1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等
文本抽取任务Label Studio使用指南

1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等
2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等
3.基于Label studio的训练数据标注指南:文本分类任务
4.基于Label studio的训练数据标注指南:情感分析任务观点词抽取、属性抽取
目录
1. 安装
以下标注示例用到的环境配置:
- Python 3.8+
- label-studio == 1.7.1
- paddleocr >= 2.6.0.1
在终端(terminal)使用pip安装label-studio:
pip install label-studio==1.7.1
pip install label-studio
#安装过程报错ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问
#添加管理员权限
pip install --user label-studio
#如果途中出现警告:WARNING: Ignoring invalid distribution -sonschema (d:\anaconda\envs\paddlenlp\lib\site-packages)
1.原因可能是之前下载库的时候没有成功或者中途退出,当包出现问题(例如缺少依赖项或与其他包冲突)时,可能会出现此警告消息。如果包与正在使用的 Python 版本不兼容,也可能发生这种情况。
2.到提示的目录site-packages下删除~ip开头的目录。
3.然后pip重新安装库即可。
#如果怕环境冲突就新建虚拟环境,单独安装
conda create -n test python=3.8 #test为创建的虚拟环境名称
安装完成后,运行以下命令行:
label-studio start
在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。
2. 文本抽取任务标注
2.1 项目创建
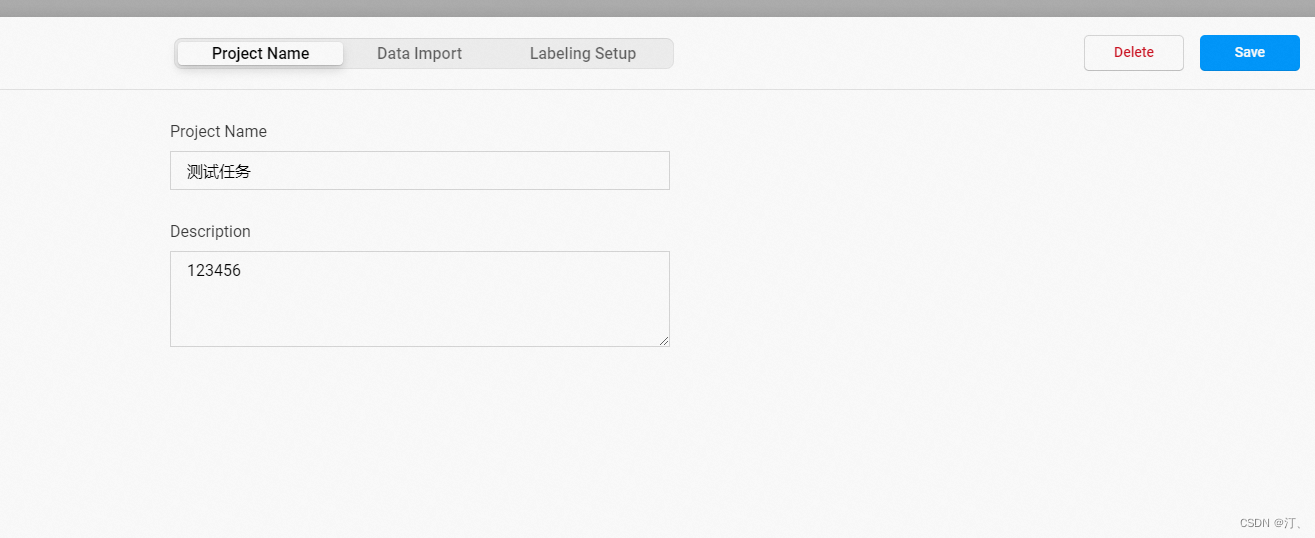
点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后选择Object Detection with Bounding Boxes。
- 填写项目名称、描述
- 命名实体识别、关系抽取、事件抽取、实体/评价维度分类任务选择``Relation Extraction`。
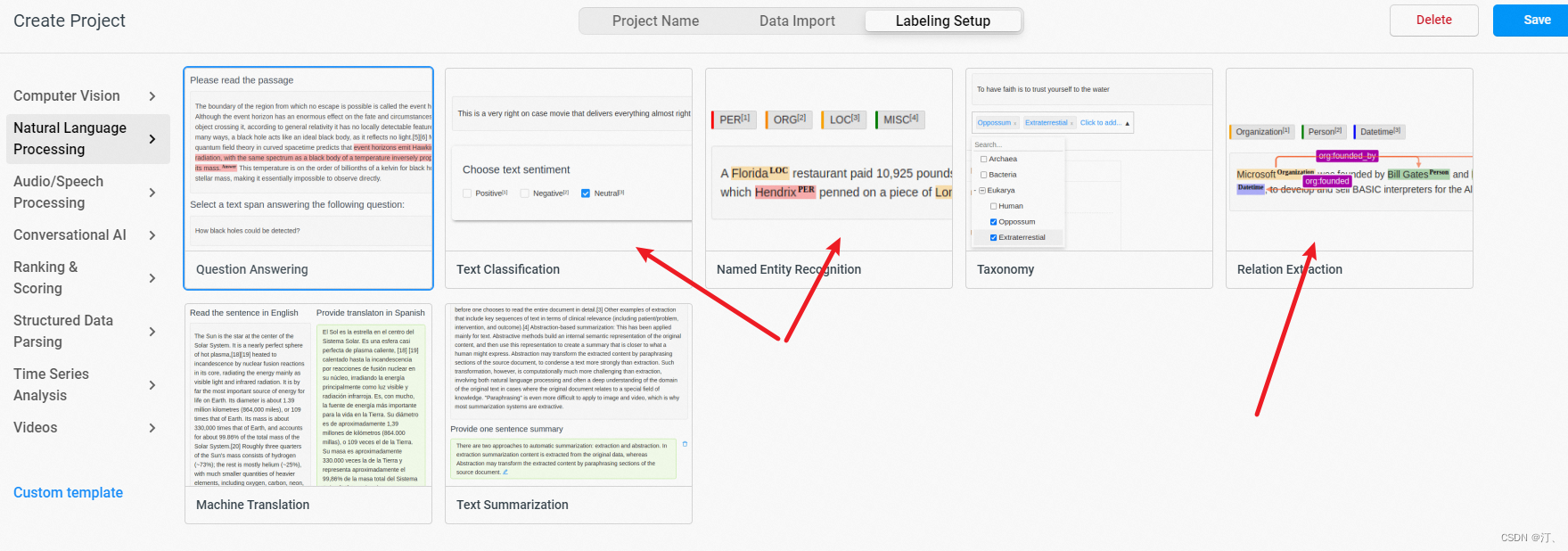
文本分类、句子级情感倾向分类任务选择
Text Classification。添加标签(也可跳过后续在Setting/Labeling Interface中配置)
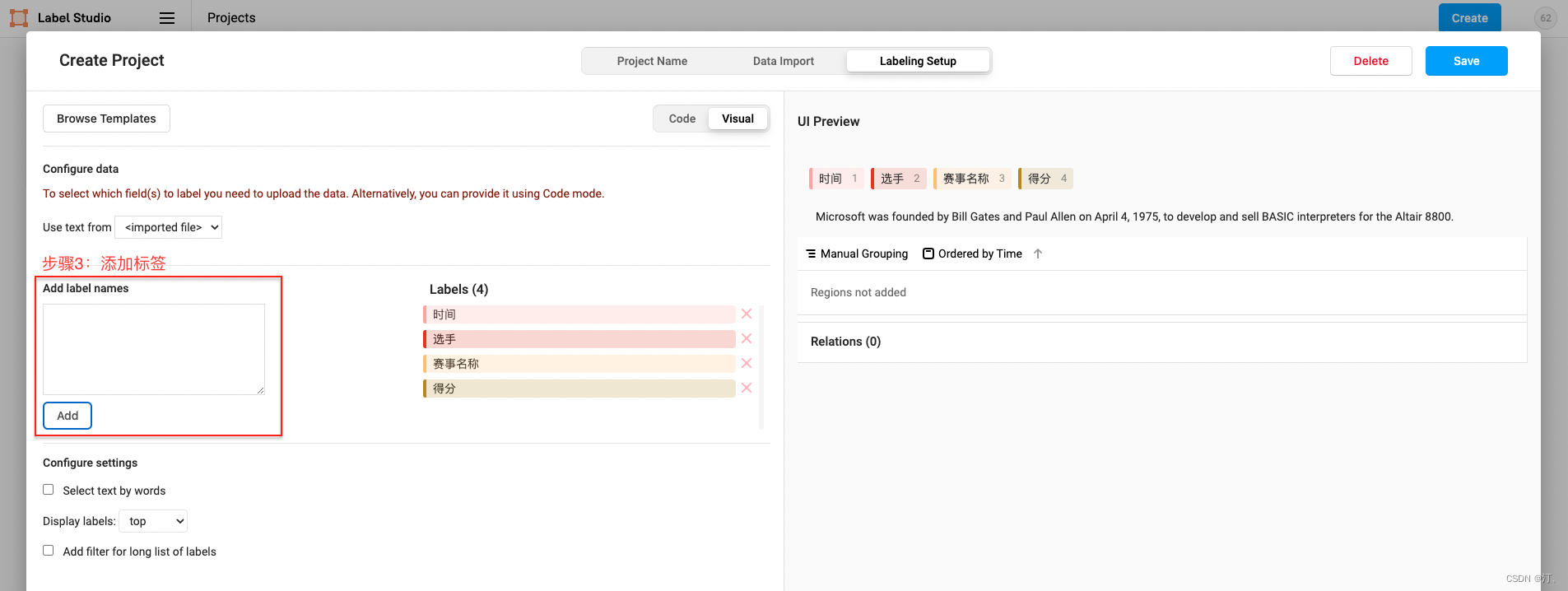
图中展示了实体类型标签的构建,其他类型标签的构建可参考2.3标签构建
2.2 数据上传
先从本地上传txt格式文件,选择List of tasks,然后选择导入本项目。

