MySQL 事务 MVCC 版本链
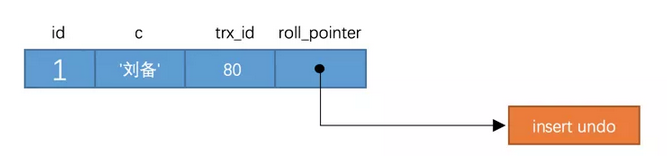
4)如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本,如果最后一个版本也不可见的话,那么就意味着该条记录对该事务不可见,查询结果就不包含该记录。


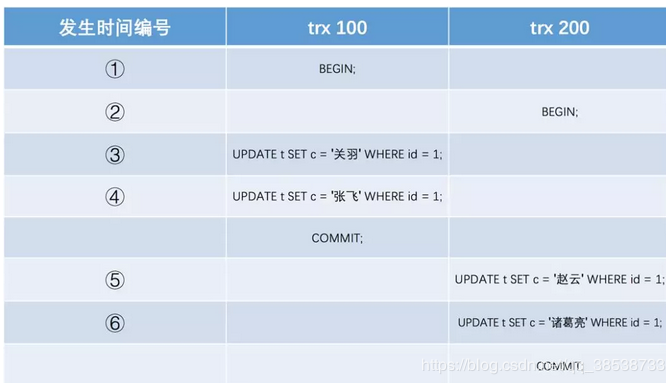
之后,我们把事务id为100的事务提交一下,就像这样:


此刻,表t中id为1的记录的版本链就长这样:
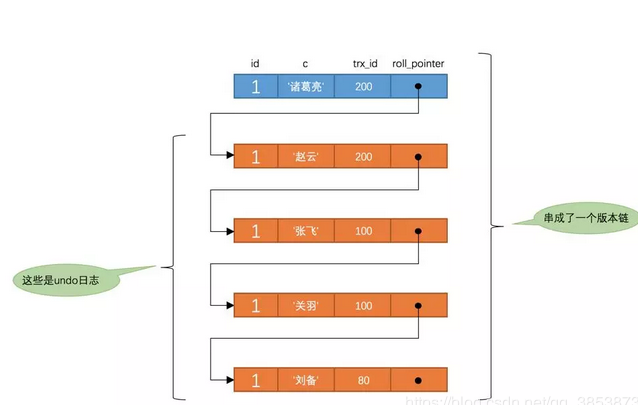

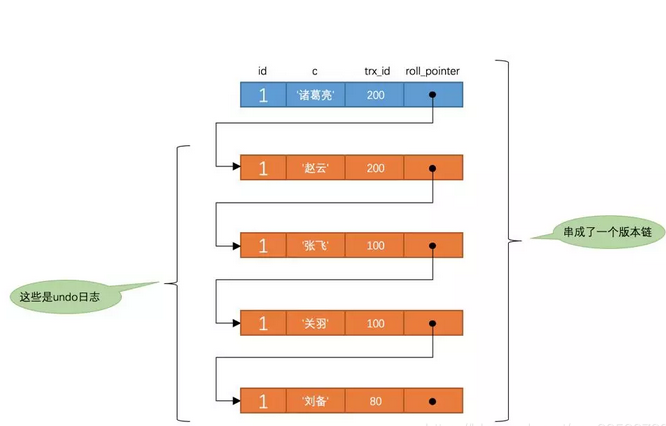
以此类推,如果之后事务id为200的记录也提交了,再此在使用READ COMMITTED隔离级别的事务中查询表t中id值为1的记录时,得到的结果就是'诸葛亮'了,具体流程我们就不分析了。总结一下就是:使用READ COMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。

