【Python基础】lpthw - Exercise 46 项目骨架
本节将会介绍如何构建一个项目骨架目录。骨架目录中会包含项目文件布局、自动测试代码、模块及安装脚本。
一、环境配置(win10)
1. 检查并确认自己只安装了一个python版本。
cd ~
python
可以检查python版本。
2. 运行pip,确认有基本的安装。
>pip list
pip(version xxx.xxx)
setuptools(version xxx.xxx)
3. 使用下述命令设置虚拟环境
> pip install virtualenv
4. 创建一个.venvs文件夹,在里面装虚拟环境
> mkdir .venvs
> virtualenv --system-site-packages .venvs/lpthw
这两个命令创建了一个.venvs文件夹,用来存储不同的虚拟环境,然后创建了第一个虚拟环境lpthw。虚拟环境是一个用来安装软件的“假的”地方,这样我们就可以针对不同项目使用不同版本的软件包。
5. 安装完成后需要激活虚拟环境
先cd到.venvs所在目录,然后执行以下命令进行激活:
> .\.venvs\lpthw\Scripts\activate
这样就为PowerShell运行activate脚本,它把你当前的shell设为使用lpthw虚拟环境,以后每次使用书中的软件,都要先激活虚拟环境。
需要注意的是,win10下还需要开启PS不能运行脚本的问题。方法为管理员身份运行PowerShell,并运行以下命令
> set-executionpolicy remotesigned
6. 安装nose,以供后面运行测试使用
> pip install nose
这样nose就安装完毕了,只不过pip将其安装到了.venvs/lpthw的虚拟环境下面,而非主系统软件包目录。这样你就可以为不同项目安装不同的相互冲突的Python软件包版本,同时还不会污染主系统级别的配置。
二、创建骨架项目目录
1. 创建骨架目录
> mkdir projects
> cd projects
> mkdir skeleton
> cd skeleton
> mkdir -p bin,NAME,tests,docs
注意mkdir同时创建多个文件需要使用-p参数,并用逗号隔开文件名。
projects用来存储各个项目。skeleton是本节新项目的基础目录。其中NAME目录是项目的主模块,使用骨架时,可以将其重命名为自己的项目的主模块名称。
2. 设置初始文件
创建一些空的python模块目录:
> new-item -type file NAME/__init__.py
> new-item -type file tests/__init__.py
在skeleton目录下创建一个setup.py文件,这个文件在安装项目的时候会用到,其内容如下:
try:
from setuptools import setup
except ImportError:
from distutils.core import setup config = {
'description': 'My Project',
'author': 'Crystal',
'url': 'URL to get it at.',
'downloard_url': 'Where to download it.',
'author_email': 'my_email@xx.xx',
'version': '1.0',
'install_requires': ['nose'],
'packages': ['NAME'],
'scripts': [],
'name': 'projectname'
} setup(**config)
3. 建立测试专用的骨架文件
在tests文件夹下建立一个NAME_tests.py,内容如下:
from nose.tools import *
import NAME def setup():
print("SETUP!") def teardown():
print("TEAR DOWN!") def test_basic():
print("I RAN!")
4. 最终的目录结构
完成上述步骤后的目录结构应该如下所示:
skeleton/
NAME/
__init__.py
bin/
docs/
tests/
NAME_tests.py
__init__.py
setup.py
5. 运行测试程序
注意一定要在skeleton目录下运行,而非tests目录下。
> nosetests
.
----------------------------------
Ran 1 test in 0.007s OK
三、使用这个骨架
以后每次要新建一个项目时,遵循以下步骤即可:
1. 复制这份骨架目录,把名字改成新项目的名字
2. 将NAME目录更名为自己的项目的名字,或根模块的名字
3. 编辑setup.py,将其包含的信息更新为新项目的信息
4. 重命名tests/NAME_tests.py,把NAME换成2中所说的模块的名字
5. 使用nosetests检查有无错误
6. 开始写代码
四、setup.py——python的构建工具
【摘录自博客 https://www.cnblogs.com/maociping/p/6633948.html】
在安装python的相关库时,可以有以下两种安装方式
pip install 模块名
这种方法为在线安装,会安装该模块的相关依赖包。
python setup.py install 模块名
这种方法为下载源码后在本地安装,不会安装相关的依赖包。
在安装普通的python包时,利用pip来安装是很方便的,但是在有的场景下,使用后者会更加满足我们的需要,例如:
在本机开发一个程序,需要用到python的官方模块,以及自己编写的自定义模块。那么如何实现在服务器上去发布该系统,实现依赖模块和自定义模块一起打包和一键安装呢?也就是如何同时将自己编写的自定义模块以exe文件格式安装到python的全局执行路径C:\Python37\Scripts下呢?
