解析数仓lazyagg查询重写优化
摘要:本文对Lazy Agg查询重写优化和GaussDB(DWS)提供的Lazy Agg重写规则进行介绍。
本文分享自华为云社区《GaussDB(DWS) lazyagg查询重写优化解析【这次高斯不是数学家】》,作者: OreoreO 。
聚集操作将查询结果按某一列或多列的值分组,值相等的为一组。聚集操作是一种常见的操作并在金融客户中有广泛的使用。例如如下语句:
SELECT a, count(a) FROM t1 GROUP BY a; -- 按a分组并计算分组内重复值的个数
一、Lazy Agg重写规则
数据量大的场景下,聚集运算由于数据量大导致下盘,聚集操作执行时间成为性能瓶颈,从而导致整个查询执行效率非常差。例如:
SELECT t2.b, sum(cc) FROM (SELECT b, sum(c) AS cc FROM t1 GROUP BY b) AS s, t2 WHERE s.b=t2.b GROUP BY t2.b;
子查询对t1.b列进行聚集,对t1.c列求和,在外部查询中,同样也存在聚集运算,对子查询的聚集求和列cc列求和。对于这类语句,当子查询的聚集运算较耗时的情况下,可以利用查询重写规则消除子查询的聚集运算,由外部查询的聚集函数统一完成聚集运算。消除子查询后可能导致子查询行数增多,但对于子查询聚集运算时t1.b列的distinct值较多的场景,子查询聚集运算后的行数较原表不会有明显缩减,不会导致外层JOIN运算量的大量增加。即语句可被重写为:
SELECT t2.b, sum(cc) FROM (SELECT b, c AS cc FROM t1) AS s, t2 WHERE s.b=t2.b GROUP BY t2.b;
这个改写规则称为Lazy Agg,适用于基表数据量大且distinct值较多的场景。如果重复值较少,那么消除了聚集操作会导致Join后的行数激增,Join性能较差,因此需要将Agg下推到Join之前进行,通过提前的Agg操作减少Join结果的行数,这个改写规则称为Eager Agg。
二、GaussDB(DWS) lazyagg优化
为了降低调优难度,提升产品易用性,GaussDB(DWS)提供了lazyagg查询重写优化规则,可以通过设置guc参数rewrite_rule包含’lazyagg’使用Lazy Agg查询重写优化。开启lazyagg查询重写优化后,对满足条件的场景会优化并消除子查询中的聚集操作。原计划如下所示:
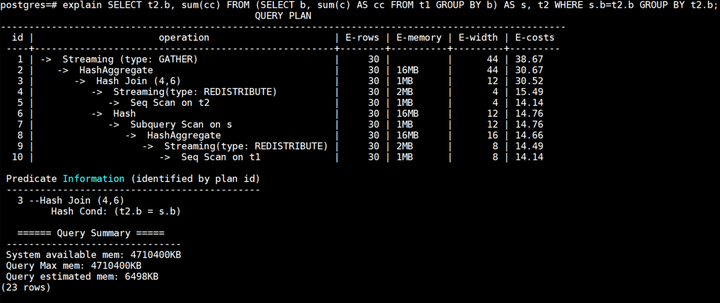
lazyagg重写优化后计划如下所示:
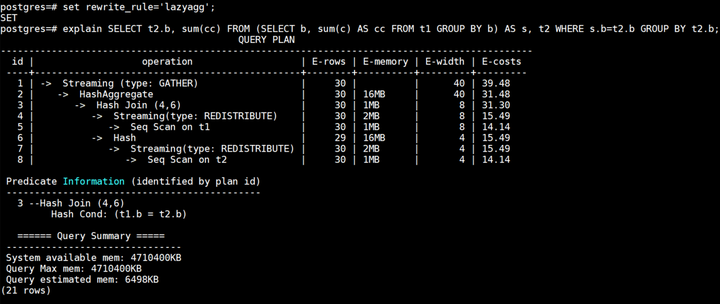
可以看到相比于原计划,lazyagg重写优化后消除掉了原计划中的聚集操作,即7号Subquery Scan算子和8号HashAggregate算子。
三、lazyagg优化规格
- 支持子查询为单一聚集查询或包含聚集子集合操作的查询。集合操作仅支持UNION ALL,可对部分分支子查询进行聚集运算消除。子查询需为JOIN表之一(不在TargetList、Where子句等其他位置)。
- 支持若外部查询的所有Agg参数列包含于其某个子查询的Agg函数列,则可对该子查询的聚集运算进行消除。
