大数据场景下Volcano高效调度能力实践
摘要:本篇文章将会从Spark on Kubernetes 发展历程以及工作原理,以及介绍一下Spark with Volcano,Volcano如何能够帮助 Spark运行地更高效。
Spark on Kubernetes
我们来看Spark on Kubernetes的背景。其实Spark在从2.3这个版本开始之后,就已经支持了Kubernetes native,可以让Spark的用户可以把作业运行在Kubernetes上,用Kubernetes去管理资源层。在2.4版本里增加了client mode和Python语言的支持。而在今年的发布的Spark 3.0里面,对Spark on Kubernetes这一方面也增加了很多重要的特性,增加动态资源分配、远端shuffle service以及 Kerberos 支持等。
Spark on Kubernetes的优势:
1)弹性扩缩容
2)资源利用率
3)统一技术栈
4)细粒度的资源分配
5)日志和监控
Spark submit 工作原理
Spark对于Kubernetes的支持,最早的一种工作方式是通过 Spark官方的spark submit方式去支持,Clinet通过Spark submit提交作业,然后spark driver会调用apiserver的一些api去申请创建 executor,executor都起来之后,就可以执行真正的计算任务,之后会做日志备份。
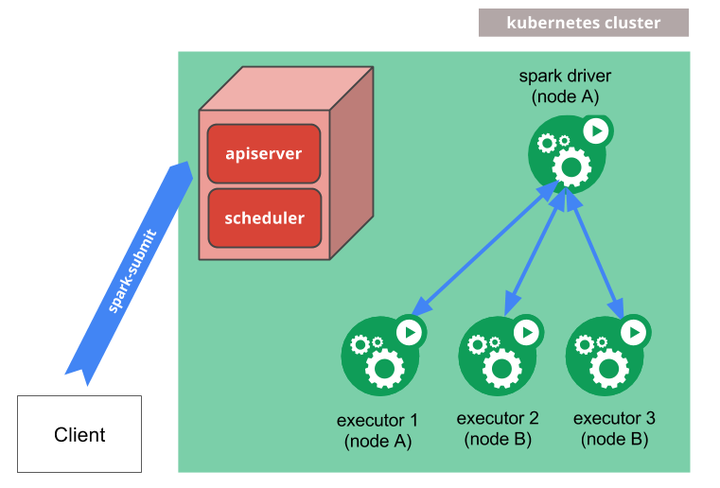
这种方式有一个优势是,传统的 Spark用户切换到这种方式之后用户体验改变大。但也存在缺少作业周期管理的缺陷。
Spark-operator 工作原理
第二种Spark on Kubernetes的使用方式就是operator。operator是更Kubernetes的方式,你看他的整个作业提交,先是yaml文件通过kubectl提交作业,在这里面它有自己的crd,即SparkApplication,Object。创建了SparkApplication之后, Controller可以watch到这些资源的创建,后边流程其实是复用的第一种工作模式,但是通过这种模式,做的更完善的一些。
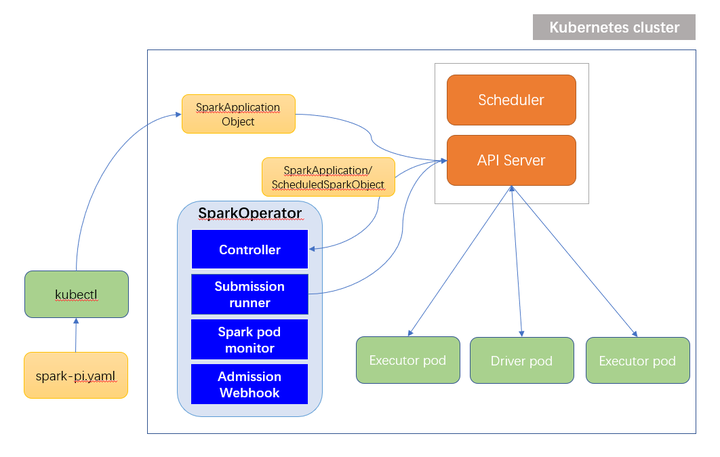
相对于第一种方式来讲,这里的Controller可以维护对象生命周期,可以watch spark driver的状态,并更新application的状态,是一个更完善的解决方案。
这两种不同的使用方式使用是各有优势,不少的公司两种方式都有使用。这一块在官网也有介绍。
Spark with Volcano
