【转载】 推荐系统 EE 问题与 Bandit 算法
原文地址:
https://toutiao.io/posts/584etm/preview

-------------------------------------------------------------------------
生活中你可能会遇到类似的情况,你在网上购买了手机,淘宝之后会不断给你推送关于手机相关的商品;如果你看了关于NBA詹姆斯的相关新闻,今日头条之后会不断给你推送詹姆斯的新闻。时间长了,你会发现你的世界里只有手机和詹姆斯,天呐,世界越来越小,视野越来越窄怎么办?
别担心,上面的这种情况就属于EE问题的一种,更多的关于什么是推荐系统的EE问题可以参见:推荐系统EE(exploit-explore)问题概述。针对 EE 问题,可以使用 Bandit 算法来解决。这里介绍一些常用的 Bandit 算法。
Naive
Naive 的核心就在于朴素,它的做法就是先进行 N 次尝试,然后统计每个臂的平均收益,接下来一直选择平均收益最大的臂。这个算法是人们在实际中最常采用的。
Epsilon-Greedy(ε-Greedy)
Epsilon-Greedy 通过生成一个 (0,1) 范围内的数字 ε ,用它来表示概率,表示以 ε 的概率去从所有候选臂中随机选择一个,也就是 explore,以 1- ε 的概率去选择平均收益最大的臂,也就是 exploit。
通过 ε 的值可以控制对 explore 和 exploit 的权衡程度, ε 值越小,表明 explore 越保守,会有更好的稳定性。
很明显 ε 数值的确定是一件不容易的事情。
Thompson Sampling(汤普森采样)
介绍汤普森采样之前,可以先来介绍一个分布:beta 分布。beta 分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小。
beta 分布有两个控制参数:α 和 β 。先来看下几个 beta 分布的概率密度函数的图形:
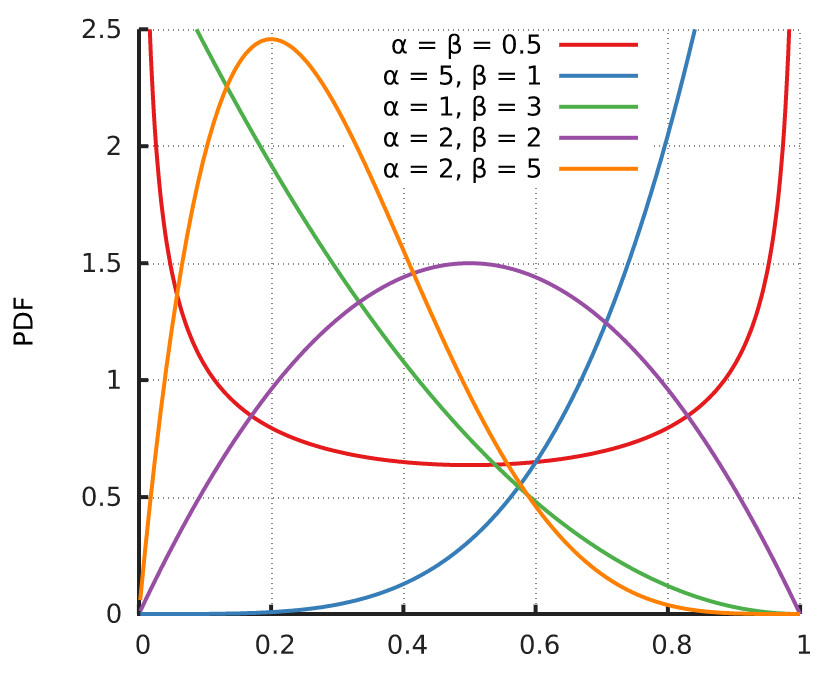
beta 分布图形中的 x 轴取值范围是 (0,1),可以看成是概率值,参数 α 和 β 可以控制图形的形状和位置:
α + β 的值越大,分布曲线越窄,也就是越集中。
α/(α + β) 的值是 beta 分布的均值(期望值),它的值越大, beta 分布的中心越靠近 1,否则越靠近 0 。
注意:当参数 α 和 β 确定后,使用 beta 分布生成的随机数有可能不一样,所以汤普森采样法是不确定算法。
beta 分布和 Bandit 算法有什么关联呢?实际上,每个臂是否产生收益的概率 p 的背后都对应一个 beta 分布。我们将 beta 分布的 α 参数看成是推荐后用户的点击次数, β 参数看成是推荐后用户未点击的次数。
来看下使用汤普森算法的流程:
每个臂都维护一个 beta 分布的参数,获取每个臂对应的参数 α 和 β,然后使用 beta 分布生成随机数。
选取生成随机数最大的那个臂作为本次结果
观察用户反馈,如果用户点击则将对应臂的 α 加 1,否则 β 加 1
在实际的推荐系统中,需要为每个用户保存一套参数,假设有 m 个用户, n 个臂(选项,可以是物品,可以是策略), 每个臂包含 α 和 β 两个参数,所以最后保存的参数的总个数是 2 m n。
可以直观的理解下为什么汤普森采样算法有效:
当尝试的次数较多时,即每个臂的 α + β 的值都很大,这时候每个臂对应的 beta 分布都会很窄,也就是说,生成的随机数都非常接近中心位置,每个臂的收益基本确定了。
