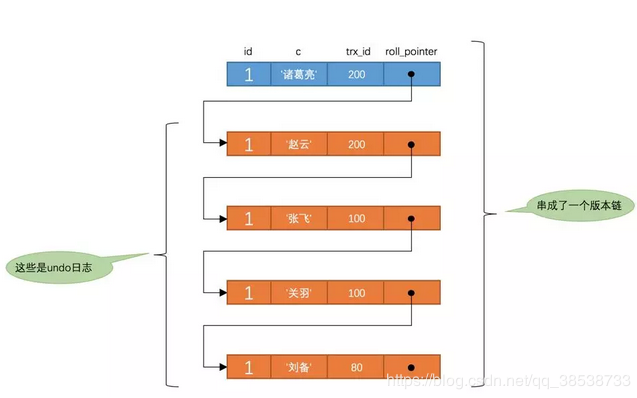
MySQL 事务 MVCC 版本链
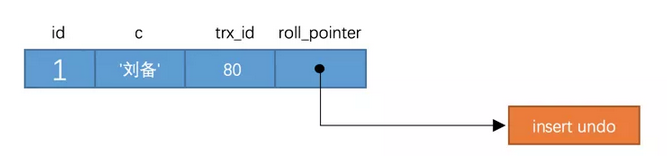
4)如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本,如果最后一个版本也不可见的话,那么就意味着该条记录对该事务不可见,查询结果就不包含该记录。


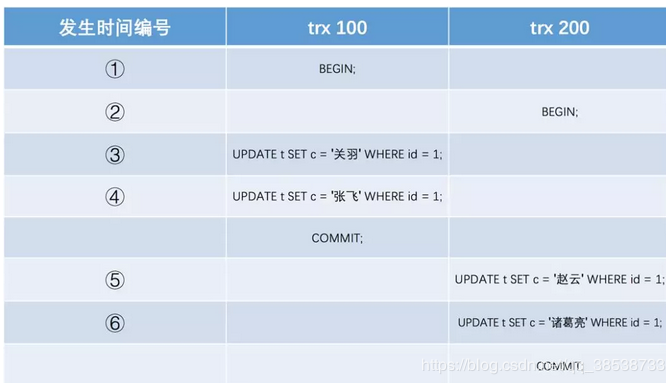
之后,我们把事务id为100的事务提交一下,就像这样:


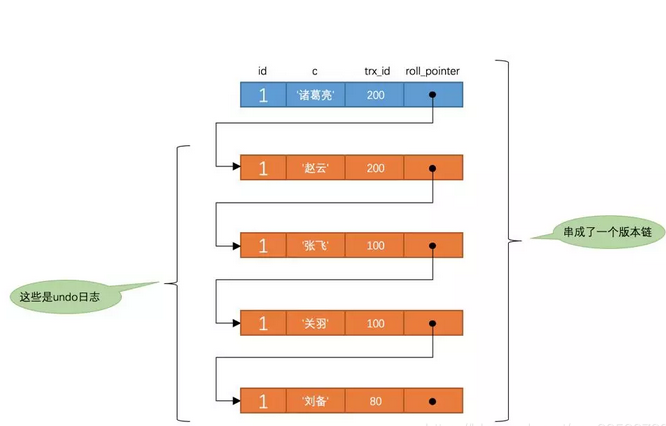
此刻,表t中id为1的记录的版本链就长这样:
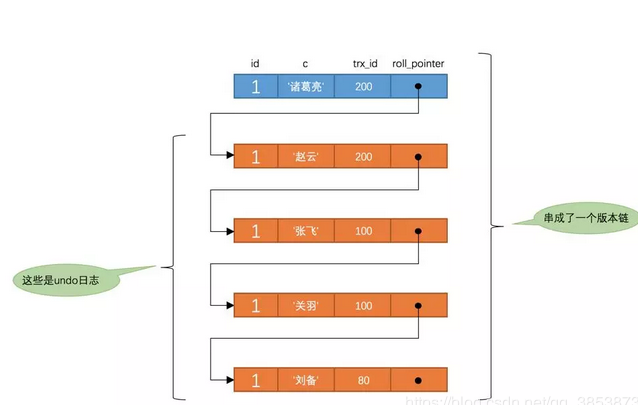

