MySQL数据同步交换
一、为了解决数据同步汇聚,数据分发,数据转换,数据维护等需求,TreeSoft将复杂的网状的同步链路变成了星型数据链路。
TreeSoft作为中间传输载体负责连接各种数据源,为各种异构数据库之间架起同步的桥梁,
实现一对多,多对多,多对一等复杂场景的数据同步。
TreeSoft已被广泛应用,每日处理大量大数据的数据维护、数据同步、数据汇聚、数据转换业务。
支持MySQL, MariaDB, Oracle, PostgreSQL, SQL Server, DB2, MongoDB, Hive, SAP HANA, Sybase,
Caché, Informix, 达梦DM, 金仓Kinbase, 神通, 南大GBase等数据库。


二、兼具数据同步与数据维护管理功能,具备适应性广,灵活性强等特点。
1、支持主流RDBMS、NOSQL数据库间同步交换数据。
2、支持单节点或集群布署,可应对庞杂的业务环境。
3、支持百万级以上数据量同步。
4、企业级定时任务框架,稳定高效。
5、支持多数据源向多目标数据汇聚或数据分发。
6、支持定时数据清洗转换等后处理。
7、支持window, Linux,mac等操作系统。
8、基于JAVA开发,WEB网页管理,快速布署,到处使用。
9、基于网页灵活配置及管理,详细记录同步日志。
10、兼具数据维护,数据库管理功能,大大提高工作效率。

三、某高校数据同步案例:
将学工系统MySQL,教务系统SqlServer,后勤系统Oracle,一卡通系统SqlServer异构数据源定时同步到大数据共享库MySQL。 同时实现数据的在线管理维护,数据转换清洗,方便验证同步结果,以及数据统计汇总等需求。
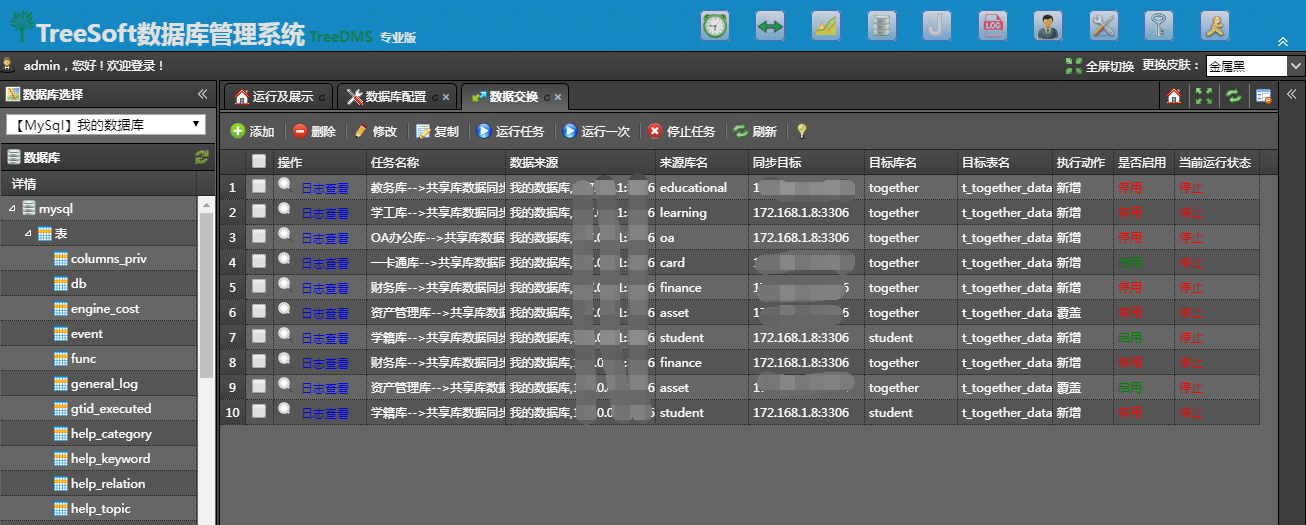
数据同步配置直接通过页面操作,维护方便。