当尝试的次数较少时,即每个臂的 α + β 的值都很小,这时候每个臂对应的 beta 分布都会很宽,生成的随机数有可能会比较大,增加被选中的机会。
当一个臂的 α + β 的值很大,并且 α/(α + β) 的值也很大,那么这个臂对应的 beta 分布会很窄,并且中心位置接近 1 ,那么这个臂每次选择时都很占优势。
使用 python 来实现汤普森采样:
import numpy as np import pymc # wins 和 trials 都是一个 N 维向量,N 是臂的个数 # wins 表示所有臂的 α 参数,loses 表示所有臂的 β 参数 choice = np.argmax(pymc.rbeta(1 + wins, 1 + loses, len(wins))) # wins[choice] += 1 # loses[choice] += 1
UCB(Upper Confidence Bound)
UCB 算法全称是 Upper Confidence Bound,即置信区间上界。它是计算每个臂的平均收益与该收益的不确定性来作为最终得分。公式如下:
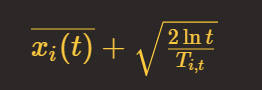
i 表示当前的臂,t 表示目前的尝试次数,Ti,t 表示臂 i 被选中的次数。公式加号左边表示臂 i 当前的平均收益,右边表示该收益的 Bonus ,本质上是均值的标准差,反应了候选臂效果的不确定性,就是置信区间的上边界。
使用 UCB 算法的流程如下:
对所有臂先尝试一次
按照公式计算每个臂的最终得分
选择得分最高的臂作为本次结果
直观理解下 UCB 算法为什么有效?
当一个臂的平均收益较大时,也就是公式左边较大,在每次选择时占有优势
当一个臂被选中的次数较少时,即 Tit 较小,那么它的 Bonus 较大,在每次选择时占有优势
所以 UCB 算法倾向选择被选中次数较少以及平均收益较大的臂。
UCB 算法需要对所有的臂进行一次尝试,当臂比较多时,可能会比较耗时,如果 UCB 算法的参数是确定的,那么输出结果就是确定的,也就是说它本质上仍然是一个“确定性”的算法,这会导致它的 explore 能力受限。
总结
为解决推荐系统 EE 问题,可以使用 Bandit 算法,这里介绍了常用的 Bandit 算法,如:Naive、Epsilon-Greedy(ε-Greedy)、UCB(Upper Confidence Bound)等,但是这些算法都没有考虑上下文信息,也就是环境,之后会介绍结合上下文信息的 LinUCB 算法。
【转载】 推荐系统 EE 问题与 Bandit 算法的更多相关文章
- 通俗bandit算法
[原文链接] 选择是一个技术活 著名鸡汤学家沃.滋基硕德曾说过:选择比努力重要. 我们会遇到很多选择的场景.上哪个大学,学什么专业,去哪家公司,中午吃什么,等等.这些事情,都让选择困难症的我们头很大. ...
- Spark/Scala实现推荐系统中的相似度算法(欧几里得距离、皮尔逊相关系数、余弦相似度:附实现代码)
在推荐系统中,协同过滤算法是应用较多的,具体又主要划分为基于用户和基于物品的协同过滤算法,核心点就是基于"一个人"或"一件物品",根据这个人或物品所具有的属性, ...
- MindSpore:基于本地差分隐私的 Bandit 算法
摘要:本文将先简单介绍Bandit 问题和本地差分隐私的相关背景,然后介绍基于本地差分隐私的 Bandit 算法,最后通过一个简单的电影推荐场景来验证 LDP LinUCB 算法. Bandit问题是 ...
