我用Awesome-Graphs看论文:解读GraphBolt
GraphBolt论文:《GraphBolt: Dependency-Driven Synchronous Processing of Streaming Graphs》
前面通过文章《论文图谱当如是:Awesome-Graphs用200篇图系统论文打个样》向大家介绍了论文图谱项目Awesome-Graphs,并分享了Google的Pregel、OSDI'12的PowerGraph、SOSP'13的X-Stream和Naiad。这次向大家分享一篇流图处理系统论文GraphBolt,看如何基于计算历史的方式实现增量图计算,并保证与全量图计算语义的一致性。
对图计算技术感兴趣的同学可以多做了解,也非常欢迎大家关注和参与论文图谱的开源项目:
- Awesome-Graphs:https://github.com/TuGraph-family/Awesome-Graphs
- OSGraph:https://github.com/TuGraph-family/OSGraph
提前感谢给项目点Star的小伙伴,接下来我们直接进入正文!
摘要
GraphBolt通过抓取计算过程中的中间值依赖实现依赖驱动的增量计算,并保证了BSP语义。
1. 介绍
流图处理的核心是动态图,图的更新流会频繁地修改图的结构,增量图算法会及时响应图结构的变更,生成最新图快照的最终结果。因此,增量图算法的核心目标是最小化重复计算。典型系统如:GraphIn、KickStarter、Differential Dataflow等。
GraphBolt通过依赖驱动的流图处理技术最小化图变更带来的重复计算。
- 描述并跟踪迭代过程中产生的中间值的依赖关系。
- 图结构变更时,根据依赖关系逐迭代地产生最终结果。
关键优化:
- 利用图结构信息以及点上聚合值的形式,将依赖信息的规模从O(E)降低为O(V)。
- 支持依赖驱动的优化策略和传统的增量计算的动态切换,以适应因剪枝导致依赖信息不可用的情况。
- 提供通用的增量编程模型支持将复杂聚合拆解为合并增量值的方式。
2. 背景与动机
2.1 流图处理
流图G会一直被ΔG更新流修改,ΔG包含了点/边的插入/删除,算法S在最新的图快照上迭代计算最终结果。为了保证一致性,迭代计算过程中的更新被分批写入到ΔG,并在下次迭代开始前合并到G。
同步处理
BSP模型将计算分为多个迭代,当前迭代的计算只依赖于上次迭代计算的结果。这让图算法的开发更简单,并能清晰的推导收敛信息以及准确性验证。因此,同步处理模型是大规模图计算系统的首选。
增量计算
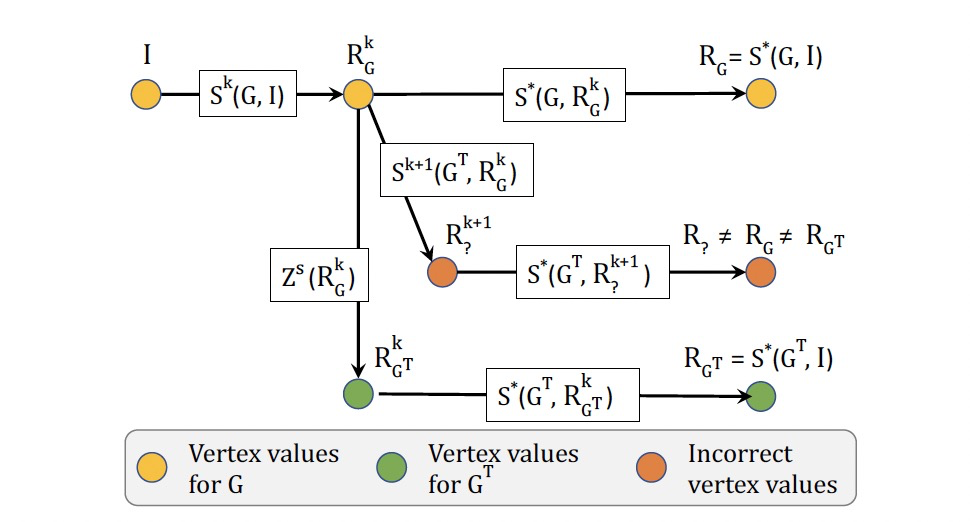
- I:点初始值。
- k:迭代次数。
- Si(G, I):以I为输入的图G上算法S的第i次迭代。
- S*(G, I):以I为输入的图G上算法的最后一次迭代。
- RGi:图G的第i次迭代结果。
- RG:图G的迭代结果。
- GT:G+ΔG。
- Zs:转换函数,\(R_{G^T}^k = Z^s(R_G^k)\)。
2.2 问题:不正确的结果
如何在面向图变更的流图的增量计算中最小化重复计算,而又保证同步处理的语义?