Volcano对于上面提到两种工作方式都进行了集成和支持。这个链接是我们维护的 Spark开源代码仓库:https://github.com/huawei-cloudnative/spark/tree/spark-2.4-volcano-0.1
在这里面Volcano做的事情其实也很简单,你看整个提交的过程,首先是通过spark submit提交作业,提交作业时会创建一个podgroup,podgroup包含了用户配置的一些调度相关的信息。它的yaml文件大家可以看到,页面右边这个部分,增加了driver和executor两个角色。
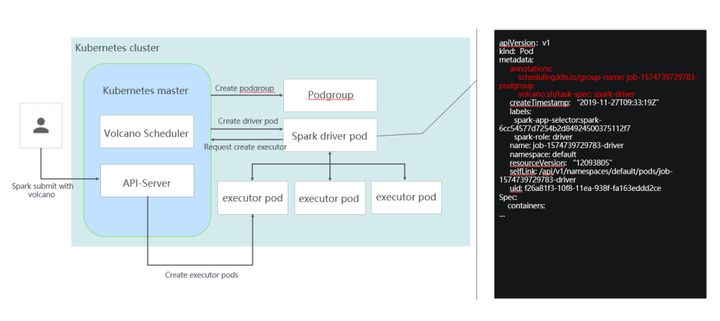
Volcano 队列
队列其实我们在第一堂和第二堂课里面也讲到了。因为Kubernetes里面没有队列的支持,所以它在多个用户或多个部门在共享一个机器的时候资源没办法做共享。但不管在HPC还是大数据领域里,通过队列进行资源共享都是基本的需求。
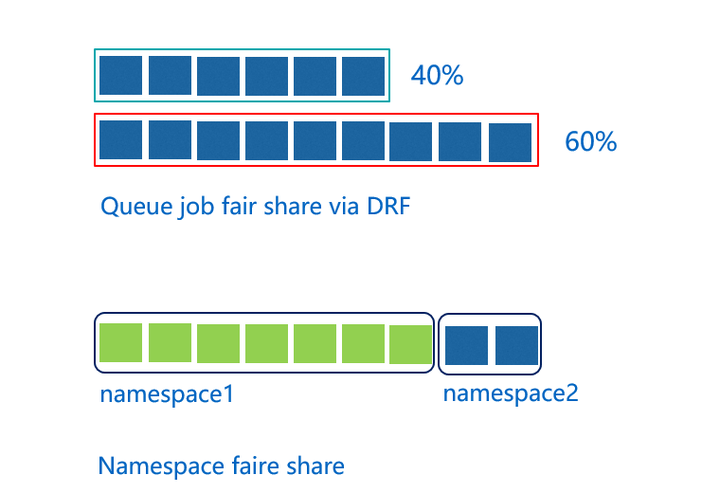
在通过队列做资源共享时,我们提供了多种机制。图最上面的这种,这里面我们创建两个队列,通过这两个队列去共享整个集群的资源,一个队列给他分40%的咨询资源,另一个给他分60%的资源,这样的话就可以把这两个不同的队列映射到不同的部门或者是不同的项目各自使用一个队列。这在一队列里,资源不用的时候,可以给另外一个队列里面的作业去使用。下面讲的是两个不同的namespace之间的资源平衡。Kubernetes里当两个不同的应用系统的用户都去提交作业时,提交作业越多的用户,他获得的集群的资源会越多,所以在这里面基于namespace,我们进行公平的调度,保证namespace之间可以按照权重分享集群的资源。
Volcano: Pod delay creation
之前介绍这个场景的时候,有些同学反映没有太听懂,所以我加了几页PPT扩展一下。
举个例子,我们在做性能测试的时候,提交16个并发的作业,对于每个作业来讲,它的规格是1 driver+4 executor,整个集群总共有4台机器16个核,这样的一个情况。
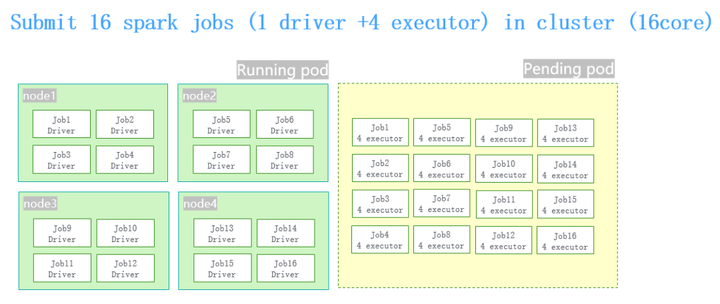
同时提交16个spark job的时候,driver pod的创建和executor pod的创建之间有一个时间差。因为有这个时间差,当16个spark的job跑起来之后把整个机群全部占满了,就会导致同时提交并发量特别大作业的时候,整个集群卡死。
为了解决这种情况,我们做了这样的事情。
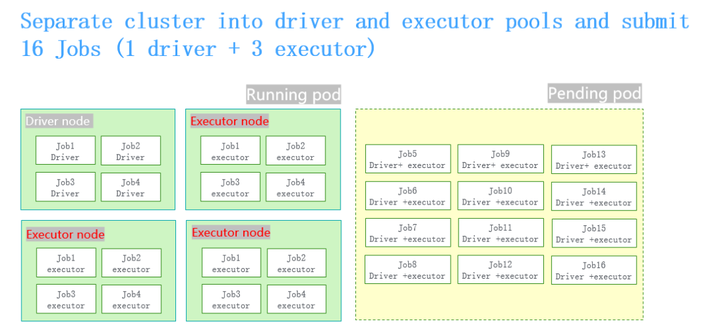
