06 Word2Vec模型(第一个专门做词向量的模型,CBOW和Skip-gram)
神经网络语言模型(NNLM)--》为了预测下一个词
NNLM()--》预测下一个词
神经网络+语言模型:用神经网络去解决和人说话有关的两个任务的一个东西
softmax(w2(tanh((w1x+b1)))+b2)
得到一个副产品(词向量)
Q 矩阵,对于任何一个独热编码的词向量都可以通过 Q 矩阵得到新的词向量
- 可以转换维度
- 相似词之间的词向量之间也有了关系
Word2Vec --》 为了得到词向量
神经网络语言模型--》主要目的就是为了得到词向量
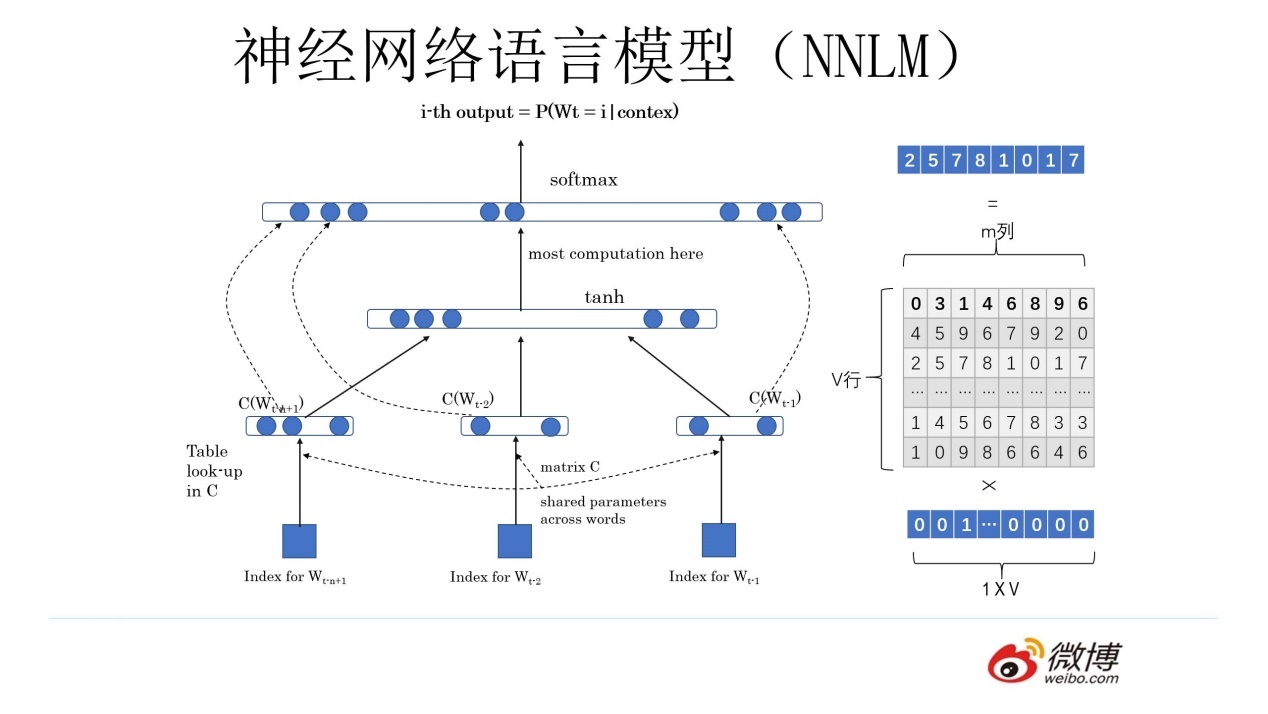

NNLM 和 Word2Vec 基本一致(一模一样),不考虑细节,网络架构就是一模一样
CBOW
给出一个词的上下文,得到这个词
“我是最_的Nick”
“帅” \(w_t\)
Skip-gram
给出一个词,得到这个词的上下文
“帅”
“我是_的Nick”
NNLM 和 Word2Vec 的区别
NNNL --》 重点是预测下一词,双层感知机softmax(w2(tanh((w1(xQ)+b1)))+b2)
Word2Vec --》 CBOW 和 Skip-gram 的两种架构的重点都是得到一个 Q 矩阵,softmax(w1 (xQ) +b1)
- CBOW:一个老师告诉多个学生,Q 矩阵怎么变
- Skip:多个老师告诉一个学生,Q 矩阵怎么变
Word2Vec的缺点
Q 矩阵的设计

00010 代表 apple × Q = 10,12,19
apple(苹果,)
假设数据集里面的 apple 只有苹果这个意思,没有这个意思(训练)
(测试,应用)10,12,19 apple, 无法表示这个意思
词向量不能进行多意 ---》 ELMO
06 Word2Vec模型(第一个专门做词向量的模型,CBOW和Skip-gram)的更多相关文章
- 词向量-LRWE模型
上一节,我们介绍利用文本和知识库融合训练词向量的方法,如何更好的融合这些结构化知识呢?使得训练得到的词向量更具有泛化能力,能有效识别同义词反义词,又能学习到上下文信息还有不同级别的语义信息. 基于上述 ...