- (转载)LCA问题的Tarjan算法
转载自:Click Here LCA问题(Lowest Common Ancestors,最近公共祖先问题),是指给定一棵有根树T,给出若干个查询LCA(u, v)(通常查询数量较大),每次求树T中两 ...
- 转载:scikit-learn学习之SVM算法
转载,http://blog.csdn.net/gamer_gyt 目录(?)[+] ========================================================= ...
- 开源推荐系统Librec中recommender模块算法了解——cf模块
1. k近邻(k-NearestNeighbor)算法介绍及在推荐系统中的应用 https://zhuanlan.zhihu.com/p/25994179 k近邻(k-NearestNeig ...
- 【转载】分布式系列文章——Paxos算法原理与推导
转载:http://linbingdong.com/2017/04/17/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E5%88%97%E6%96%87%E7%AB%A0 ...
- 推荐系统中的协同滤波算法___使用SVD
对于推荐方法,基于内容 和 基于协同过滤 是目前的主流推荐算法,很多电子商务网站的推荐系统都是基于这两种算法的. 协同过滤 是一种基于相似性来进行推荐的算法,主要分为 基于用户的协同过滤算法 和 基于 ...
- 【转载】Dijkstra算法和Floyd算法的正确性证明
说明: 本文仅提供关于两个算法的正确性的证明,不涉及对算法的过程描述和实现细节 本人算法菜鸟一枚,提供的证明仅是自己的思路,不保证正确,仅供参考,若有错误,欢迎拍砖指正 ----------- ...
- 【转载】MCMC和Gibbs Sampling算法
转载随笔,原贴地址:MCMC和Gibbs Sampling算法 本文是整理网上的几篇博客和论文所得出来的,所有的原文连接都在文末. 在科学研究中,如何生成服从某个概率分布的样本是一个重要的问题.如果样 ...
随机推荐
- ClickHouse + ClickVisual 构建日志平台
越来越多的互联网公司开始尝试 ClickHouse 存储日志,比如映客.快手.携程.唯品会.石墨文档,但是 ClickHouse 存储日志缺少对应的可视化方案,石墨文档开源了 ClickVisual ...
- Vue学习:17.组件通信案例-记事本
通过上一节的学习,我们了解并掌握了组件通信的定义及一般使用.那么接下来,我们将之前练习过的案例使用组件化思想来实现一下吧. 实例:记事本(组件化) 实现功能 运用组件化思想,实现Vue学习:3.V标签 ...
- 跨域iframe 配置fullscreen权限
在新版本的 Chrome 等浏览器中,默认情况下禁止了跨域 iframe 开启全屏的权限.在 iframe 中,我们通常使用 element.requestFullscreen() 方法来进行全屏展示 ...
- Javascript高级程序设计第一章 | ch1 | 阅读笔记
什么是JavaScript 历史回顾 JavaScript实现 完整的JavaScript实现包括 核心 ECMAScript -> 语法.类型.关键字.保留字...(规范) 文档对象模型 DO ...
- python重拾基础第四天
本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 1. 列表生成式,迭代器&生成器 列表生成式 我现在有个需求, ...
- Top cluster 树分块
写点基础的东西.随便写的,勿喷. top cluster 一个 cluster 是一个联通子图,且至多有两个点与其他部分连接 这两个点被称为 boundary node 其余点被称为 internal ...
- SpringBoot获取请求头信息
Http 头信息 HTTP 头(Header)是一种附加内容,独立于请求内容和响应内容. HTTP 协议中的大量特性都通过Header信息交互来实现,比如内容编解码.缓存.连接保活等等. reques ...
- Netcode for Entities里如何对Ghost进行可见性筛选(1.2.3版本)
一行代码省流:SystemAPI.GetSingleton() 当你需要按照区域.距离或者场景对Ghost进行筛选的时候,Netcode for Entities里并没有类似FishNet那样方便的过 ...
- 内网穿透的高性能的反向代理应用FRP-自定义404错误页【实践可行版】
frp简介 frp 是一个专注于内网穿透的高性能的反向代理应用,支持 TCP.UDP.HTTP.HTTPS 等多种协议.可以将内网服务以安全.便捷的方式通过具有公网 IP 节点的中转暴露到公网. 为什 ...
- 【解决方案】智能UI自动化测试
你的UI自动化追得上业务的变更和UI更迭吗?当今瞬息万变的时代,成千上万的App围绕着现代人生活的点点滴滴.为了满足用户的好的体验和时刻的新鲜感,这些App需要时刻保持变化,也给 UI自动化落地实施带 ...