的Residual Flow会尽量初始化得小一些,来鼓励先学piecewise-constant的部分(有点类似ControlNet),再慢慢学习residual部分。
引入Appearance信息来帮助无监督视频分割
光是Relaxed Common Fate就能在DAVIS上相对baseline提5%了,但这还不够。前面说Relaxed Common Fate的只用了motion而没有使用appearance信息。
让我们再次回到上面这个例子。这个舞者的手和身子是一个颜色,然而AMD+直接把舞者的手忽略了。下面这只天鹅和倒影明明在appearance上差别这么大,却在motion上没什么差别。如果整合appearance和motion,是不是能提升分割质量呢?
因此我们引入了Appearance 来进行进一步的监督。在学习完motion信息之后,我们直接把取得的Mask进行两步优化:一个是low-level的CRF refinement,强调颜色等细节一致的地方应该属于同一个mask(或背景),一个是semantic constraint,强调Unsupervised Feature一直的地方应该属于同一个mask。
把优化完的mask再和原mask进行比较,计算L2 Loss,再更新神经网络。这样训练的模型的无监督分割能力可以进一步提升。具体细节欢迎阅读原文。
无监督调参
很多无监督方法都需要使用有标注的数据集来调参,而我们的方法提出可以利用前面说的motion和appearance的一致性来进行调参。简单地说,motion学习出的mask在appearance上不一致代表这个参数可能不是最优的。具体方法是在Unsupervised Feature上计算Normalized Cuts (但是不用算出最优值),Normalized Cuts越小越代表分割效果好。原文里面对此有详细描述。
方法效果
无论是否有Post-processing,我们的方法在三个视频分割数据集上都有很大提升,在STv2上更是提升了12%。
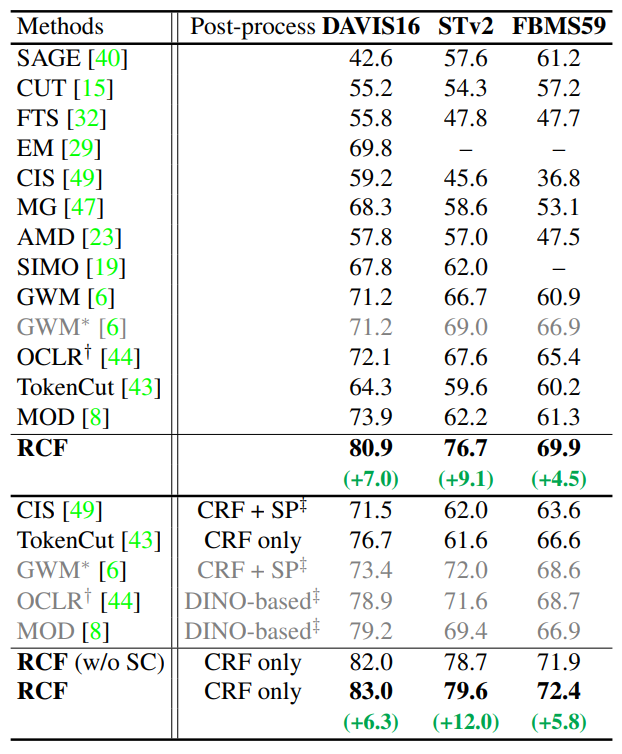
Ablation可以看出Residual pathway (Relaxed Common Fate)的贡献是最大的,其他部分总计贡献了11.9%的增长。
Visualizations
总结
这篇CVPR 2023文章研究了完全不需要标注的视频物体分割。通过Relaxed Common Fate来利用motion信息,再通过改进和利用appearance信息来进一步优化,RCF模型在DAVIS16/STv2/FBMS59上提升了7/9/5%。文章里还提出了不需要标注的调参方法。代码和模型已公开可用。
CVPR 2023 | RCF:完全无监督的视频物体分割的更多相关文章
- 【转】有监督训练 & 无监督训练
原文链接:http://m.blog.csdn.net/article/details?id=49591213 1. 前言 在学习深度学习的过程中,主要参考了四份资料: 台湾大学的机器学习技法公开课: ...
- 转:Deep learning系列(十五)有监督和无监督训练
http://m.blog.csdn.net/article/details?id=49591213 1. 前言 在学习深度学习的过程中,主要参考了四份资料: 台湾大学的机器学习技法公开课: Andr ...
- DeepMind爆出无监督表示学习模型BigBiGAN,GAN之父点赞!
[导读]今天,DeepMind爆出一篇重磅论文,引发学术圈热烈反响:基于最强图像生成器BigGAN,打造了BigBiGAN,在无监督表示学习和图像生成方面均实现了最先进的性能!Ian Goodfell ...