此时,pip工具似乎派不上用场,只能使用setup.py。我们只需要在setup.py文件中写明依赖的库和版本,然后到目标机器上使用python setup.py install 安装。
示例:
from setuptools import setup, find_packages setup(
name = "test",
version = "1.0",
keywords = ("test", "xxx"),
description = "eds sdk",
long_description = "eds sdk for python",
license = "MIT Licence", url = "http://test.com",
author = "test",
author_email = "test@gmail.com", packages = find_packages(),
include_package_data = True,
platforms = "any",
install_requires = [], scripts = [],
entry_points = {
'console_scripts': [
'test = test.help:main'
]
}
)
参数介绍:
--name 包名称
--version (-V) 包版本
--author 程序的作者
--author_email 程序的作者的邮箱地址
--maintainer 维护者
--maintainer_email 维护者的邮箱地址
--url 程序的官网地址
--license 程序的授权信息
--description 程序的简单描述
--long_description 程序的详细描述
--platforms 程序适用的软件平台列表
--classifiers 程序的所属分类列表
--keywords 程序的关键字列表
--packages 需要处理的包目录(包含__init__.py的文件夹)
--py_modules 需要打包的python文件列表
--download_url 程序的下载地址
--cmdclass
--data_files 打包时需要打包的数据文件,如图片,配置文件等
--scripts 安装时需要执行的脚步列表
--package_dir 告诉setuptools哪些目录下的文件被映射到哪个源码包。一个例子:package_dir = {'': 'lib'},表示“root package”中的模块都在lib 目录中。
--requires 定义依赖哪些模块
--provides定义可以为哪些模块提供依赖
--find_packages() 对于简单工程来说,手动增加packages参数很容易,刚刚我们用到了这个函数,它默认在和setup.py同一目录下搜索各个含有 __init__.py的包。其实我们可以将包统一放在一个src目录中,另外,这个包内可能还有aaa.txt文件和data数据文件夹。另外,也可以排除一些特定的包 find_packages(exclude=["*.tests", "*.tests.*", "tests.*", "tests"])
--install_requires = ["requests"] 需要安装的依赖包
--entry_points 动态发现服务和插件
在前述entry_points中:
console_scripts 指明了命令行工具的名称;在“redis_run=RedisRun.redis_run:main”中,等号前面指明了工具包的名称,等号后面的内容指明了程序的入口地址。
这里也可以有多条记录,这样一个项目就可以制作多个命令行工具了,如
setup(
entry_points = {
'console_scripts': [
'foo = demo:test',
'bar = demo:test',
]}
)
setup.py项目示例代码:
#!/usr/bin/env python
# coding=utf-8 from setuptools import setup '''
把redis服务打包成C:\Python27\Scripts下的exe文件
''' setup(
name="RedisRun", #pypi中的名称,pip或者easy_install安装时使用的名称,或生成egg文件的名称
version="1.0",
author="Andreas Schroeder",
author_email="andreas@drqueue.org",
description=("This is a service of redis subscripe"),
license="GPLv3",
keywords="redis subscripe",
url="https://ssl.xxx.org/redmine/projects/RedisRun",
packages=['RedisRun'], # 需要打包的目录列表 # 需要安装的依赖
