python爬虫概述
爬虫的使用:爬虫用来对网络的数据信息进行爬取,通过URL的形式,将数据保存在数据库中并以文档形式或者报表形式进行展示。
爬虫可分为通用式爬虫或特定式爬虫,像我们经常用到的搜索引擎就属于通用式爬虫,如果针对某一特定主题或者新闻进行爬取,则属于特定式爬虫。
一般用到的第三方库有urllib、request、BeautifuiSoup。经常用到的框架为Scrapy和PySpider
爬虫的爬取步骤:
- 获取指定的url链接,获得链接网址上的所有代码信息。
- 通过python的正则表达式,将嵌套的HTML代码和数据进行分离。
- 获取数据后,保存在文档或者数据库中。方便后续的展示。
正常的网络传输大致分为Request(请求)和Response(响应)两类。
正常的HTTP请求一般分为get和post方法#
#使用urllib2编写最简单的爬虫代码
from urllib import request as urllib2
#在进行url请求时,应该添加User-Agent头进行识别
header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Window
s NT 6.1; Trident/5.0;"}
request = urllib2.Request("http://www.baidu.com",headers=header )
response = urllib2.urlopen(request)
html = response.read()
print (html)
我们爬取的数据可分为结构化和非结构化两种
- 结构化数据:XML\JSON格式文件
- 非结构化数据:文本、图片、HTML文件
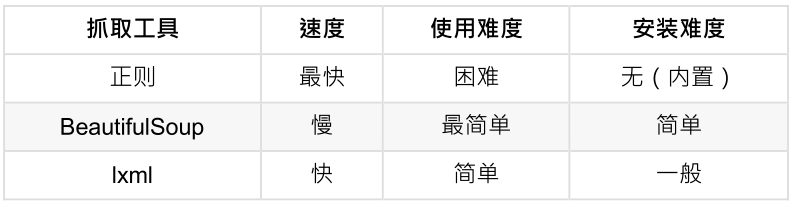
lxml VS BeautifulSoup
lxml为局部遍历,效率较高。而BeautifulSoup为全局遍历,基于HTML DOM的,性能较差。
#使用requests编写爬虫代码
import requests
r = requests.get("http://www.baidu.com")
print(r.status_code) #输出状态码
print(r.text) #输出返回文本
print(r.json) #输出json格式文件
print(r.url) #输出访问的url地址
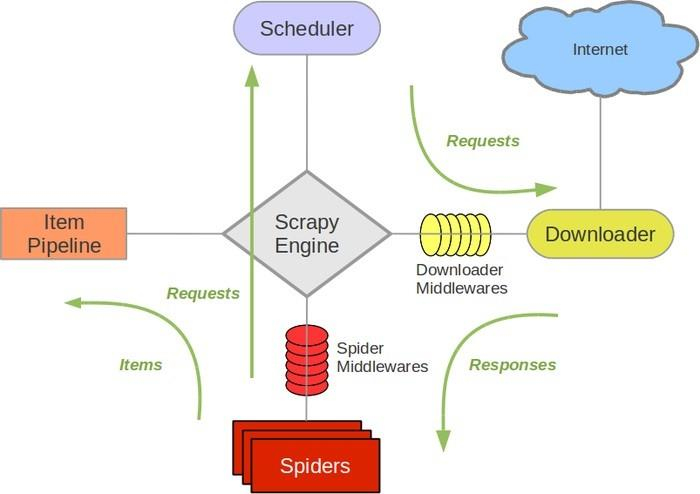
Scrapy架构图
Engine:负责其他组件的运转流程调度。
Scheduler:接收引擎发过来的request请求,并对其进行整理排列。当需要时返还。
Downloader:下载引擎所发送的Requests请求,并将获得的Response交给引擎,由Spider来处理。
Spider:负责从Response中提取Item中需要的数据,并将其他的URL提交给引擎,再转交给Scheduler。
Item PipeLine:负责处理Spider中的Item,并进行后期处理。
Downloader Middlewares:扩展下载功能组件
Spider Middlewares:扩展引擎和Spider通信的功能组件
Scrapy不支持分布式,Scrapy-redis提供了以redis为基础的组件
反爬虫策略:
- 动态设置User-Agent(浏览器识别)
- 禁用cookies
- 使用VPN和代理IP
反爬虫科普:https://segmentfault.com/a/1190000005840672
python爬虫概述的更多相关文章
- 【网络爬虫】【python】网络爬虫(一):python爬虫概述
python爬虫的实现方式: 1.简单点的urllib2 + regex,足够了,可以实现最基本的网页下载功能.实现思路就是前面java版爬虫差不多,把网页拉回来,再正则regex解析信息--总结起来 ...
