实现径向变换用于样本增强《Training Neural Networks with Very Little Data-A Draft》
背景:
做大规模机器学习算法,特别是神经网络最怕什么——没有数据!!没有数据意味着,机器学不会,人工不智能!通常使用样本增强来扩充数据一直都是解决这个问题的一个好方法。
最近的一篇论文《Training Neural Networks with Very Little Data-A Draft》提出了一个新的图像样本增强方法:对图像使用径向变换生成不同“副本”,解决样本数量太少难以训练的问题。论文地址:https://arxiv.org/pdf/1708.04347.pdf
该论文提出将图片的直角坐标按指定中心点转换为极坐标来重构图像,从而在不同中心点位置的情况下得到一张图片的多个增强样本,实际就是选取不同的点做圆心,将图像在圆心处展开。

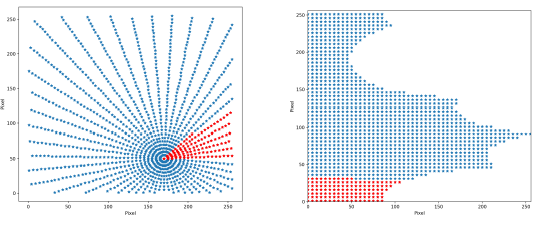
实现:
论文提供了伪代码,按照伪代码直接写出Python代码很容易:


但事情并没有那么简单!上面的代码输出的是这个样子:
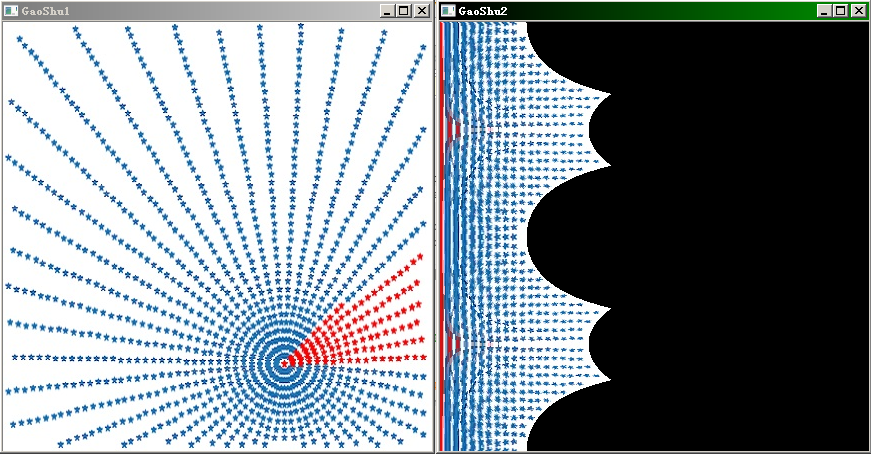
喵!
看了网上一些实现,图形也不对。只能再仔细检查了一遍。。然后。。发现论文里的“|| ||”原来是取整。。而且作者的直角坐标原点是图的左下角而我们代码是左上角。。
修改:
知道了问题所在修改一下代码就ok了。去掉abs(),再交换cos和sin
def RT(img, center=(0, 0)):
U, V, p = img.shape
RTimg = img.copy() - img
m, n = center
for u in range(U):
d = 2 * math.pi * u / U
for v in range(V):
x = v * math.sin(d)
y = v * math.cos(d)
mm = int(math.floor(m + x))
nn = int(math.floor(n + y))
if mm>=0 and mm<U and nn>=0 and nn<V:
RTimg[u, v, :] = img[mm, nn, :]
return RTimg
再跑一次图,center取图上圆心坐标:
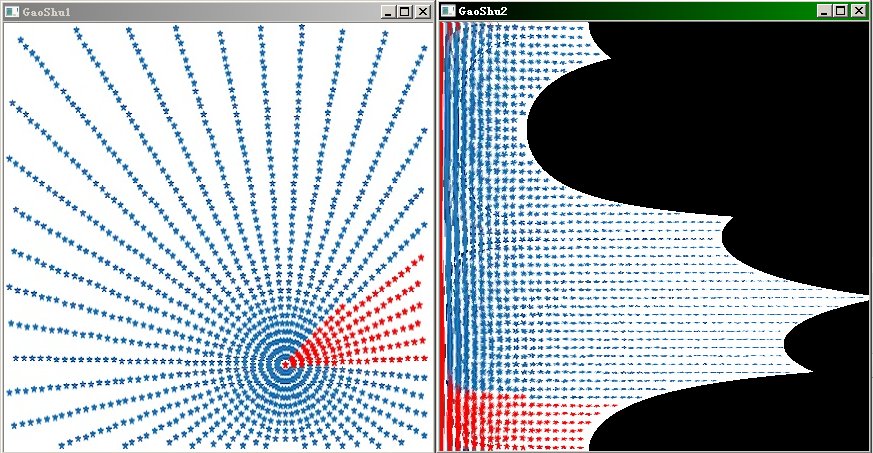
完美!