install_requires=[
'redis>=2.10.5',
'setuptools>=16.0',
], # 添加这个选项,在windows下Python目录的scripts下生成exe文件
# 注意:模块与函数之间是冒号:
entry_points={'console_scripts': [
'redis_run = RedisRun.redis_run:main',
]}, # long_description=read('README.md'),
classifiers=[ # 程序的所属分类列表
"Development Status :: 3 - Alpha",
"Topic :: Utilities",
"License :: OSI Approved :: GNU General Public License (GPL)",
],
# 此项需要,否则卸载时报windows error
zip_safe=False
)
修改后的项目代码(此时RedisRun模块是DrQueue模块的子模块,这是因为要导入某些公用的模块)
#!/usr/bin/env python
# coding=utf-8 from setuptools import setup '''
把redis服务打包成C:\Python27\Scripts下的exe文件
''' setup(
name="RedisRun", #pypi中的名称,pip或者easy_install安装时使用的名称
version="1.0",
author="Andreas Schroeder",
author_email="andreas@drqueue.org",
description=("This is a service of redis subscripe"),
license="GPLv3",
keywords="redis subscripe",
url="https://ssl.xxx.org/redmine/projects/RedisRun",
packages=['DrQueue'], # 需要打包的目录列表 # 需要安装的依赖
install_requires=[
'redis>=2.10.5',
], # 添加这个选项,在windows下Python目录的scripts下生成exe文件
# 注意:模块与函数之间是冒号:
entry_points={'console_scripts': [
'redis_run = DrQueue.RedisRun.redis_run:main',
]}, # long_description=read('README.md'),
classifiers=[ # 程序的所属分类列表
"Development Status :: 3 - Alpha",
"Topic :: Utilities",
"License :: OSI Approved :: GNU General Public License (GPL)",
],
# 此项需要,否则卸载时报windows error
zip_safe=False
)
此时项目的目录结构为:
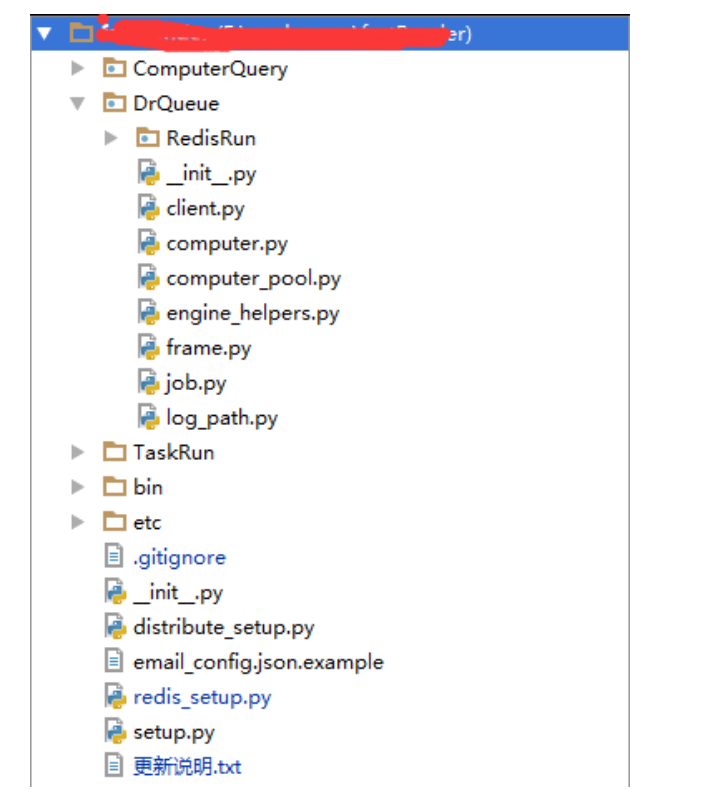
五、进一步的工作
1. 在模块目录NAME下面写一些代码,并让其可以运行。
2. 在bin目录下方写一个可以运行的脚本,并在setup.py里配置好bin中的脚本的信息。
注意,bin中存放的一般是一些在命令行上运行的脚本,而不是模块;模块可以放在setup.py的同级目录下,且其必须包含__init__.py。
前面提到,包含__init__.py的会被认为是一个模块(包),find_packages()就是搜索所有包含__init__.py的文件夹,并认为其是一个模块,然后在setup的时候一并安装。
3. 使用setup.py安装自定义的模块,并确保安装的模块可以正常使用,最后使用pip将其卸载。
cd 到setup.py目录下,执行以下命令(为保证不污染主环境,先激活lpthw虚拟环境!)
> python setup.py install
此时安装好了名字为NAME的模块(可以有和NAME类似的其他文件夹,其中也需包含__init__.py,setup后可以根据其名字import)。
import NAME
...
使用pip卸载该包的命令如下
> pip uninstall projectname
这个projectname参见前面setup.py中的配置。
【Python基础】lpthw - Exercise 46 项目骨架的更多相关文章
- python基础1 - 多文件项目和代码规范
1. 多文件项目演练 开发 项目 就是开发一个 专门解决一个复杂业务功能的软件 通常每 一个项目 就具有一个 独立专属的目录,用于保存 所有和项目相关的文件 – 一个项目通常会包含 很多源文件 在 ...