以此类推,如果之后事务id为200的记录也提交了,再此在使用READ COMMITTED隔离级别的事务中查询表t中id值为1的记录时,得到的结果就是'诸葛亮'了,具体流程我们就不分析了。总结一下就是:使用READ COMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。

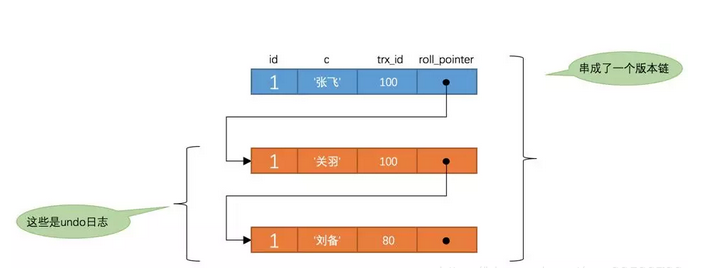
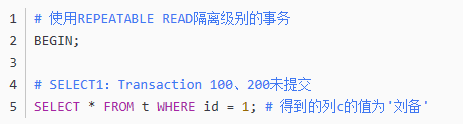



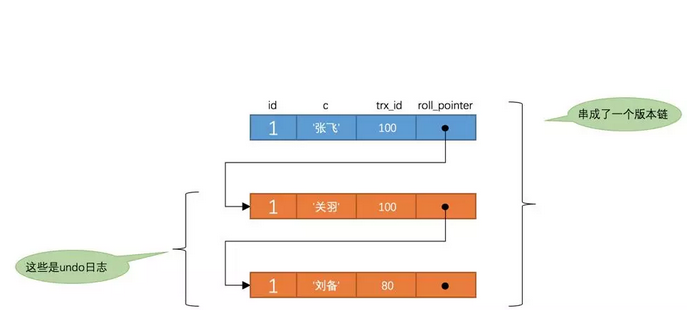
也就是说两次SELECT查询得到的结果是重复的,记录的列c值都是'刘备',这就是可重复读的含义。如果我们之后再把事务id为200的记录提交了,之后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个id为1的记录,得到的结果还是'刘备',具体执行过程大家可以自己分析一下。
---------------------
作者:wust_zwl
来源:CSDN
原文:https://blog.csdn.net/qq_38538733/article/details/88902979
版权声明:本文为博主原创文章,转载请附上博文链接!
MySQL 事务 MVCC 版本链的更多相关文章
- 《Mysql - 事务 MVCC》
一:前言 - 前面通过 <Mysql 事务 - 隔离> 的学习,知道了事务的实现,是根据 获取一致性视图 来实现的. 二:那么,什么时候会获取到一致性视图呢? - 例如:有三个事务,启动的 ...
- mysql事务原理及MVCC
mysql事务原理及MVCC 事务是数据库最为重要的机制之一,凡是使用过数据库的人,都了解数据库的事务机制,也对ACID四个 基本特性如数家珍.但是聊起事务或者ACID的底层实现原理,往往言之不详,不 ...
- 数据库篇:mysql事务原理之MVCC视图+锁
前言 数据库的事务特性 数据并发读写时遇到的一致性问题 mysql事务的隔离级别 MVCC的实现原理 锁和隔离级别 关注公众号,一起交流,微信搜一搜: 潜行前行 1 数据库的事务特性 原子性:同一个事 ...
- 温故知新-Mysql锁&事务&MVCC
文章目录 锁概述 锁分类 MyISAM 表锁 InnoDB 行锁 事务及其ACID属性 InnoDB 的行锁模式 注意 MVCC InnoDB 中的 MVCC 参考 你的鼓励也是我创作的动力 Post ...
- mysql的MVCC多版本并发控制机制
MVCC多版本并发控制机制 全英文名:Multi-Version Concurrency Control MVCC不会通过加锁互斥来保证隔离性,避免频繁的加锁互斥. 而在串行化隔离级别为了保证较高的隔 ...
- 面试官:什么是MySQL 事务与 MVCC 原理?
作者:小林coding 图解计算机基础网站:https://xiaolincoding.com/ 大家好,我是小林. 之前写过一篇 MySQL 的 MVCC 的工作原理,最近有读者在网站上学习的时候, ...
- 一文搞懂MySQL事务的隔离性如何实现|MVCC
关注公众号[程序员白泽],带你走进一个不一样的程序员/学生党 前言 MySQL有ACID四大特性,本文着重讲解MySQL不同事务之间的隔离性的概念,以及MySQL如何实现隔离性.下面先罗列一下MySQ ...
