不可复制的PDF转成双层可复制PDF
有些PDF是通过扫描或者虚拟打印机生成的,这些PDF不可复制里边的内容
市面上的工具一般都是收费或者有水印,所以就萌生了自己搞一个的想法:
使用了以下三个开源库
- PdfiumViewer PDF预览及可编辑PDF的提取
- PDFsharp 生成PDF
- PaddleSharp 对图片OCR识别
大概思路是:
用PdfiumViewer 渲染显示,并转PDF为图片;
使用PaddleSharp 对提取图片的内容及bbox坐标;
把坐标根据缩放比转成相对于PDF的坐标,并使用PDFsharp 重新生成PDF,如需要保持原有格式需要把1转成的图片重新回写到生成的pdf,文字层为ocg层;
实现双层pdf的效果;
读取PDF到到内存流:
private PdfDocument OpenDocument(string fileName)
{
try
{
return PdfDocument.Load(this, new MemoryStream(File.ReadAllBytes(fileName)));
}
catch (Exception ex)
{
MessageBox.Show(this, ex.Message, Text, MessageBoxButtons.OK, MessageBoxIcon.Error);
return null;
}
}
PDF转图片:
//图片dpi要相对大些,这样ocr识别的更清晰
int dpiX = 96 * 5;
int dpiY = 96 * 5;
var pdfWidth = (int)document.PageSizes[page].Width * 4 / 3;
var pdfHeight = (int)document.PageSizes[page].Height * 4 / 3;
var rotate = PdfRotation.Rotate0;
var flags = PdfRenderFlags.Annotations | PdfRenderFlags.CorrectFromDpi;
using (var image = document.Render(page, pdfWidth, pdfHeight, dpiX, dpiY, rotate, flags)){}
OCR识别:
byte[] sampleImageData = ImageToByte(image);
FullOcrModel model = LocalFullModels.ChineseV3;
using (PaddleOcrAll all = new PaddleOcrAll(model, PaddleDevice.Mkldnn())
{
AllowRotateDetection = true, /* 允许识别有角度的文字 */
Enable180Classification = false, /* 允许识别旋转角度大于90度的文字 */
})
{
// Load local file by following code:
using (Mat src = Cv2.ImDecode(sampleImageData, ImreadModes.Color))
{
PaddleOcrResult result = all.Run(src);
return result;
}
}
图片转成流:
private byte[] ImageToByte(System.Drawing.Image image)
{
MemoryStream ms = new MemoryStream();
