ceph存储引擎bluestore解析
原文链接:http://www.sysnote.org/2016/08/19/ceph-bluestore/
ceph后端支持多种存储引擎,以插件式的方式来进行管理使用,目前支持filestore,kvstore,memstore以及最新的bluestore,目前默认使用的filestore,但是因为filestore在写数据前需要先写journal,会有一倍的写放大,并且filestore一开始只是对于机械盘进行设计的,没有专门针对ssd做优化考虑,因此诞生的bluestore初衷就是为了减少写放大,并针对ssd做优化,而且直接管理裸盘,从理论上进一步减少文件系统如ext4/xfs等部分的开销,目前bluestore还处于开发优化阶段,在jewel版本还是试用版本,并且最新的master相比jewel已经做了大的重构,预期会在后续的大版本中稳定下来成为默认的存储引擎。本文基于master分支对bluestore存储引擎进行分析。
bluestore整体架构
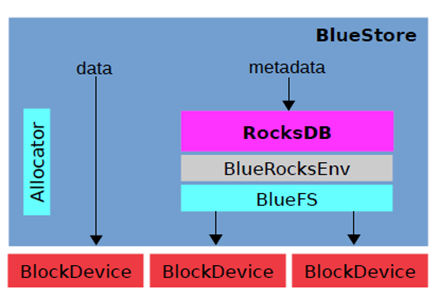
bluestore直接管理裸设备,抛弃了ext4/xfs等本地文件系统,BlockDevice实现在用户态下使用linux aio直接对裸设备进行I/O操作。既然是直接管理裸设备就必然需要进行裸设备的空间管理,对应的就是Allocator,目前支持StupidAllocator和BitmapAllocator两种分配器。相关的元数据以kv的形式保存到kv数据库里,默认使用的是rocksdb,由于rocksdb本身是基于文件系统的,不是直接操作裸设备,但是rocksdb也比较灵活,将系统相关的处理抽象成Env,用户可用实现相应的接口,rocksdb默认的Env是PosixEnv,直接对接本地文件系统,为此,bluestore实现了一个BlueRocksEnv,继承自EnvWrapper,来为rocksdb提供底层系统的封装,为了对接BlueRocksEnv,实现了一个小的文件系统BlueFS,只实现rocksdb Env需要的接口,在系统启动mount这个文件系统的时候将所有的元数据都加载到内存中,BluesFS的数据和日志文件都通过BlockDevice保存到裸设备上,BlueFS和BlueStore可以共享裸设备,也可以分别指定不同的设备。
bluestore元数据

在之前的存储引擎filestore里,对象的表现形式是对应到文件系统里的文件,默认4MB大小的文件,但是在bluestore里,已经没有传统的文件系统,而是自己管理裸盘,因此需要有元数据来管理对象,对应的就是Onode,Onode是常驻内存的数据结构,持久化的时候会以kv的形式存到rocksdb里。
在onode里又分为lextent,表示逻辑的数据块,用一个map来记录,一个onode里会存在多个lextent,lextent通过blob的id对应到blob(bluestore_blob_t ),blob里通过pextent对应到实际物理盘上的区域(pextent里就是offset和length来定位物理盘的位置区域)。一个onode里的多个lextent可能在同一个blob里,而一个blob也可能对应到多个pextent。
另外还有Bnode这个元数据,它是用来表示多个object可能共享extent,目前在做了快照后写I/O触发的cow进行clone的时候会用到。
I/O读写映射逻辑
写I/O处理
到达bluestore的I/O的offset和length都是对象内(onode)的,offset是相对于这个对象起始位置的偏移,在_do_write里首先就会根据最小分配单位min_alloc_size进行判断,从而将I/O分为对齐和非对齐的。如下图所示: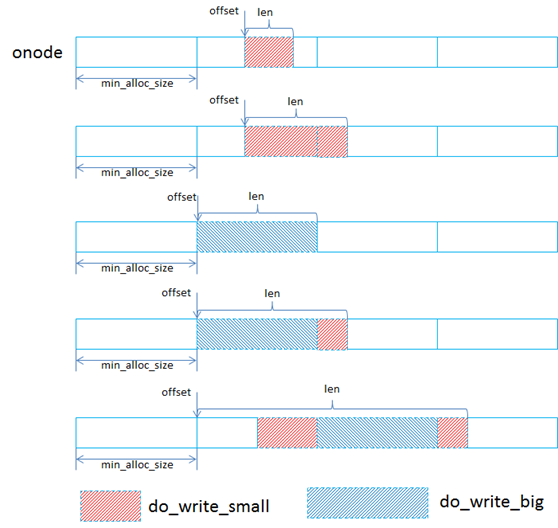
当一个写请求按照min_alloc_size进行拆分后,就会分为对齐写,对应到do_write_big,非对齐写(即落到某一个min_alloc_size区间的写I/O(对应到do_write_small)。
do_write_big