- 「MySQL高级篇」MySQL之MVCC实现原理&&事务隔离级别的实现
大家好,我是melo,一名大三后台练习生,死去的MVCC突然开始拷打我! 引言 MVCC,非常顺口的一个词,翻译起来却不是特别顺口:多版本并发控制. 其中多版本是指什么呢?一条记录的多个版本. 并发控 ...
- Mysql InnoDB多版本并发控制MVCC
参考书籍<mysql是怎样运行的> 系列文章目录和关于我 一丶为什么需要事务隔离级别 mysql是一个客户端/服务断软件,对于同一个服务器来说,可以有多个客户端进行连接,每一个客户端进行连 ...
随机推荐
- C++枚举类型教案
一.枚举类型的应用场景 只需要将需要的变量值一一列举出来,便构成一个枚举类型. 二.枚举类型的定义 ·定义方式: enum 枚举类型名字{枚举常量表}: ·关键字enum:说明接下来定义的是一个枚举类 ...
- Springboot入门及配置文件介绍(内置属性、自定义属性、属性封装类)
目的: 1.Springboot入门 SpringBoot是什么? 使用Idea配置SpringBoo使用t项目 测试案例 2.Springboot配置文件介绍 内置属性 自定义属性 属性封装类 Sp ...
- ideaui安装破解、相关配置、JRebel破解
前言: Ideaui 2019(官网 https://www.jetbrains.com/idea/?fromMenu) 安装软件就简单啦,下载选择路径就完事了,注意文件名全英文: 但是按照咱们传 ...
- my linux cmd
常用的linux命令 一.vi yy 复制当前行 u 撤销 p 粘贴 dd 删除当前行 set nu 显示行号 gg 首行 G 末行 二.用户管理相关 useradd 添加用户 (默认创建一个与用 ...
- c++智能指针介绍_补充
不明白我做错了什么,这几天老婆给我冷战了起来,也不给我开视频让我看娃了..哎,心累!趁着今晚的一些空闲时间来对智能指针做个补充吧. 写完上篇“智能指针介绍”后,第二天上班途中时,突然一个疑问盘踞在心头 ...
- 怎样在python中写多行语句
一般来说, 一行就是一条语句, 但有时语句过长不利于阅读, 一般会写成多行的形式, 这时需要在换行时使用反斜杠: \ name = "Lilei" age = 23 gender ...
- Spring Cloud Alibaba学习笔记(7) - Sentinel规则持久化及生产环境使用
Sentinel 控制台 需要具备下面几个特性: 规则管理及推送,集中管理和推送规则.sentinel-core 提供 API 和扩展接口来接收信息.开发者需要根据自己的环境,选取一个可靠的推送规则方 ...
- Centos6 r8192ce_pci
Centos6 r8192ce_pci # # yum install epel-release# yum-config-manager --enable rhui-REGION-rhel-serve ...
- Java Web-Ajax学习
Java Web-Ajax学习 概念 Ajax(Asynchronous JavaScript And XML,异步的JavaScript和XML). 异步和同步:在客户端和服务器端相互通信的基础上来 ...
- javascript_09-数组
数组 //数组 // var array = new Array(); // array[0]="zs"; // array[1]="ls"; var name ...