2.3 技术概览
依赖驱动增量计算面临的挑战:
- 在线跟踪依赖信息成本高,复杂度|E|。
- 基于点聚合值的方式,将复杂度降低到|V|。
- 现实图一般是稀疏倾斜的,可以对依赖信息进行保守的剪枝。
- 处理复杂聚合计算的困难性。
- 开发通用增量编程模型将复杂聚合分解为增量的值变更。
- 简单聚合,如sum、count可以直接表达,而无需走分解的流程。
- 计算感知的混合执行能力。
- 支持依赖驱动的优化策略和传统的增量计算的动态切换。
3. 依赖感知处理
3.1 同步处理语义
基于图结构定义值依赖关系:
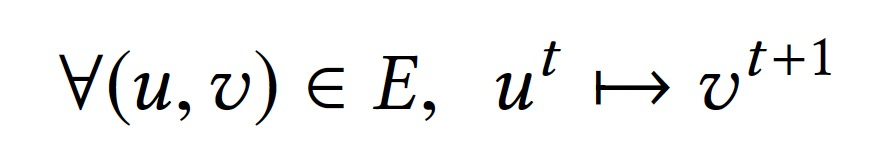
- (u, v):计算图中任意边。
- ut:第t次迭代,点u的值。
- ->:依赖关系,后者依赖前者。
3.2 跟踪值依赖关系
假设第L次迭代后,图G被修改为GT,CL对应迭代L结束后的点值集合。为了保证结果的准确性,需要跟踪计算过程中所有对CL有贡献的点值信息。
令\(\mathcal{D}_G=(\mathcal{V}_D,\mathcal{E}_D)\),则有:
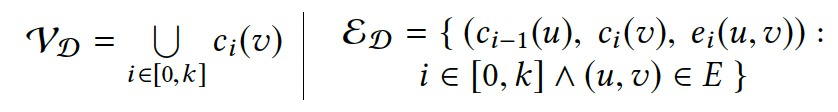
每次迭代,DG增加|V|个点和|E|和边信息。空间复杂度O(|E|·t)。
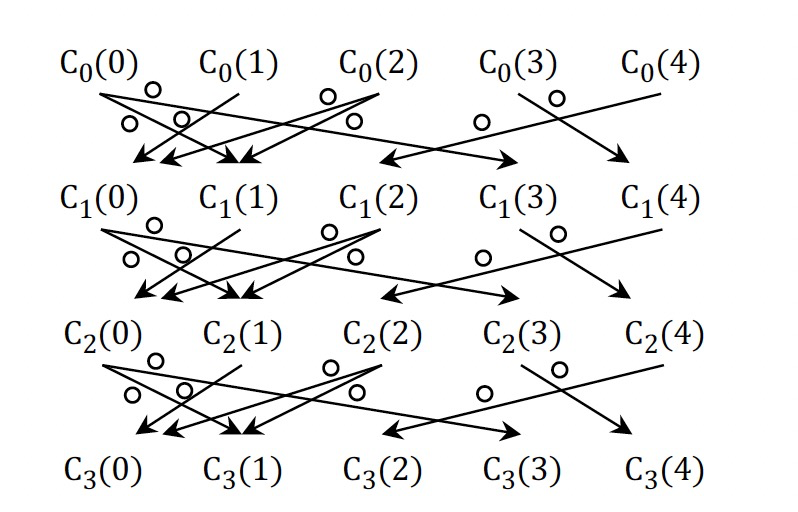
基于点聚合值跟踪点依赖
一般点值计算分为两个步骤。
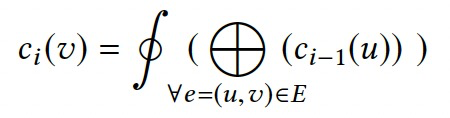
- \(\bigoplus\):聚合上次迭代的邻居点的值。
- \(\oint\):根据聚合值计算点值。