if (image == null)
return new byte[ms.Length];
image.Save(ms, System.Drawing.Imaging.ImageFormat.Png);
byte[] BPicture = new byte[ms.Length];
BPicture = ms.GetBuffer();
return BPicture;
}
转换bbox坐标到PDF坐标:bbox坐标是相对于图片的坐标,可以
private System.Drawing.RectangleF ConvertToPDFSize(System.Drawing.RectangleF rectangle, float dpiX, float dpiY, PdfRotation rotate, PdfRenderFlags flags)
{
var width = rectangle.Width;
var height = rectangle.Height;
var x = rectangle.X;
var y = rectangle.Y;
if ((flags & PdfRenderFlags.CorrectFromDpi) != 0)
{
width = (width / dpiX * 72);
height = (height / dpiY * 72);
x = (x / dpiX * 72);
y = (y / dpiY * 72);
}
return new RectangleF(x, y, width, height);
}
bbox坐标框选示例:
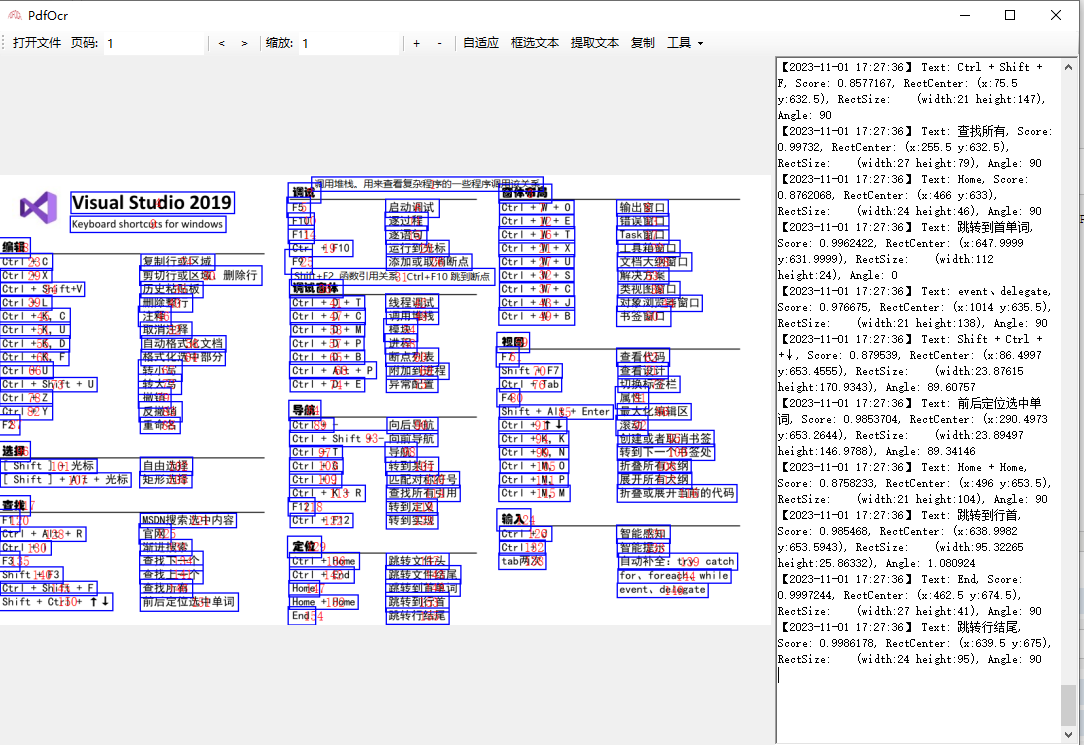
由于OCR的限制:转双层pdf只能在x64系统运行,不适用OCR可运行x86和x64,
工具功能:
- 可提取和框选提取可复制和不可复制pdf;
- 可转换不可复制的pdf为双层可复制pdf;
- 可转换不可复制的pdf为可复制pdf;
- 加载图片并提取标注提取内容;
直接下载地址:
https://cloud.189.cn/web/share?code=MZvMb2ZNRbMn(访问码:y9st)
也可按照下放代码自己编译使用,遵循MIT协议
欢迎Start、PR
源码地址:https://github.com/1000374/HM.PdfOcr
不可复制的PDF转成双层可复制PDF的更多相关文章
- PDF转换成DXF文件?PDF转DXF的操作方法
在CAD工作中,经常就需要将绘制完成的图纸文件的格式进行转换,那怎么将PDF文件转换成DXF格式的呢?具体要怎么来进行操作呢?本编教程小编就来教教大家具体操作方法,具体操作如下: 一.工具转换 推荐指 ...
- C# 复制PDF页面到另一个PDF文档
C# 复制PDF页面到另一个PDF文档 有时候我们可能有这样一个需求,那就是把PDF页面从一个PDF文档复制到另一个PDF文档中.由于PDF文档并不像word文档那样好编辑,因此复制也相对没有那么容易 ...
- ABBYY把pdf转换成word的方法
有时候我们在网上下载的资料文献是PDF格式文档,遇到喜欢的字句总忍不住想要收藏起来,但是PDF文档不同于普通的Word文档可以直接进行复制粘贴,需要下载安装相关的编辑工具,才能对文字内容进行编辑.倒不 ...
- 复制pdf文字出来是乱码
PDF文件复制文本为乱码 - longzhinuhou的博客 - CSDN博客 https://blog.csdn.net/longzhinuhou/article/details/83758966 ...