再来增强一波明星图,最近很火的。。
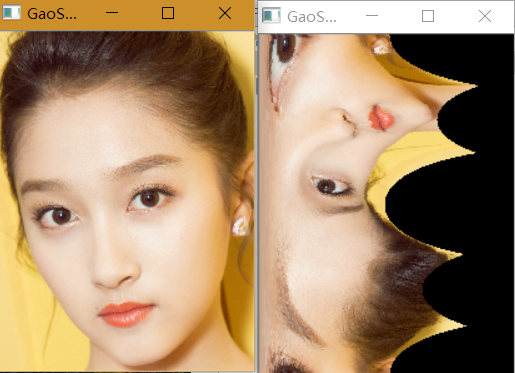
快跑。。
思考:
个人理解该方法在取点时,越靠近圆心点越密集,相当于有目标的非均匀采样,中心点附近的样本点在变换后占图像比重更大。如下图中黄色区域,点要比外部更密集。
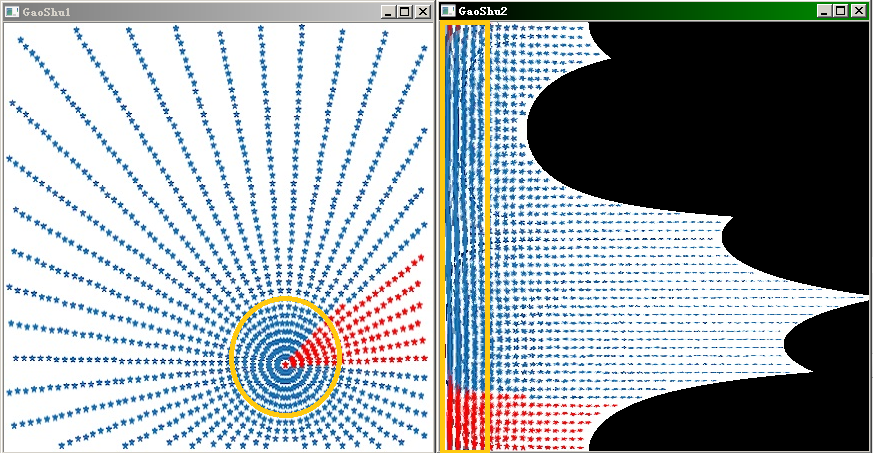
这种做法相当于强化中心点附近区域在模型训练中的贡献,与deepid2中对同一张图片切分不同patch用于训练有异曲同工的效果。相较之下这种方法还会保留部分其他非中心区域的信息,考虑更全面。
至于实际用于训练的效果,小霸王cpu,数据集还没转完,再议。
原创,转载请声明。完工跑路
实现径向变换用于样本增强《Training Neural Networks with Very Little Data-A Draft》的更多相关文章
- A Recipe for Training Neural Networks [中文翻译, part 1]
最近拜读大神Karpathy的经验之谈 A Recipe for Training Neural Networks https://karpathy.github.io/2019/04/25/rec ...