让一个节点专门去跑driver pod。其他三个节点专门去跑executor pod,防止driver pod占用更多的资源,就可以解决被卡死的问题。
但也有不好的地方,这个例子里节点是1:3的关系。在真实的场景下,用户的作业的规格都是动态的, 而这种分配是通过静态的方式去划分,没办法跟真实的业务场景里动态的比例保持一致,总是会存在一些资源碎片,会有资源的浪费。
因此,我们增加了Pod delay creation的功能,增加这个功能之后不需要对node去做静态的划分,整个还是4个节点,在16个作业提上来的时候,对于每个作业增加了podgroup的概念。Volcano的调度器会根据提上来作业的podgroup进行资源规划。

这样就不会让过多的作业会提交上来。不但可以把4个节点里面所有的资源全部用完,而且没有任何的浪费,在高并发的场景下控制pod创建的节奏。它的使用也非常简单,可以按照你的需求配资源量,解决高并发的场景下运行卡死或者运营效率不高的情况。
Volcano: Spark external shuffle service
我们知道原来的Spark已经很完善了,有很多特别好用的功能,Volcano保证了迁移到Kubernetes上之后没有大的功能缺失:
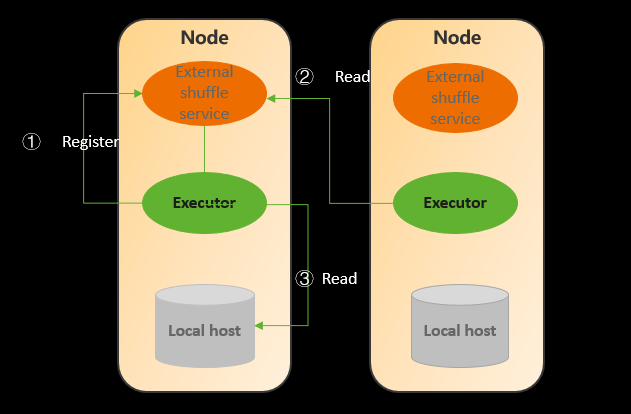
1)ESS以daemonset的方式部署在每个节点
2)Shuffle本地写Shuffle数据,本地、远端读shuffle数据
3)支持动态资源分配
大数据场景下Volcano高效调度能力实践的更多相关文章
- 看大数据时代下的IT架构(1)业界消息队列对比
一.MQ(Message Queue) 即 消息队列,一般用于应用系统解耦.消息异步分发,能够提高系统吞吐量.MQ的产品有很多,有开源的,也有闭源,比如ZeroMQ.RabbitMQ. ActiveM ...
- c#中@标志的作用 C#通过序列化实现深表复制 细说并发编程-TPL 大数据量下DataTable To List效率对比 【转载】C#工具类:实现文件操作File的工具类 异步多线程 Async .net 多线程 Thread ThreadPool Task .Net 反射学习
c#中@标志的作用 参考微软官方文档-特殊字符@,地址 https://docs.microsoft.com/zh-cn/dotnet/csharp/language-reference/toke ...
- Pulsar 联合 TiDB 推出大数据场景数据应用分析解决方案
方案概述 大数据时代,各类应用对消息解决方案的要求不仅仅是数据的流动,而是要在持续增长的服务和应用中传输海量数据,进行智能的处理和分析,帮助业务做出更加精准的决策. Pulsar 与 TiDB 联合解 ...