对齐到min_alloc_size的写请求处理起来比较简单,有可能是多个min_alloc_size的大小,在处理时会根据实际大小新生成lextent和blob,这个lextent跨越的区域是min_alloc_size的整数倍,如果这段区间是之前写过的,会将之前的lextent记录下来便于后续的空间回收。
do_write_small
在处理落到某个min_alloc_size区间的写请求时,会首先根据offset去查找有没有可以复用的blob,因为最小分配单元是min_alloc_size,默认64KB,如果一个4KB的写I/O就只会用到blob的一部分,blob里剩余的还能放其他的。
1)没有找到可以复用的blob,新生成blob

在处理还还需要根据offset和len是否对齐到block_size(默认是4KB)进行补零对齐的操作,之所以需要补齐是与后续的写盘操作有关,真正写盘时有两种方式,一种是Direct I/O的方式,这种要求偏移和缓冲区都对齐的,另外一种非Direct I/O,即Buffered I/O,这种可以不对齐,但是是写到cache里,然后再sync刷到磁盘上,比如只写了100字节,在内核里是需要先从设备上读出来补齐成一个完整的扇区,然后再刷的,这样反而降低了效率。因此在bluestore里直接处理好对齐,对于后面的写盘来说比较有利,这里对齐到block_size,是个可配置的参数。
进行对齐补零时就是按照如上图那样把前后对齐到block_size,然后再把对齐后的offset和len作为lextent,进而放到blob里。
2)找到可以复用的blob
对于可以复用的blob,也是先按照block_size进行对齐补零的动作,然后再判断是否可以直接使用blob里空闲的空间进行区分做不同的处理。
a)直接写在blob未使用的空间上
这种情况下直接新生成lextent放到blob里。
b)覆盖写的情况
比如下面的这种情况,写I/O会覆盖部分已经写过的数据。
对于这种情况的处理如下图:也是需要先处理对齐补零的情况,如果覆盖的区域刚好是已经对齐到block_size,那么就不需要从磁盘读数据,但是如果覆盖的区域没有对齐到block_size,那么就需要把不对齐的那部分读出来,拼成一个对齐的buffer,然后新生成lextent,并且会对原来那个lextent进行调整,会记录需要回收的那部分区域。对于覆盖写的情况,都不是直接写盘,而是通过wal写到rocksdb。
整体写I/O的逻辑
之前组内同事画过一个流程图,这里借用一下算是一个简单的总结。
读I/O的处理
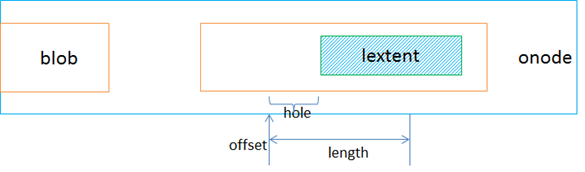
读I/O请求的处理时也是通过寻找相关联的lextent,可能会存在空洞的情况,即读到未写过的数据,这部分就直接补零。
clone及extent共享
前面说到Bnode就是用来记录共享的lextent,目前是在做完快照后对原卷进行写I/O会触发cow,从而产生clone操作。clone时就是将原对象的blob从onode->blob_map移到onode->bnode->blob_map,并且将blob id置为负的,并设置共享标记,然后将新的快照对象的onode->bnode指向原对象的onode->bnode,并且用原onode里的lextents里的值赋给新的onode的lextents,从而达到共享extent的目的,图示仅供参考。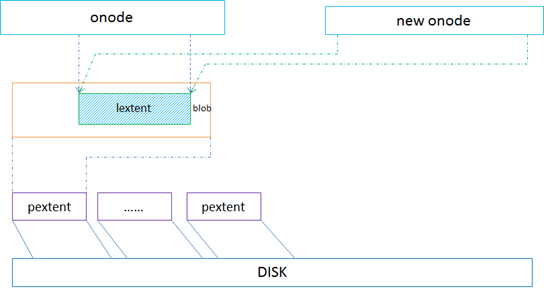
在clone完之后,继续对原对象进行写I/O操作时,当碰到共享的blob时就需要跳过,新生成blob,并且取消对原来那部分lextent的引用,在后续的空间释放时的判断依据就是否还有引用。
小结
本文总体上介绍了bluestore的架构、相关元数据及内部I/O映射的逻辑,这还只是bluestore的冰山一角,后续会陆续对bluestore的处理流程、空间分配器、缓存管理、压缩等实现进行分析。
ceph存储引擎bluestore解析的更多相关文章
- 解析CEPH: 存储引擎实现之一 filestore
Ceph作为一个高可用和强一致性的软件定义存储实现,去使用它非常重要的就是了解其内部的IO路径和存储实现.这篇文章主要介绍在IO路径中最底层的ObjectStore的实现之一FileStore. Ob ...