令\(g_i(v)=\bigoplus_{\forall e=(u,v)\in E}(c_{i-1}(u))\),\(\mathcal{A}_G=(\mathcal{V}_\mathcal{A},\mathcal{E}_\mathcal{A})\),则有:
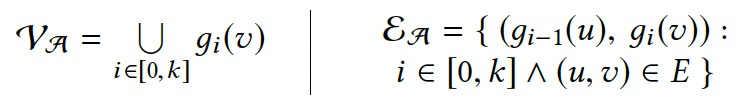
通过跟踪点上的聚合值,而非单独的点值,将空间复杂度降低到O(|V|·t)。
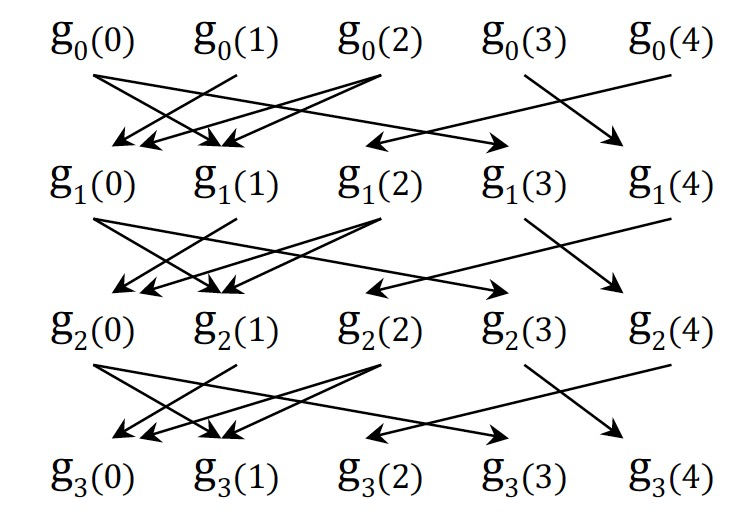
裁剪值聚合信息
现实图上一般都是倾斜的,所以算法最开始的时候大多数点值会发生变化,但随着迭代的推进,更新点的数量将逐渐减少。
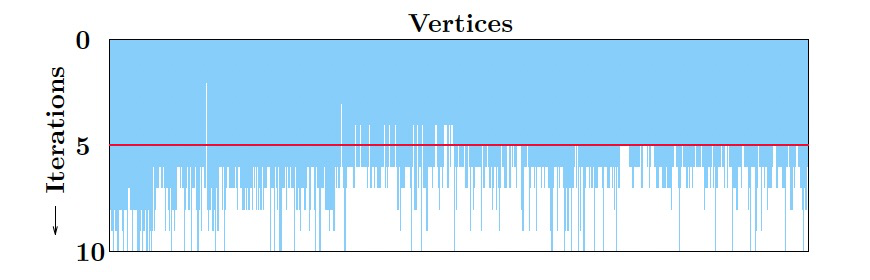
当点值稳定时,点上的聚合值也趋于稳定,这就为聚合值的依赖信息跟踪提供了优化机会。
- 水平裁剪:当到达确定的迭代后,停止跟踪聚合值,对应上图中的红线。
- 垂直裁剪:对于已经稳定的点值,将不再跟踪聚合值,对应上图中红线上的白色区域。
3.3 依赖驱动的值优化
令Ea表示新增的边,Ed表示删除的边,则有\(G^T=G \cup E_a \backslash E_d\),对于依赖图\(\mathcal{A}_G\),如何转换CL到CLT。
优化什么?
每次迭代的优化动作有两种:
- Ea、Ed中边的终点,对应的点值会被边修改影响。
- 终点的邻居,邻居点值会在下次迭代中被优化。

例如,新增边1->2时,聚合值的更新如上图。其中实线表示值的传播,虚线表示值的变化。
整个过程依赖于图\(\mathcal{A}_G\),聚合值变化来源于边的修改。优化过程中涉及的计算远小于在原图上重新计算。
如何优化?