- 图片质量评估论文 | 无监督SER-FIQ | CVPR2020
文章转自:同作者微信公主号[机器学习炼丹术].欢迎交流,共同进步. 论文名称:SER-FIQ: Unsupervised Estimation of Face Image Quality Based ...
- 学习笔记CB008:词义消歧、有监督、无监督、语义角色标注、信息检索、TF-IDF、隐含语义索引模型
词义消歧,句子.篇章语义理解基础,必须解决.语言都有大量多种含义词汇.词义消歧,可通过机器学习方法解决.词义消歧有监督机器学习分类算法,判断词义所属分类.词义消歧无监督机器学习聚类算法,把词义聚成多类 ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- 将句子表示为向量(上):无监督句子表示学习(sentence embedding)
1. 引言 word embedding技术如word2vec,glove等已经广泛应用于NLP,极大地推动了NLP的发展.既然词可以embedding,句子也应该可以(其实,万物皆可embeddin ...
- 使用GAN进行异常检测——可以进行网络流量的自学习哇,哥哥,人家是半监督,无监督的话,还是要VAE,SAE。
实验了效果,下面的还是图像的异常检测居多. https://github.com/LeeDoYup/AnoGAN https://github.com/tkwoo/anogan-keras 看了下,本 ...
- 无监督︱异常、离群点检测 一分类——OneClassSVM
OneClassSVM两个功能:异常值检测.解决极度不平衡数据 因为之前一直在做非平衡样本分类的问题,其中如果有一类比例严重失调,就可以直接用这个方式来做:OneClassSVM:OneClassSV ...
- UFLDL深度学习笔记 (三)无监督特征学习
UFLDL深度学习笔记 (三)无监督特征学习 1. 主题思路 "UFLDL 无监督特征学习"本节全称为自我学习与无监督特征学习,和前一节softmax回归很类似,所以本篇笔记会比较 ...
随机推荐
- SQL Case条件判断语句
问题描述:在表中取到一些值做出判断,配合监控监测一些表中的数据.使用select case when if 来做条件查询判断 CASE 表达式遍历条件并在满足第一个条件时返回一个值(类似于 if-th ...
- YII2.0框架分页
这篇文章主要介绍了Yii分页用法,以实例形式详细分析了比较常见的几种分页方法及其应用特点,非常具有实用价值,需要的朋友可以参考下: 在这里我主要联查的 book 表和 book_press 两张表进行 ...
- 【Spring5】框架新功能
Spring5框架新功能 整个Spring5框架的代码基于Java8,运行时兼容JDK9,许多不建议使用的类和方法在代码库中删除. Spring5自带了通用的日志封装:log4j2 已经移除了log4 ...
- 帝国cms随机sql语句,mysql高效的随机查询
select * from AppleStorewhere rand()<0.015limit 100;
- class(类)和构造函数(原型对象)
构造函数和class的关系,还有面向对象和原型对象,其实很多人都会很困惑这些概念,这是第二次总结这些概念了,之前一次,没有class类,其实了解了构造函数,class也就很容易理解了 一. 构造函数和 ...
- Prism Sample 11-UsingDelegateCommands
本例的知识点,全在ViewModel中,看代码: 1 public class MainWindowViewModel : BindableBase 2 { 3 private bool _isEna ...
- 文心一言 VS chatgpt (12)-- 算法导论3.1 6~7题
六.证明:一个算法的运行时间为θ(g(n))当且仅当其最坏情况运行时间为O(g(n)),且其最好情况运行时间为Ω(g(n)) . 文心一言: chatgpt: 要证明「一个算法的运行时间为θ(g(n) ...
- 2023-02-24:请用go语言调用ffmpeg,解码mp4文件并保存为YUV420SP格式文件,采用YUV420P转YUV420SP的方式。
2023-02-24:请用go语言调用ffmpeg,解码mp4文件并保存为YUV420SP格式文件,采用YUV420P转YUV420SP的方式. 答案2023-02-24: 使用 github.com ...
- 2022-11-26:给定一个字符串s,只含有0~9这些字符 你可以使用来自s中的数字,目的是拼出一个最大的回文数 使用数字的个数,不能超过s里含有的个数 比如 : 39878,能拼出的最大回文数是
2022-11-26:给定一个字符串s,只含有0~9这些字符 你可以使用来自s中的数字,目的是拼出一个最大的回文数 使用数字的个数,不能超过s里含有的个数 比如 : 39878,能拼出的最大回文数是 ...
- 2022-05-02:给定一个数组arr,一个正数num,一个正数k, 可以把arr中的某些数字拿出来组成一组,要求该组中的最大值减去最小值<=num, 且该组数字的个数一定要正好等于k, 每个数字只
2022-05-02:给定一个数组arr,一个正数num,一个正数k, 可以把arr中的某些数字拿出来组成一组,要求该组中的最大值减去最小值<=num, 且该组数字的个数一定要正好等于k, 每个 ...