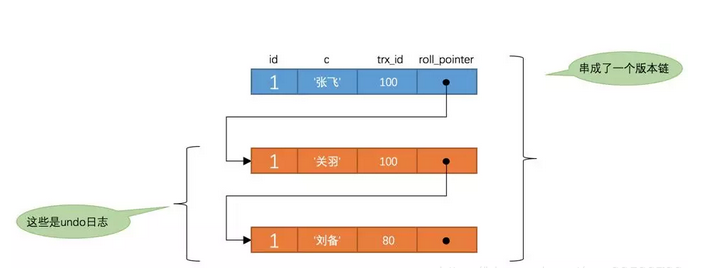
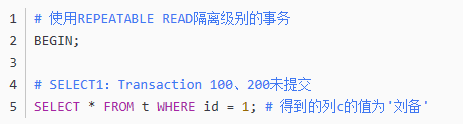


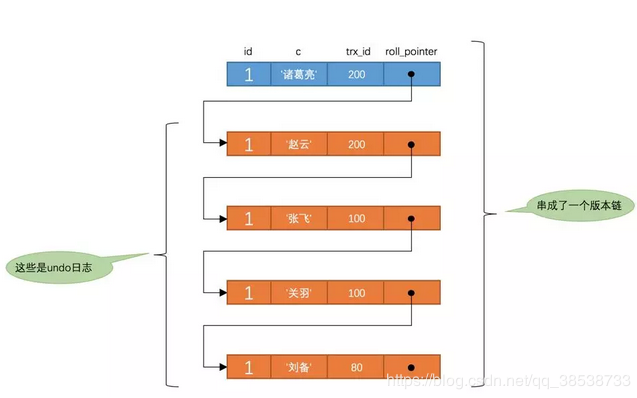

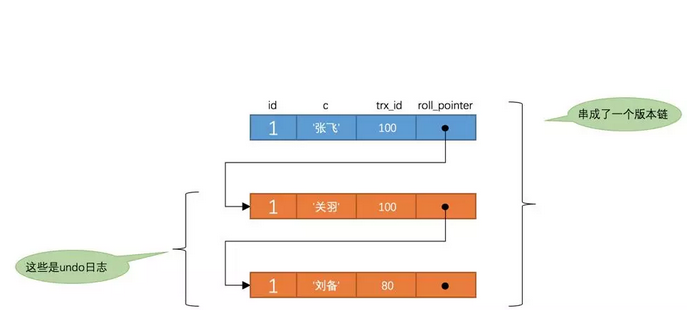
也就是说两次SELECT查询得到的结果是重复的,记录的列c值都是'刘备',这就是可重复读的含义。如果我们之后再把事务id为200的记录提交了,之后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个id为1的记录,得到的结果还是'刘备',具体执行过程大家可以自己分析一下。
---------------------
作者:wust_zwl
来源:CSDN
原文:https://blog.csdn.net/qq_38538733/article/details/88902979
版权声明:本文为博主原创文章,转载请附上博文链接!
MySQL 事务 MVCC 版本链的更多相关文章
- 《Mysql - 事务 MVCC》
一:前言 - 前面通过 <Mysql 事务 - 隔离> 的学习,知道了事务的实现,是根据 获取一致性视图 来实现的. 二:那么,什么时候会获取到一致性视图呢? - 例如:有三个事务,启动的 ...
- mysql事务原理及MVCC
mysql事务原理及MVCC 事务是数据库最为重要的机制之一,凡是使用过数据库的人,都了解数据库的事务机制,也对ACID四个 基本特性如数家珍.但是聊起事务或者ACID的底层实现原理,往往言之不详,不 ...
- 数据库篇:mysql事务原理之MVCC视图+锁
前言 数据库的事务特性 数据并发读写时遇到的一致性问题 mysql事务的隔离级别 MVCC的实现原理 锁和隔离级别 关注公众号,一起交流,微信搜一搜: 潜行前行 1 数据库的事务特性 原子性:同一个事 ...
- 温故知新-Mysql锁&事务&MVCC
文章目录 锁概述 锁分类 MyISAM 表锁 InnoDB 行锁 事务及其ACID属性 InnoDB 的行锁模式 注意 MVCC InnoDB 中的 MVCC 参考 你的鼓励也是我创作的动力 Post ...
- mysql的MVCC多版本并发控制机制
MVCC多版本并发控制机制 全英文名:Multi-Version Concurrency Control MVCC不会通过加锁互斥来保证隔离性,避免频繁的加锁互斥. 而在串行化隔离级别为了保证较高的隔 ...
- 面试官:什么是MySQL 事务与 MVCC 原理?
作者:小林coding 图解计算机基础网站:https://xiaolincoding.com/ 大家好,我是小林. 之前写过一篇 MySQL 的 MVCC 的工作原理,最近有读者在网站上学习的时候, ...
- 一文搞懂MySQL事务的隔离性如何实现|MVCC
关注公众号[程序员白泽],带你走进一个不一样的程序员/学生党 前言 MySQL有ACID四大特性,本文着重讲解MySQL不同事务之间的隔离性的概念,以及MySQL如何实现隔离性.下面先罗列一下MySQ ...
- 「MySQL高级篇」MySQL之MVCC实现原理&&事务隔离级别的实现