- R You Ready?——大数据时代下优雅、卓越的统计分析及绘图环境
作者按:本文根据去年11月份CSDN举办的“大数据技术大会”演讲材料整理,最初发表于2012年2月期<程序员>杂志. 0 R 的安装
- 柯南君:看大数据时代下的IT架构(5)消息队列之RabbitMQ--案例(Work Queues起航)
二.Work Queues(using the Java Client) 走起 在第上一个教程中我们写程序从一个命名队列发送和接收消息.在这一次我们将创建一个工作队列,将用于分发耗时的任务在多个工 ...
- [转帖]etcd 在超大规模数据场景下的性能优化
etcd 在超大规模数据场景下的性能优化 阿里系统软件技术 2019-05-27 09:13:17 本文共5419个字,预计阅读需要14分钟. http://www.itpub.net/2019/ ...
- 大数据时代下EDM邮件营销的变革
根据研究,今年的EDM邮件营销的邮件发送量比去年增长了63%,许多方法可以为你收集用户数据,这些数据可以帮助企业改善自己在营销中的精准度,相关性和执行力. 最近的一项研究表明,中国800强企业当中超过 ...
- etcd 在超大规模数据场景下的性能优化
作者 | 阿里云智能事业部高级开发工程师 陈星宇(宇慕) 概述 etcd是一个开源的分布式的kv存储系统, 最近刚被cncf列为沙箱孵化项目.etcd的应用场景很广,很多地方都用到了它,例如kuber ...
- 柯南君:看大数据时代下的IT架构(4)消息队列之RabbitMQ--案例(Helloword起航)
柯南君:看大数据时代下的IT架构(4)消息队列之RabbitMQ--案例(Helloword起航) 二.起航 本章节,柯南君将从几个层面,用官网例子讲解一下RabbitMQ的实操经典程序案例,让大家重 ...
- 柯南君:看大数据时代下的IT架构(3)消息队列之RabbitMQ-安装、配置与监控
柯南君:看大数据时代下的IT架构(3)消息队列之RabbitMQ-安装.配置与监控 一.安装 1.安装Erlang 1)系统编译环境(这里采用linux/unix 环境) ① 安装环境 虚拟机:VMw ...
随机推荐
- umicv cv-summary1-全连接神经网络模块化实现
全连接神经网络模块化实现 Linear与Relu单层实现 LossLayer实现 多层神经网络 不同梯度下降方法 Dropout层 今天这篇博文针对Assignment3的全连接网络作业,对前面学习的 ...
- 长程 Transformer 模型
Tay 等人的 Efficient Transformers taxonomy from Efficient Transformers: a Survey 论文 本文由 Teven Le Scao.P ...
- CSP 2022 游寄
Day -2147483648 官网有了通知,但选手注册不知为何坏掉了: 先开坑: Day -大概两个月 注册了,但老师还没给我审核呜呜呜 第一轮 早上 早上起床就直接来机房了,不用跑操欸嘿. 上午 ...
- Android-Java-反序列化JSON
import com.google.gson.Gson; import com.google.gson.reflect.TypeToken; String jsonStr= WebAPIOperato ...
- IPv4:根据CIDR显示地址范围
最近遇到一个很有意思的点,于是就记录下来. CIDR一般是由IP地址和子网掩码组成,即 IP地址/子网掩码 格式. 子网掩码表示前面地址中的前多少位,为网络位,后面部分代表主机部分.例如:192.16 ...
- Redis 哨兵模式的原理及其搭建
1.Redis哨兵 Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复. 1.1.哨兵原理 1.1.1.集群结构和作用 哨兵的结构如图: 哨兵的作用如下: 监控:Sentinel ...
- Qt中QTabWidget添加控件(按钮,label等)以及使用方法
今天遇到了一个问题,已经在QTabWidget每一行添加了一个按钮,我有一个需求就是,点击每一行的按钮都有各自的响应 首先说一下添加控件代码: 添加文字可以用setItem,添加控件就得用setCel ...
- 使用javafx,结合讯飞ai,搞了个ai聊天系统
第一步:先在讯飞ai那边获取接入的api 点进去,然后出现这个页面: 没有的话,就点击免费试用,有了的话,就点击服务管理: 用v2.0的和用3的都行,不过我推荐用2.0版本 文档位置:星火认知大模型W ...
- Linux笔记03: Linux常用命令_3.4文件和目录共用命令
3.4 目录和文件共用命令 3.4.1 rm命令 ●命令名称:rm. ●英文原意:remove files or directories. ●所在路径:/usr/bin/rm. ●执行权限:所有用户. ...
- springboot——yaml格式