- 如何使用Adobe Reader复制PDF文档上的文字
PDF文档大家常用,但是有没有简单的方法能够提取PDF文档上的文字,然后使用呢?除了将PDF转换成Word,这里介绍一种更为简单实用的方法复制PDF文本文字,Adobe Reader是大家都常用的PD ...
- pdf转换成文本解决格式不统一问题
pdf转换成文本解决格式不统一问题 懒得调OCR服务了,所以快速解决的方法是: pdf转png:https://pdf2png.com/zh/ png转统一格式pdf:adobe acrobat自带增 ...
- C#pdf 切割成图片
引用 using Ghostscript.NET;using Ghostscript.NET.Rasterizer; 需要安装 exe文件 public static GhostscriptVersi ...
- pdf 切割成圖片的方法
/// <summary> /// 将PDF文档转换为图片的方法 /// </summary> /// <param na ...
- Python 将pdf转换成txt(不处理图片)
上一篇文章中已经介绍了简单的python爬网页下载文档,但下载后的文档多为doc或pdf,对于数据处理仍然有很多限制,所以将doc/pdf转换成txt显得尤为重要.查找了很多资料,在linux下要将d ...
- 如何用ABBYY把PDF转换成PPT
在电子科技迅速发展的今天,文件格式转换并不是什么稀罕事,因为现在都是电子化办公,出现很多文件格式,但是不同的场合需要的格式不同,所以常常需要进行文件格式的转换.PDF转换成PPT也是众多文件格式转换中 ...
随机推荐
- Hexo博客Next主题添加粒子时钟特效
博客应用canvas粒子时钟的操作步骤: 在\themes\next\layout\_custom\目录下,新建clock.swig文件,内容如下: <div style="" ...
- PerfView专题 (第十五篇): 如何洞察 C# 中的慢速方法
一:背景 1. 讲故事 在 dump 分析旅程中,经常会遇到很多朋友反馈一类问题,比如: 方法平时都执行的特别快,但有时候会特别慢,怎么排查? 我的方法第一次执行特别慢,能看到慢在哪里吗? 相信有朋友 ...
- MASA Blazor中MSwitch如何实现二次确认
<MSwitch @bind-Value="switch" Readonly OnClick="OnClick"> </MSwitch> ...
- linux下的venv使用
首先安装该模块: sudo apt-get install python3-venv 之后创建用于存储工程的文件夹 mkdir [filename] 创建环境: python3 -m venv ven ...
- 华为ensp配置静态路由,三路由,三pc
华为ensp配置静态路由 目的:使pc1,pc2,pc3能相互ping通 1,tuop图的搭建 1,如图所示:先搭建好设备的通讯关系,在标记好每台设备对应的,ip地址和网关. 2,pc的网关,与ip地 ...
- [mysql]定制封装MySQL的docker镜像
前言 基于MySQL的原版镜像做一些个性化配置修改,封装/etc/my.cnf文件到镜像中,并且支持通过环境变量修改innodb_buffer_pool_size.server_id以及自动配置inn ...
- uniapp封装接口
1 为什么需要封装接口 封装接口是为了提高开发效率.增加代码复用性和提升可维护性.下面对这些原因进行详细解释: 1.1 开发效率 开发效率:减少代码量,简化调用过程 通过封装接口,可以将一些常见的操作 ...
- xfs文件系统核心架构介绍
版权声明:本文为CSDN博主「瞧见风」的原创文章,遵循CC 4.0 BY-SA版权协议原文链接:https://blog.csdn.net/scaleqiao/article/details/5209 ...
- 为 VitePress 网站添加 RSS 订阅支持
省流:使用 vitepress-plugin-rss 这个插件 前言 在看许多个人博客站点的时候,右上角总会有个RSS订阅的标志 恰好我的博客也是基于 VitePress 搭建的,就想看看能不能也实现 ...
- python 运行环境变为 pytest in (for) xxx.py原因
因为本人的自定义函数名称开头为test,在.py文件内我用了unittest框架,所以环境随着变化了. 修改回去很简单,只要不使用test开头或者换个文件夹.