- 支持所有消除子查询聚集运算后结果正确的聚集函数种类。聚集函数种类结果正确性见下表:
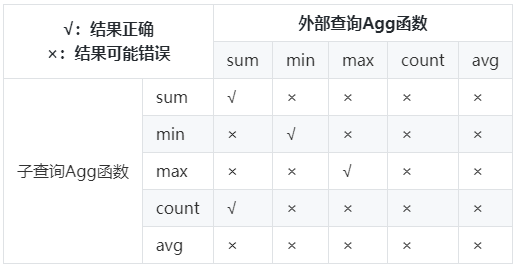
4. 场景约束
在上述场景扩展的基础上,对于可能导致结果错误的场景,不进行查询重写,包括但不限于:
- 不支持消除的Agg函数类型。
- 子查询中包含其它条件或算子,会导致重写后结果错误,例如HAVING、window agg、LIMIT、OFFSET、AP function、distinct、recursive等。
- 外层Agg参数列、GROUP BY列或JOIN列中包含volatile函数,如random、timeofday等。
- 子查询Agg函数外、外部查询Agg函数内有其他表达式或函数操作,如子查询Agg函数列为sum+1、max+max(d),外部查询Agg函数列为sum(cc+1)等。
- 外部查询的JOIN列、GROUP BY列或其它条件中包含子查询Agg函数列。
- 子查询在LEFT JOIN、RIGHT JOIN的inner边或FULL JOIN中,且子查询Agg函数为count,外部查询Agg函数为sum的。
四、结语
通过本文的分析,相信用户朋友已经充分了解了Lazy Agg重写优化的使用场景,以及GaussDB(DWS)的lazyagg实现方式。希望广大用户能够通过深入的了解,对GaussDB(DWS)的性能调优产生浓厚的兴趣并深度参与进来。
参考文档:
GaussDB(DWS)性能调优系列实战篇四:十八般武艺之SQL改写
理论不如实践,那如何快速体验DWS呢?DWS现推出了一项Demo体验活动。进入DWS首页,点击“Demo体验”,快速便捷体验一把!(体验过程中有任何建议和意见,可以去DWS社区论坛反馈哦)
解析数仓lazyagg查询重写优化的更多相关文章
- ByteHouse云数仓版查询性能优化和MySQL生态完善
ByteHouse云数仓版是字节跳动数据平台团队在复用开源 ClickHouse runtime 的基础上,基于云原生架构重构设计,并新增和优化了大量功能.在字节内部,ByteHouse被广泛用于各类 ...
- 解析数仓OLAP函数:ROLLUP、CUBE、GROUPING SETS
摘要:GaussDB(DWS) ROLLUP,CUBE,GROUPING SETS等OLAP函数的原理解析. 本文分享自华为云社区<GaussDB(DWS) OLAP函数浅析>,作者: D ...
- 技术专家说 | 如何基于 Spark 和 Z-Order 实现企业级离线数仓降本提效?
[点击了解更多大数据知识] 市场的变幻,政策的完善,技术的革新--种种因素让我们面对太多的挑战,这仍需我们不断探索.克服. 今年,网易数帆将持续推出新栏目「金融专家说」「技术专家说」「产品专家说」等, ...
- 【离线数仓】Day02-用户行为数据仓库:分层介绍、环境搭建(hive、tez)、LZO压缩、建表查询导入加索引、编写脚本
一.数仓分层概念 1.为什么要分层 ODS:原始数据层 DWD层:明细数据层 DWS:服务数据层 ADS:数据应用层 2.数仓分层 3.数据集市与数据仓库概念 4.数仓命名规范 ODS层命名为odsD ...