- SQL学习笔记三(补充-1)之MySQL存储引擎
阅读目录 一 什么是存储引擎 二 mysql支持的存储引擎 三 使用存储引擎 一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的 ...
- mysql三-1:存储引擎
一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型 ...
- mysql数据库从删库到跑路之mysql存储引擎
一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件应该有不同的类型:比如存文本用txt类型,存表格用excel,存图片用pn ...
- mysql 库操作、存储引擎、表操作
阅读目录 库操作 存储引擎 什么是存储引擎 mysql支持的存储引擎 如何使用存储引擎 表操作 创建表 查看表结构 修改表ALTER TABLE 复制表 删除表 数据类型 表完整性约束 回到顶部 一. ...
- DAY10-MYSQL存储引擎
一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型 ...
- MySQL三:存储引擎
阅读目录 一 什么是存储引擎 二 mysql支持的存储引擎 三 使用存储引擎 一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的 ...
- mysql 三存储引擎
一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型 ...
- Mysql(三)-1:存储引擎
一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型 ...
随机推荐
- Mybatis源码分析-StatementHandler
承接前文Mybatis源码分析-BaseExecutor,本文则对通过StatementHandler接口完成数据库的CRUD操作作简单的分析 StatementHandler#接口列表 //获取St ...
- 打鼹鼠 HNOI 2004
动态规划题从题目中可以发现是一个时间递增的过程,所以只要是在后面的点都是后出现的,换句话说,在条件达成时,前面的点可以到达后面的点,求最长的一条链,非常的像LIS(最长上升子序列),只要将 f[i]& ...
- 阅读:DBA们不得不知的数据库硬件RAID常识
对于数据库这种特殊应用IOPS往往会成为瓶颈,突破的这个瓶颈的有效方法不多,软件方面主要是读写分离,垂直拆分,分区表技术,cluster.硬件方面主要是raid,和SSD. 通常都是软件和硬件同时优化 ...
- css3动画2D、3D转换
css3动画的2D.3D转换代码: <!DOCTYPE html> <html lang="en"> <head> <meta chars ...
- Command "python setup.py egg_info" failed with error code 1一种问题的解决方法
问题描述:无论是你在pycharm中直接使用import and install命令,还是pip的时候出现了Command "python setup.py egg_info" f ...
- 设计模式(4)建造者模式/生成器模式(Builder)
设计模式(0)简单工厂模式 设计模式(1)单例模式(Singleton) 设计模式(2)工厂方法模式(Factory Method) 设计模式(3)抽象工厂模式(Abstract Factory) 源 ...
- Java中几种常量池的区分
转载自:https://tangxman.github.io/2015/07/27/the-difference-of-java-string-pool/ 在java的内存分配中,经常听到很多关于常量 ...
- Git SSH Key 生成步骤及使用
Git是分布式的代码管理工具,远程的代码管理是基于SSH的,所以要使用远程的Git则需要SSH的配置. github的SSH配置如下: 一 . 设置Git的user name和email: $ git ...
- LAMP环境的搭建(四)----Apache下部署项目
根据前文完成了LAMP基本环境的安装,那么接下来就是部署线上的环境了. yum 安装的apache 目录存在于 /etc/httpd apache最重要的文件就是 httpd.conf. 目录再 ...
- vue-cli脚手架npm相关文件解读(3)webpack.dev.conf.js
系列文章传送门: 1.build/webpack.base.conf.js 2.build/webpack.prod.conf.js 3.build/webpack.dev.conf.js 4.bui ...