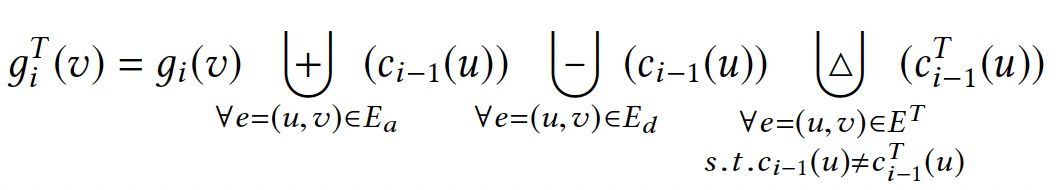
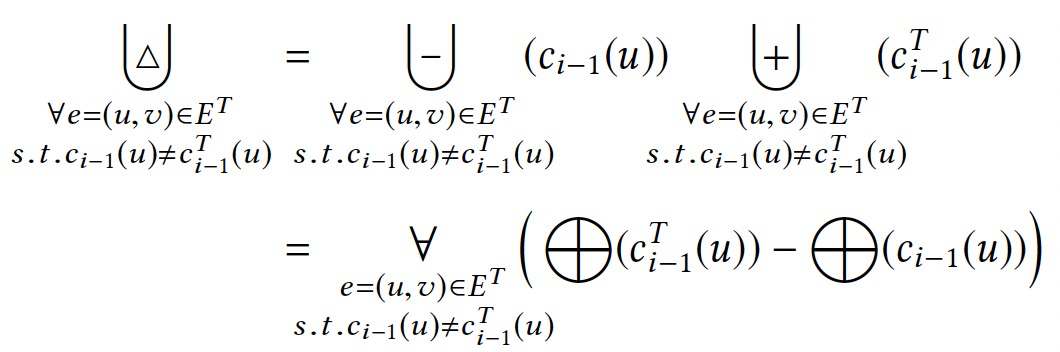
对于简单的聚合操作,如sum、product,可以直接计算出变化的贡献。但是对于复杂的聚合操作,如向量操作,就比较难以直接表示。
复杂聚合
对于MLDM算法,如BP、ALS,将点值增量化就比较困难。将复杂聚合转换为增量方式,可以分为两步。
静态拆解为简单子聚合
复杂聚合可以被分解为多个简单的子聚合,如ALS算法。
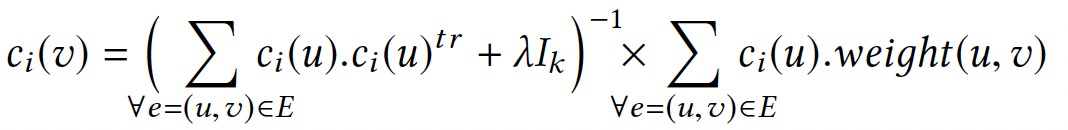
聚合值可以表示为:
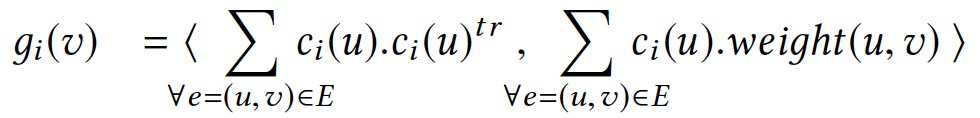
独立贡献的动态求值
子聚合对点值的计算发生在sum之前,会带来重复计算。因此需要独立计算每个部分,再计算聚合的差异值。
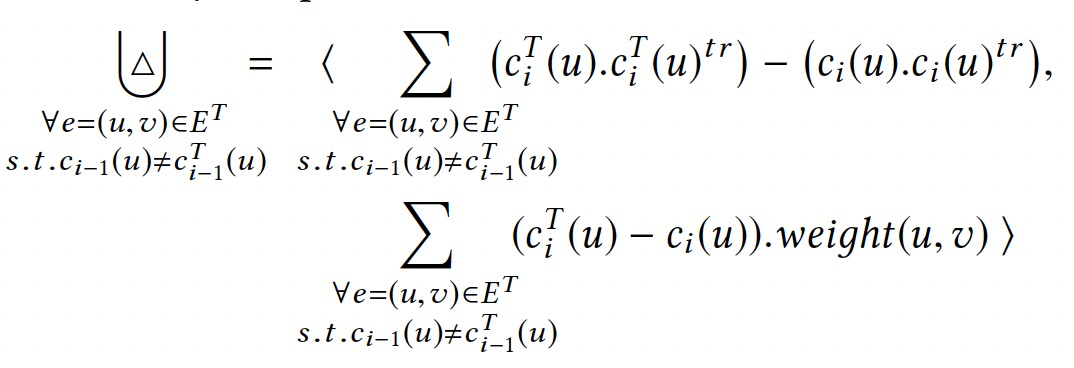
聚合属性和扩展
三个增量聚合算子(+、-、Δ)的特点:
- 算子是可交换、可结合的。
- 算子的定义域包含点上的聚合值以及边上的关联值。
- 算子可以增量的处理单个输入带来的影响。
这类算子属于可分解的,如sum、count。
相对的则是不可分解的算子,如max、min。对+操作可以可增量的,但是-和Δ则不可。
因此聚合值就退化为输入点值的集合,实现方式是动态拉取输入边的值。
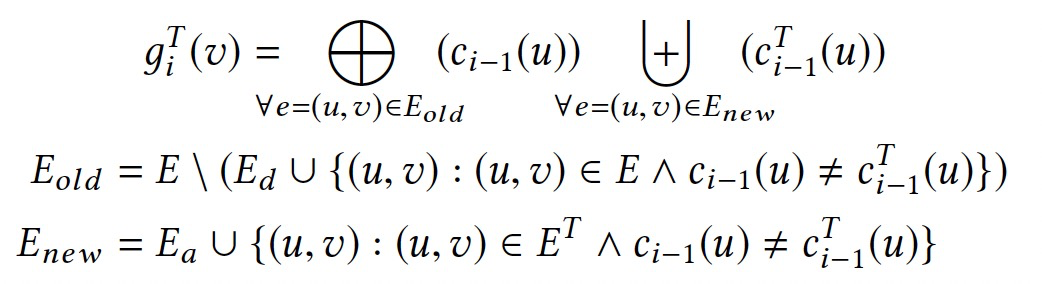
4. GraphBolt处理引擎
4.1 流图和依赖布局
点/边的增加/删除以以下两种方式进行:
- 单个点/边的变更。
- 批量点/边的变更。
变更一旦生效会立即触发值优化,在优化过程中的的变更会被缓存,并在接下来的优化步中继续处理。
聚合值被维护在一个和点对应的数组中,保存了跨迭代的值数据。随着计算过程,聚合值信息被更新并动态增长。
4.2 依赖驱动的处理模型
BP算法使用restract+propagate模拟update。