2.3 标签构建
- Span类型标签

- Relation类型标签

Relation XML模板:
<Relations>
<Relation value="歌手"/>
<Relation value="发行时间"/>
<Relation value="所属专辑"/>
</Relations>
- 分类类别标签

2.4 任务标注
- 实体抽取
标注示例:
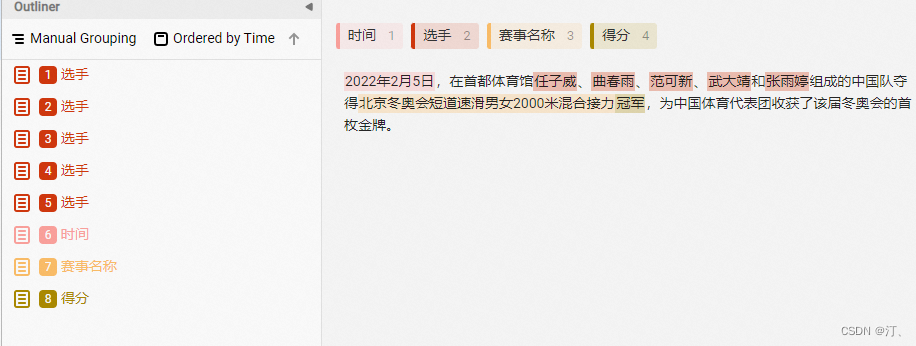
该标注示例对应的schema为:
schema = [
'时间',
'选手',
'赛事名称',
'得分'
]
- 关系抽取

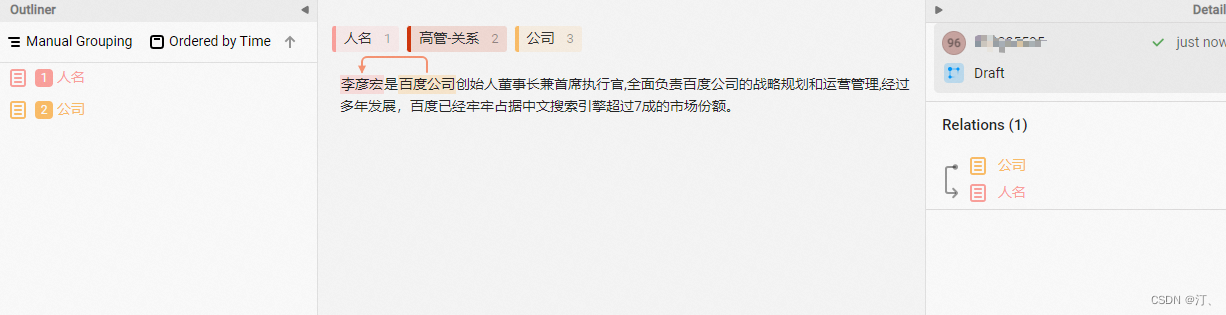
对于关系抽取,其P的类型设置十分重要,需要遵循以下原则
“{S}的{P}为{O}”需要能够构成语义合理的短语。比如对于三元组(S, 父子, O),关系类别为父子是没有问题的。但按照UIE当前关系类型prompt的构造方式,“S的父子为O”这个表达不是很通顺,因此P改成孩子更好,即“S的孩子为O”。合理的P类型设置,将显著提升零样本效果。
该标注示例对应的schema为:
schema = {
'作品名': [
'歌手',
'发行时间',
'所属专辑'
]
}
- 事件抽取