- 词向量-LRWE模型-更好地识别反义词同义词
上一节,我们介绍利用文本和知识库融合训练词向量的方法,如何更好的融合这些结构化知识呢?使得训练得到的词向量更具有泛化能力,能有效识别同义词反义词,又能学习到上下文信息还有不同级别的语义信息. 基于上述 ...
- 对词向量模型Word2Vec和GloVe的理解
Word2Vec Word2Vec 是 google 在2013年提出的词向量模型,通过 Word2Vec 可以用数值向量表示单词,且在向量空间中可以很好地衡量两个单词的相似性. 简述 我们知道,在使 ...
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 自然语言处理与词嵌入
一.词汇表征 首先回顾一下之前介绍的单词表示方法,即one hot表示法. 如下图示,"Man"这个单词可以用 \(O_{5391}\) 表示,其中O表示One_hot.其他单词同 ...
- 基于word2vec训练词向量(一)
转自:https://blog.csdn.net/fendouaini/article/details/79905328 1.回顾DNN训练词向量 上次说到了通过DNN模型训练词获得词向量,这次来讲解 ...
- 在Keras模型中one-hot编码,Embedding层,使用预训练的词向量/处理图片
最近看了吴恩达老师的深度学习课程,又看了python深度学习这本书,对深度学习有了大概的了解,但是在实战的时候, 还是会有一些细枝末节没有完全弄懂,这篇文章就用来总结一下用keras实现深度学习算法的 ...
- 词向量(one-hot/SVD/NNLM/Word2Vec/GloVe)
目录 词向量简介 1. 基于one-hot编码的词向量方法 2. 统计语言模型 3. 从分布式表征到SVD分解 3.1 分布式表征(Distribution) 3.2 奇异值分解(SVD) 3.3 基 ...
- word2vec预训练词向量
NLP中的Word2Vec讲解 word2vec是Google开源的一款用于词向量计算 的工具,可以很好的度量词与词之间的相似性: word2vec建模是指用CBoW模型或Skip-gram模型来计算 ...
- 词向量模型word2vector详解
目录 前言 1.背景知识 1.1.词向量 1.2.one-hot模型 1.3.word2vec模型 1.3.1.单个单词到单个单词的例子 1.3.2.单个单词到单个单词的推导 2.CBOW模型 3.s ...
随机推荐
- 【Hearts Of Iron IV】钢铁雄心4 安装笔记
一.解决Steam购买游戏和下载问题 我可能是正版受害者 Steam平台这个游戏本体是购买锁国区的 然后在淘宝上面买激活码激活的 都激活过了的Key,所以放出来也无所谓了 钢铁雄心4学员版本体:7B0 ...
- 【Java-GUI】04 菜单
--1.菜单组件 相关对象: MenuBar 菜单条 Menu 菜单容器 PopupMenu 上下文菜单(右键弹出菜单组件) MenuItem 菜单项 CheckboxMenuItem 复选框菜单项 ...
- 【FastDFS】环境搭建 01 跟踪器和存储节点
FastDFS:分布式文件系统 它对文件进行管理,功能包括:文件存储.文件同步.文件访问(文件上传.文件下载)等,解决了大容量存储和负载均衡的问题. 特别适合以文件为载体的在线服务,如相册网站.视频网 ...
- (摘抄) 源码分析multiprocessing的Value Array共享内存原理
原文地址: http://xiaorui.cc/archives/3290 ============================================================ 摘 ...
- C#开发的全屏图片切换效果应用 - 开源研究系列文章 - 个人小作品
这天无聊,想到上次开发的图片显示软件< PhotoNet看图软件 >,然后想到开发一个全屏图片切换效果的应用,类似于屏幕保护程序,于是就写了此博文.这个应用比较简单,主要是全屏切换换图片效 ...
- Java静态相关问题
问题1: public class Demo01_StaticTest { private static Demo01_StaticTest st = new Demo01_StaticTest(); ...
- mybatis坑之数字字符串比对
在mybatis开发过程中有需要在sql中判断查询哪张表,如下sql: SELECT a.tag_name, a.tag_id, count( 0 ) AS base_total FROM mm_dd ...
- Camera | 1.Camera基础知识
一口君最近在玩瑞芯微的板子,之前写了几篇基于瑞芯微的文章,大家可以学习一下. <瑞芯微rk356x板子快速上手> <Linux驱动|rtc-hym8563移植笔记> <L ...
- Jetpack架构组件学习(5)——Hilt 注入框架使用
原文: Jetpack架构组件学习(5)--Hilt 注入框架使用-Stars-One的杂货小窝 本篇需要有Kotlin基础知识,否则可能阅读本篇会有所困难! 介绍说明 实际上,郭霖那篇文章已经讲得比 ...
- 记一次list集合优化
已知某个列表List1有2000条数据,但是因为这个列表的某个字段要从另一个表查询,所以根据一个关联的查询条件查出来的另一个List2有将近75000条数据,然后需要先循环第一个List1,然后循环里 ...