PangeRank算法直接定义propagate_delta实现update。

选择性调度
GraphBolt只会在邻居值更新后才会重新计算点值,并允许用户指定选择性调度的逻辑,如比较值变化的容忍范围来决定是否发起重新计算。
计算感知的混合执行
水平裁剪导致超过指定迭代后,聚合值将不再有效,GraphBolt会动态切换为不带值优化的增量计算模式。
4.3 保证同步语义
定理:使用依赖驱动的值优化方式,基于ci-1T(u)计算giT(v)可以满足ET定义的依赖关系。
5 相关工作
- 流图处理框架
- Tornado:在图更新时,分叉执行用户查询。
- KickStarter:使用依赖树增量修正单调图算法。
- GraphIn:使用固定大小的批处理动态图,提供了5阶段处理模型。
- Kineograph:基于pull/push模型实现图挖掘的增量计算。
- STINGER:提出动态图数据结构,为特定问题研发算法。
- 图快照的批处理
- Chronos:使用增量的方式实现跨快照的计算。
- GraphTau:维护快照上的值历史记录,通过值的回退实现数据修正。
- 静态图处理系统:处理离散的图快照。
- 通用流处理
- 通用流处理系统:操作无边界的非结构化数据流。
- Differential Dataflow:扩展了Timely Dataflow的增量计算,它强依赖于差分算子。
- 增量算法
- 增量PageRank
- Triangle Counting
- IVM算法
我用Awesome-Graphs看论文:解读GraphBolt的更多相关文章
- 论文解读《The Emerging Field of Signal Processing on Graphs》
感悟 看完图卷积一代.二代,深感图卷积的强大,刚开始接触图卷积的时候完全不懂为什么要使用拉普拉斯矩阵( $L=D-W$),主要是其背后的物理意义.通过借鉴前辈们的论文.博客.评论逐渐对图卷积有了一定的 ...