该标注示例对应的schema为:
schema = {
'地震触发词': [
'时间',
'震级'
]
}
- 句子级分类

该标注示例对应的schema为:
schema = '情感倾向[正向,负向]'
- 实体/评价维度分类

该标注示例对应的schema为:
schema = {
'评价维度': [
'观点词',
'情感倾向[正向,负向]'
]
}
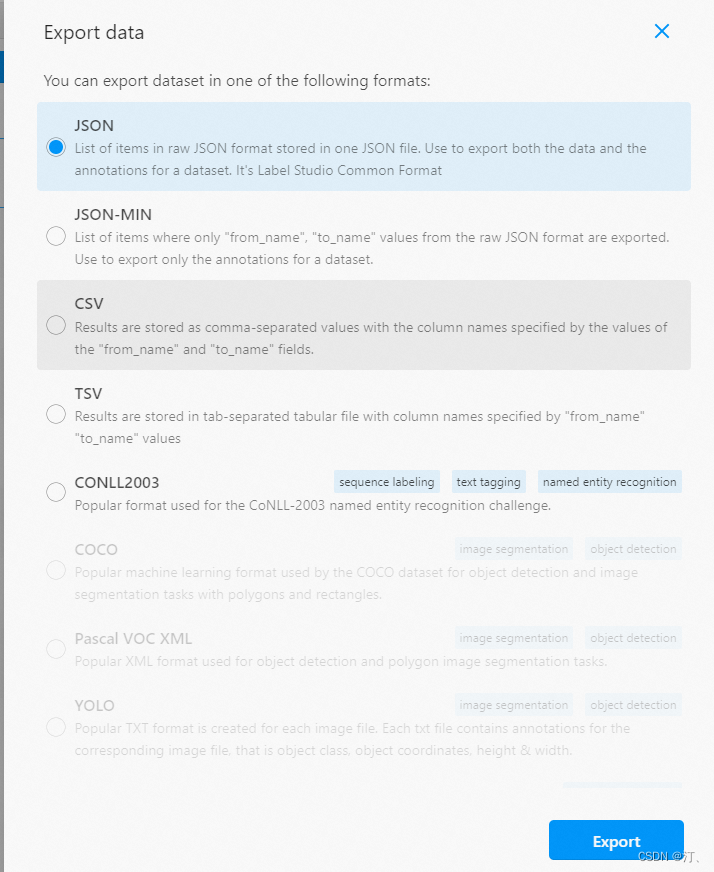
2.5 数据导出
勾选已标注文本ID,选择导出的文件类型为JSON,导出数据:

2.6 数据转换
将导出的文件重命名为label_studio.json后,放入./data目录下。通过label_studio.py脚本可转为UIE的数据格式。
- 抽取式任务
python label_studio.py \
--label_studio_file ./data/label_studio.json \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--task_type ext
- 句子级分类任务
在数据转换阶段,我们会自动构造用于模型训练的prompt信息。例如句子级情感分类中,prompt为情感倾向[正向,负向],可以通过prompt_prefix和options参数进行配置。
python label_studio.py \
--label_studio_file ./data/label_studio.json \
--task_type cls \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--prompt_prefix "情感倾向" \
--options "正向" "负向"
- 实体/评价维度分类任务
在数据转换阶段,我们会自动构造用于模型训练的prompt信息。例如评价维度情感分类中,prompt为XXX的情感倾向[正向,负向],可以通过prompt_prefix和options参数进行声明。
python label_studio.py \
--label_studio_file ./data/label_studio.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--prompt_prefix "情感倾向" \
--options "正向" "负向" \
--separator "##"
2.7 更多配置
label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为["正向", "负向"]。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.schema_lang:选择schema的语言,将会应该训练数据prompt的构造方式,可选有ch和en。默认为ch。separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度分类任务有效。默认为"##"。
备注:
- 默认情况下 label_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 label_studio.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过
negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。 - 对于从label_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。
References
1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等的更多相关文章
- 3.基于Label studio的训练数据标注指南:文本分类任务
文本分类任务Label Studio使用指南 1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取).文本分类等 2.基于Label studio的训练数据标注指南:(智能文档) ...
- 基于Label studio实现UIE信息抽取智能标注方案,提升标注效率!
基于Label studio实现UIE信息抽取智能标注方案,提升标注效率! 项目链接见文末 人工标注的缺点主要有以下几点: 产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模 ...
- 零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程. 1.通用文本分类技术UTC介绍 本项目提供基于通用文本分类 UTC(Universal Text C ...
- label studio 结合 MMDetection 实现数据集自动标记、模型迭代训练的闭环
前言 一个 AI 方向的朋友因为标数据集发了篇 SCI 论文,看着他标了两个多月的数据集这么辛苦,就想着人工智能都能站在围棋巅峰了,难道不能动动小手为自己标数据吗?查了一下还真有一些能够满足此需求的框 ...
- [信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取
[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取 实体关系,实体属性抽取是信息抽取的关键任务:实体关系抽取是指从一段文本中抽取关系三元组,实体属性抽取是指从一段文本中抽取属性三元组: ...
- 基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5196032?contributionType=1 基于ERNIELayout& ...
- 谷歌BERT预训练源码解析(一):训练数据生成
目录预训练源码结构简介输入输出源码解析参数主函数创建训练实例下一句预测&实例生成随机遮蔽输出结果一览预训练源码结构简介关于BERT,简单来说,它是一个基于Transformer架构,结合遮蔽词 ...
- 曼孚科技:数据标注,AI背后的百亿市场
1. 两年前,来自山东农村的王磊成为了一位数据标注员.彼时的他,工作内容非常简单且枯燥:识别图片中人的性别. 然而,一段时间之后,他注意到分配给他的任务开始变得越来越复杂:从识别性别到年龄,从框选 ...
- [入门级] 基于 visual studio 2010 mvc4 的图书管理系统开发初步 (二)
[入门级] 基于 visual studio 2010 mvc4 的图书管理系统开发初步 (二) Date 周六 10 一月 2015 By 钟谢伟 Category website develop ...
- 代码备份:处理 SUN397 的代码,将其分为 80% 训练数据 以及 20% 的测试数据
处理SUN397 的代码,将其分为80% 训练数据以及20% 的测试数据 2016-07-27 1 %% Code for Process SUN397 Scene Classification 2 ...
随机推荐
- python中的代码运行时间获取方式
python中的代码运行时间获取方式 我们知道为了提高代码的运行速度,我们需要对书写的python代码进行性能测试,而代码性能的高低的直接反馈就是电脑运行代码所需要的时间. 使用time模块对代码 ...
- 用 Python 开发了一个 PDF 抽取Excel表格的小工具
大家好哇 从 PDF 里 copy 表格时,粘贴出来后格式都是错乱的.这麻烦事交给 Python 再合适不过里,我开发了一个从 PDF 抽取表格另存为 Excel 文件的应用,我把它部到 huggin ...
- AtCoder ABC 164 (D~E)
比赛链接:Here ABC水题, D - Multiple of 2019 (DP + 分析) 题意: 给定数字串S,计算有多少个子串 \(S[L,R]\) ,满足 \(S[L,R]\) 是 \(2 ...
- Codeforce Problem 711A - Bus to Udayland (正则表达式)
https://codeforces.com/problemset/problem/711/A 正则表达式基本应用 #include<bits/stdc++.h> using namesp ...
- 【每日一题】39. Contest(树状数组 / 容斥分治)
补题链接:Here 算法涉及:树状数组.CDQ分治 n支队伍一共参加了三场比赛. 一支队伍x认为自己比另一支队伍y强当且仅当x在至少一场比赛中比y的排名高. 求有多少组(x,y),使得x自己觉得比y强 ...
- vue setup响应式变量
setup响应式变量 一.非响应式变量 1 效果 开发中发现setup()中的变量居然不是响应式的,值得内容变成1了但是页面上还是0 2.源码 二.响应式变量 1.效果 使用ref()可以声明响应式的 ...
- 嵌入式Linux必读经典书籍(含下载方式)
最近,在知乎看到一个问题,"嵌入式Linux有哪些好书推荐".我读研期间也喜欢收藏一些书籍,每次看到京东有活动,总是忍不住想买一些书籍回来. 随着时间越来越久,我买的书越来越多,但 ...
- vue路由模块化
https://www.bilibili.com/video/BV1Tg411u7oy?from=search&seid=5098139115981575542&spm_id_from ...
- 一次完整的HTTP服务过程
- 基于python+django的旅游信息网站-旅游景点门票管理系统设计与实现
该系统是基于python+django开发的旅游景点门票管理系统.是给师弟做的课程作业.大家学习过程中,遇到问题可以在github咨询作者 演示地址 前台地址: http://travel.gitap ...