大家好,我是melo,一名大三后台练习生,死去的MVCC突然开始拷打我! 引言 MVCC,非常顺口的一个词,翻译起来却不是特别顺口:多版本并发控制. 其中多版本是指什么呢?一条记录的多个版本. 并发控 ...
- Mysql InnoDB多版本并发控制MVCC
参考书籍<mysql是怎样运行的> 系列文章目录和关于我 一丶为什么需要事务隔离级别 mysql是一个客户端/服务断软件,对于同一个服务器来说,可以有多个客户端进行连接,每一个客户端进行连 ...
随机推荐
- golang开发:环境篇(四)包管理器 glide的使用
glide 是golang项目开发中是特别重要的软件,没有它,golang的项目可能都无法发布. 为什么要使用glide 平时我们开发Go项目的时候,使用第三方的包的时候都直接使用go get 去获取 ...
- Scratch编程与高中数学算法初步
scratch编程与高中数学算法初步 一提到编程,大家可能觉得晦涩难懂,没有一定的英语和数学思维基础的人,一大串的编程代码让人望而步,何况是中小学生. Scratch是一款由麻省理工学院(MIT) ...
- PowerBuilder学习笔记之删除和加载PBL文件的方法
删除PBL目录的方法:直接点删除键删除 加载PBL文件的方法:点Browse按钮选择PBL文件
- Linux 服务器修改时间与时间同步
设置时间 date --set '2015-11-23 0:10:40' # 方法一,通用 timedatectl set-time '2015-11-23 08:10:40' # 容器内可能不支持 ...
- 对称加密,非对称加密,数字签名,https
对称加密和非对称加密 对称加密 概念:加密秘钥和解密秘钥使用相同的秘钥(即加密和解密都必须使用同一个秘钥) 特点:一对一的双向保密通信(每一方既可用该秘钥加密,也可用该秘钥解密,非对称加密是多对一的单 ...
- 启动 docker 容器时报错
错误信息: iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 9300 -j DNAT --to-dest ...
- webpack 3.1 升级webpack 4.0
webpack 3.1 升级webpack 4.0 为了提升打包速度以及跟上主流技术步伐,前段时间把项目的webpack 升级到4.0版本以上 webpack 官网:https://webpack.j ...
- springboot项目实用代码整理
// 判断JSONOBJECT是否为空 CommonUtils.checkJSONObjectIsEmpty(storeInfo) // 判断字符串是否为空," "也为空 Stri ...
- 自定义AuthorizeFilter
using Microsoft.AspNetCore.Authorization; using Microsoft.AspNetCore.Authorization.Infrastructure; u ...
- CSS3Ps -Photoshop图层特效转CSS3代码
CSS3Ps 这个ps插件可以将ps图层特效直接转化成css3代码,对前端非常有益. 插件下载:http://css3ps.com/Download/