- 论文解读(MGAE)《MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs》
论文信息 论文标题:MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs论文作者:Qiaoyu Tan, Ninghao L ...
- 论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》
论文信息 论文标题:Rethinking the Setting of Semi-supervised Learning on Graphs论文作者:Ziang Li, Ming Ding, Weik ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- 《Stereo R-CNN based 3D Object Detection for Autonomous Driving》论文解读
论文链接:https://arxiv.org/pdf/1902.09738v2.pdf 这两个月忙着做实验 博客都有些荒废了,写篇用于3D检测的论文解读吧,有理解错误的地方,烦请有心人指正). 博客原 ...
- 注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
文章转自微信公众号:[机器学习炼丹术] 参考目录: 目录 0 概述 1 主要内容 1.1 Non local的优势 1.2 pytorch复现 1.3 代码解读 1.4 论文解读 2 总结 论文名称: ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
- CVPR2020 论文解读:少点目标检测
CVPR2020 论文解读:具有注意RPN和多关系检测器的少点目标检测 Few-Shot Object Detection with Attention-RPN and Multi-Relation ...
- 图像分类:CVPR2020论文解读
图像分类:CVPR2020论文解读 Towards Robust Image Classification Using Sequential Attention Models 论文链接:https:// ...
随机推荐
- edge ctrl+c 复制不起作用
现象: 在edge中选中文字时,按一次ctrl+c,到其它程序ctrl+v,并不是你选中的内容. 需要在edge中按2次ctrl+c才行. --- 当你选中文字时,会出现一个三个点的菜单,点击后会出现 ...
- Spring Data JPA 学习笔记1 - JPA与Spring Data
标记[跳过]的未来完善 1 理解JPA 1.1 什么是持久化? 当一个软件关闭的时候,软件内储存的状态数据还能在下次开启时被恢复,这就是持久化.对象持久化是指每个独立的对象的生命周期都能不依赖应用程序 ...
- @RequestMapping 注解用在类上面有什么作用?
是一个用来处理请求地址映射的注解,可用于类或方法上.用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径.
- OAuth + Security - 4 - 客户端信息存储数据库
PS:此文章为系列文章,建议从第一篇开始阅读. 在之前的所有配置中,我们的客户端信息和授权码模式下的授权码任然还是存储在数据库中的,这样就不利于我们后期的扩展,所以在正式的生成环境中,我们一般将其存储 ...
- CPU的一、二、三级缓存的区别
引言 概念 缓存大小也是CPU的重要指标之一,而且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是和处理器同频 运作,工作效率远远大于系统内存和硬盘.实际工作时,CPU往往 ...
- 【前端求助帖】关于使用element-plus select 模板嵌套popover中使用select选择后,上一个select自动关闭的问题
主页代码如下 项目使用的是Vue3+vite, 下载后,直接pnpm i安装依赖, pnpm dev 就是可以跑起来 <el-button type="warning" ...
- 01-Python介绍、安装与入门
Python介绍 关于Python Python 是一种解释型.面向对象.动态数据类型的高级程序设计语言. 解释型:Python将代码边解释边运行,而不是像C一样编译.类似解释型的语言还有JAVA. ...
- 将PaddleOCR 转为 ONNX 运行
PaddleOCR 是目前最好的开源OCR框架, 但paddle框架的兼容性实在不怎么好, 部署的时候容易出现各种各样的问题. 如果能把PaddleOCR转成ONNX, 就可以跳过paddle框架坑的 ...
- git连接到https服务器时出现“gnutls_handshake() failed”
git连接到https服务器时出现"错误: gnutls_handshake()失败" 问题描述 当我尝试使用git连接到任何HTTPS服务器时(例如git clone),它会出现 ...
- Git ignore 忽略文件不起作用
前提:拉取了项目上的代码,或者自己本地已经提交过了的文件.然后在 .gitignore 文件中添加了过滤,但是不管用,还是可以追踪 解决方案: 1.先删除本地的文件(可以备份到其他文件夹外) 2.然后 ...