- (转)A Recipe for Training Neural Networks
A Recipe for Training Neural Networks Andrej Karpathy blog 2019-04-27 09:37:05 This blog is copied ...
- 1506.01186-Cyclical Learning Rates for Training Neural Networks
1506.01186-Cyclical Learning Rates for Training Neural Networks 论文中提出了一种循环调整学习率来训练模型的方式. 如下图: 通过循环的线 ...
- Training Neural Networks: Q&A with Ian Goodfellow, Google
Training Neural Networks: Q&A with Ian Goodfellow, Google Neural networks require considerable t ...
- [CS231n-CNN] Training Neural Networks Part 1 : activation functions, weight initialization, gradient flow, batch normalization | babysitting the learning process, hyperparameter optimization
课程主页:http://cs231n.stanford.edu/ Introduction to neural networks -Training Neural Network ________ ...
- [Converge] Training Neural Networks
CS231n Winter 2016: Lecture 5: Neural Networks Part 2 CS231n Winter 2016: Lecture 6: Neural Networks ...
- [转]Binarized Neural Networks_ Training Neural Networks with Weights and Activations Constrained to +1 or −1
原文: 二值神经网络(Binary Neural Network,BNN) 在我刚刚过去的研究生毕设中,我在ImageNet数据集上验证了图像特征二值化后仍然具有很强的表达能力,可以在检索中达到较好的 ...
- [CS231n-CNN] Training Neural Networks Part 1 : parameter updates, ensembles, dropout
课程主页:http://cs231n.stanford.edu/ ___________________________________________________________________ ...
- cs231n spring 2017 lecture7 Training Neural Networks II 听课笔记
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
随机推荐
- 极化码的matlab仿真(2)——编码
第二篇我们来介绍一下极化码的编码. 首先为了方便进行编码,我们需要进行数组的定义 signal = randi([0,1],1,ST); %信息位比特,随机二进制数 frozen = zeros(1, ...
- 深入剖析ConcurrentHashMap 一
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt201 ConcurrentHashMap是Java5中新增加的一个线程安全的 ...
- 关于 String.intern() 的思考
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt399 我看到一个问题 https://segmentfault.com/q/ ...
- 闭锁——CountDownLatch
一.概念 闭锁是一个同步工具类,主要用于等待其他线程活动结束后,再执行后续的操作.例如:在王者荣耀游戏中,需要10名玩家都准备就绪后,游戏才能开始. CountDownLatch是concurrent ...
- poj 1742 多重背包
题意:给出n种面值的硬币, 和这些硬币每一种的数量, 要求求出能组成的钱数(小于等于m) 思路:一开始直接用多重背包套上去超时了,然后就没辙了,然后参考网上的,说只需要判断是否能取到就行了,并不需要记 ...
- 201521123014 《Java程序设计》第5周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关多态与接口的知识点. 2. 书面作业 Q1. 代码阅读:Child压缩包内源代码 1.1 com.parent包中Child.java文件能否编译通 ...
- 201521123079《java程序设计》第10周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常与多线程相关内容. 1.实现多线程的方式: 方式一:继承Thread类 a.自定义类继承Thread类 b.在自定义类中重写ru ...
- linux下修改rm命令防止误删除
前言:相信很多朋友都遇到过在linux下用rm命令误删除文件的时候,此刻的心中仿佛有无数的羊驼在奔腾.那么怎么防止这种情况发生呢?当然是有方法的,我们可以写一个shell脚本,改变一下rm命令的作用. ...
- 1-SDK开发初探-8266
先分享一个比较感动的事情 其实做实物是因为好多人看了我的文章之后还是会遇到各种各样的问题,然后呢真是让亲们搞的自己好累.......所以就想着如果亲们用自己做的板子,出现什么问题能够快速的解决,,而且 ...
- temp-重庆农商行二次出差
1, 住宿(远舰商务酒店) 与胡仕川一起住 1722房间, 178-27=151(返现后). 7月30日 7月31日 8月1日 8月2日 8月3日 2, 住宿(郎菲酒店)一个人住, 158 ...