- 芝麻软件: Python爬虫进阶之爬虫框架概述
综述 爬虫入门之后,我们有两条路可以走. 一个是继续深入学习,以及关于设计模式的一些知识,强化Python相关知识,自己动手造轮子,继续为自己的爬虫增加分布式,多线程等功能扩展.另一条路便是学习一些优 ...
- Python爬虫进阶一之爬虫框架概述
综述 爬虫入门之后,我们有两条路可以走. 一个是继续深入学习,以及关于设计模式的一些知识,强化Python相关知识,自己动手造轮子,继续为自己的爬虫增加分布式,多线程等功能扩展.另一条路便是学习一些优 ...
- Python爬虫之12306-分析请求总概述
python爬虫也学了一段时间了.也爬过不少网站,最后我想用12306抢票器这个项目做一个对之前的学习的效果成见也是一个目标(开始学爬虫的时候,看到说,会爬12306,就会爬80%的网站),本人纯自学 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- 【Python】【爬虫】如何学习Python爬虫?
如何学习Python爬虫[入门篇]? 路人甲 1 年前 想写这么一篇文章,但是知乎社区爬虫大神很多,光是整理他们的答案就够我这篇文章的内容了.对于我个人来说我更喜欢那种非常实用的教程,这种教程对于想直 ...
- python爬虫的教程
来源:http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一 ...
- Python爬虫系列 - 初探:爬取旅游评论
Python爬虫目前是基于requests包,下面是该包的文档,查一些资料还是比较方便. http://docs.python-requests.org/en/master/ POST发送内容格式 爬 ...
随机推荐
- pycharm pro版server激活
从网上搜集了一些 License server 地址(有钱的一定要支持正版哦) http://idea.iteblog.com/key.php http://intellij.mandroid.cn ...
- .NET Core 3时代如何转换.NET 4项目,DevExpress Winforms帮你忙!
DevExpress Winforms Controls 内置140多个UI控件和库,完美构建流畅.美观且易于使用的应用程序.无论是Office风格的界面,还是分析处理大批量的业务数据,DevExpr ...
- nginx第七天
nginx的proxy_buffering和proxy_cache 两个都是nginx代理中内存设置相关的参数. proxy_buffering设置 proxy_buffering主要是实现被代理服务 ...
- [Algorithm] Area of polygon
How to calculate the area of polygon. For a triangle like: We can calculate the area: function cross ...
- CodeForces 788B - Weird journey [ 分类讨论 ] [ 欧拉通路 ]
题意: 给出无向图. good way : 仅有两条边只经过一次,余下边全经过两次的路 问你共有多少条不同的good way. 两条good way不同仅当它们所经过的边的集合中至少有一条不同 (很关 ...
- Linux通过秘钥远程连接
1. 秘钥生成命令 ssh-keygen 执行完上述的命令就会在root目录下生成公钥跟私钥文件 /root/.ssh/.id_rsa 私钥 /root/.ssh/.id_rsa.pub 公钥 ...
- ant-design-vue 报错 ReferenceError: h is not defined
使用表格,在配置 columns时用到了 customRender,然后就报错了 <script> import FileName from '@/views/admin/document ...
- 顺序表应用6:有序顺序表查询(SDUT 3330)
Problem Description 顺序表内按照由小到大的次序存放着n个互不相同的整数,任意输入一个整数,判断该整数在顺序表中是否存在.如果在顺序表中存在该整数,输出其在表中的序号:否则输出&qu ...
- XOR Guessing
E. XOR Guessing 第一次做这种交互题,刚开始还看不懂,现在已经差不多可以理解了,清空缓存区用cout<<endl;即可,需要注意的是,如果用fflush(stdout)来 ...
- CLOB、BLOB , CLOB与BLOB的区别
CLOB 定义 数据库中的一种保存文件所使用的类型. Character Large Object SQL 类型 CLOB 在 JavaTM 编程语言中的映射关系.SQL CLOB 是内置类型,它将字 ...