- Python基础:模块化来搭项目
简单模块化 import 最好在最顶端 sys.path.append("..")表示把当前程序所在位置向上提了一级 在python3规范中,__init__.py并不是必须的. ...
- 10个Python基础练习项目,你可能不会想到练手教程还这么有趣
美国20世纪最重要的实用主义哲学家约翰·杜威提出一个学习方法,叫做:Learning By Doing,在实践中精进.胡适.陶行知.张伯苓.蒋梦麟等都曾是他的学生,杜威的哲学也影响了蔡元培.晏阳初等人 ...
- python基础教程项目五之虚拟茶话会
python基础教程项目五之虚拟茶话会 几乎在学习.使用任何一种编程语言的时候,关于socket的练习从来都不会少,尤其是会写一些局域网的通信的东西.所以书上的这个项目刚好可以练习一下socket编程 ...
- Python基础+Pythonweb+Python扩展+Python选修四大专题 超强麦子学院Python35G视频教程
[保持在百度网盘中的, 可以在观看,嘿嘿 内容有点多,要想下载, 回复后就可以查看下载地址,资源收集不易,请好好珍惜] 下载地址:http://www.fu83.cc/ 感觉文章好,可以小手一抖 -- ...
- Python之路【第二篇】:Python基础
参考链接:老师 BLOG : http://www.cnblogs.com/wupeiqi/articles/4906230.html 入门拾遗 一.作用域 只要变量在内存中就能被调用!但是(函数的栈 ...
- Python之路,Day4 - Python基础4 (new版)
Python之路,Day4 - Python基础4 (new版) 本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 ...
- Day4 - Python基础4 迭代器、装饰器、软件开发规范
Python之路,Day4 - Python基础4 (new版) 本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 ...
- (路-莫)-Python基础一
一,Python介绍 1,python的出生与应用 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打 ...
随机推荐
- sysbench0.4.12测试query_cache_size和query_cache_type
建议: query_cache_size和query_cache_type生产环境中关闭. (1)软件包下载地址: https://dev.mysql.com/downloads/benchmarks ...
- 数据管理必看!Kendo UI for jQuery过滤器概述
Kendo UI for jQuery最新试用版下载 Kendo UI目前最新提供Kendo UI for jQuery.Kendo UI for Angular.Kendo UI Support f ...
- VUE-文本-事件-属性指令
一.Vue文本指令 文本指令: 1.{{ }} 2.v-text:不能解析html语法的文本,会原样输出 3.v-html:能解析html语法的文本 4.v-once:处理的标签的内容只能被解析一次 ...
- 报错:required string parameter XXX is not present
报错:required string parameter XXX is not present 不同工具发起的get/delete请求,大多数不支持@RequestParam,只支持@PathVari ...
- 数据类型之字符串类型与Number类型
㈠字符串类型 ⑴在JS中字符串需要使用引号引起来 ⑵使用双引号或单引号都可以,但是不要混着用 ⑶引号不能嵌套,双引号不能放双引号,单引号不能放单引号 ⑷在字符串中,可以使用“\”作为转义字符,当表示一 ...
- Linux系统启动顺序
Linux启动顺序 加电—加电自检(BIOS)—硬件检查 —MBR(找到需要启动的系统,由于实际计算机上可能会装有多个系统) —bootloader系统初始化,装载kenel到内存 —内核执行,决定哪 ...
- zabbix服务端接收的数据类型,便于编写脚本向服务端提交数据
1.数据类型1:zabbix_agent执行脚本提交字典 UserParameter=tcp_port_listen,/usr/local/zabbix/share/script/get_game_p ...
- ngx_http_auth_request自用
server { listen 80; server_name www.php12.cn php12.mama1314.com; root /var/www/shf; location / { ind ...
- Vue_(组件)自定义指令
Vue.js自定义指令 传送门 自定义指令:除了内置指令,Vue也允许用户自定义指令 注册指令:通过全局API Vue.directive可以注册自定义指令 自定义指令的钩子函数参数:自定义指令的钩子 ...
- HNOI2015菜肴制作
一开始,没想出来,先topsort判环,把impossible拿到手,然后划分联通块,对每个联通块跑一遍topsort,觉得可对了,然后被大样例教育明白了,知道自己的策略错在哪了. 接着在纸上疯狂手模 ...