- 【离线数仓CDH版本】即席查询工具(Presto、Druid、Kylin)、CDH数仓、Impala查询
1.即席查询 一.Presto 大数据量.秒级.多数据源的查询引擎[支持各种数据源work的内存级查询] 由coordinator和多个work构成,work对应不同数据源Catalog 特点:基于内 ...
- MySQL 子查询(四)子查询的优化、将子查询重写为连接
MySQL 5.7 ref ——13.2.10.10优化子查询 十.子查询的优化 开发正在进行中,因此从长远来看,没有什么优化建议是可靠的.以下列表提供了一些您可能想要使用的有趣技巧.See also ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
- mysql查询性能优化
mysql查询过程: 客户端发送查询请求. 服务器检查查询缓存,如果命中缓存,则返回结果,否则,继续执行. 服务器进行sql解析,预处理,再由优化器生成执行计划. Mysql调用存储引擎API执行优化 ...
- 高性能MySQL笔记 第6章 查询性能优化
6.1 为什么查询速度会慢 查询的生命周期大致可按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段. ...
- mysql笔记03 查询性能优化
查询性能优化 1. 为什么查询速度会慢? 1). 如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间.如果要优化查询,实际上要优化其子任务,要么消除其中一些子任务,要么减 ...
随机推荐
- 数据类型python
type()语句的用法 运行结果
- could not chdir to home directory /home/user:permission denied /bin/bash:Permiss 的原因和解决方法
今天在vm上登录一个user 的时候,发现正确输入用户名和密码后弹出了这样的信息,登陆不上. 发现给出的信息中,permission denied 而 bin permiss; 这种情况表明自己给该用 ...
- 特殊符号传到后端发生变异 & "<>
业务遇到bug,前端传回数据 & ,到后台接收到的数据就是 & 后台接收到的数据就携带了amp;的后缀 网上查找原因,大部分说法是前端传回的数据导致,但是实际并不是,这里是框架的正则过 ...
- APP攻防--安卓逆向&数据修改&逻辑修改&视图修改
APP攻防--安卓逆向&数据修改&逻辑修改&视图修改 @ 目录 APP攻防--安卓逆向&数据修改&逻辑修改&视图修改 工具集 apk目录意义 逆向数据修 ...
- [NOIP 考前备战] 线段树刷题
备战线段树 T1 AcWing .1275. 最大数 查询最大值 + 单点修改 #include <bits/stdc++.h> #define int long long using n ...
- JavaSript 数组
添加数组 push是添加在数组的末位,unshift是添加在首位 let arr= ['a','b','c'] arr.push('d') arr.unshift('E')
- Android Recyclerview的item间距实现
Recyclerview中,提供了一个方法addItemDecoration给我们用于设置item的分割线 下面提供几个常见的分割线效果 注: 下面的SizeUtils是AndroidUtilCode ...
- C语言一辆卡车撞人逃逸。现场三人目击事件,只记下车的一些特征。甲说:牌照的前两位数字是相同的;乙说:牌照的后两位数字是相同的;丙是位数学家说:四位的车号正好是一个整数的平方
#include <stdio.h> #include <math.h> void main() { int a, b, c, d, n, h; double t; for ( ...
- python之封装及私有方法
目录 封装 简洁 私有方法 封装:提高程序的安全性 将属性和方法包装到类对象中,在方法内部对属性进行操作,在类对象外部调用方法,使得程序更加简洁 在python中,如果该属性不希望在类对象外部被访问, ...
- Unity学习笔记--数据持久化XML文件(2)
IXmlSerializable接口: 使用该接口可以帮助处理不能被序列化和反序列化的特殊类得到处理, 使特殊类继承IXmlSerializable接口 ,实现其中的读写方法,检测到读写方法被重写之后 ...