四、TreeSoft的安装及使用
1、到官网http://www.treesoft.cn下载试用版,默认试用期一个月。
2、下载的安装包中已包含Jdk1.7,Tomcat7.0,windows系统直接解压缩,按说明直接启动即可。
3、下载的安装包中有详细的使用说明文档,及常见问题说明。
4、Linux系统的布署也十分方便,按说明文档操作即可。
5、运行环境:jdk1.7+ ,Tomcat7.0+ ,布署配置简单快速。
MySQL数据同步交换的更多相关文章
- Mysql数据同步Elasticsearch方案总结
Mysql数据同步Elasticsearch方案总结 https://my.oschina.net/u/4000872/blog/2252620
- 几篇关于MySQL数据同步到Elasticsearch的文章---第一篇:Debezium实现Mysql到Elasticsearch高效实时同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484358&idx=1&sn=3a78347 ...
- Oracle数据同步交换
一.为了解决数据同步汇聚,数据分发,数据转换,数据维护等需求,TreeSoft将复杂的网状的同步链路变成了星型数据链路. TreeSoft作为中间传输载体负责连接各种数据源,为各种异构数据库之 ...
- SQL Server数据同步交换
一.为了解决数据同步汇聚,数据分发,数据转换,数据维护等需求,TreeSoft将复杂的网状的同步链路变成了星型数据链路. TreeSoft作为中间传输载体负责连接各种数据源,为各种异构数据库之 ...
- ElasticSearch5+logstash的logstash-input-jdbc实现mysql数据同步
在实现的路上遇到了各种坑,再次验证官方文档只能产考不能全信! ElasticSearch安装就不说了上一篇有说! 安装logstash 官方:https://www.elastic.co/guide/ ...
- Elasticsearch和mysql数据同步(logstash)
1.版本介绍 Elasticsearch: https://www.elastic.co/products/elasticsearch 版本:2.4.0 Logstash: https://www ...
- Elasticsearch和mysql数据同步(elasticsearch-jdbc)
1.介绍 对mysql.oracle等数据库数据进行同步到ES有三种做法:一个是通过elasticsearch提供的API进行增删改查,一个就是通过中间件进行数据全量.增量的数据同步,另一个是通过收集 ...
- Kettle ETL 来进行mysql 数据同步——试验环境搭建(表中无索引,无约束,无外键连接的情况)
今天试验了如何在Kettle的图形界面(Spoon)下面来整合来mysql 数据库中位于不同数据库中的数据表中的数据. 试验用的数据表是customers: 第三方的数据集下载地址是:http://w ...
- Memcached与MySQL数据同步
1.介绍 在生产环境中,我们经常使用MySQL作为应用的数据库.但是随着用户的增多数据量的增大,我们将会自然而然的选择Memcached作为缓存数据库,从而减小MySQL的压力.但是memcached ...
随机推荐
- 47、[源码]-Spring容器创建-初始化MessageSource
47.[源码]-Spring容器创建-初始化MessageSource 7.initMessageSource();初始化MessageSource组件(做国际化功能:消息绑定,消息解析): 获取Be ...
- 学习。NET三周心得
目前为止 学习.NET已经快一个月了,有刚开始的不懂,到中途懵懂.再到现在的简懂 ,感觉自己迷了好多天,学习程序员跟学其他的程序还不同,其他的有固定格式,而.NET则固定很少 ,一直在用方法连接前后台 ...
- 字符串转换json格式
前台json转字符串传递后台时 用到: data: JSON.stringify({ "zh": zhanghao, "mm": mima }), 当后台返回前 ...
- Gym 102346A Artwork dfs
Artwork Gym - 102346A 题意:给n*m的地图,入口是(0,0),出口是(n,m),其中有k个监视器,坐标是(xi,yi),监视半径是r,问一个人能不能不被监视到,从起点到终点. 如 ...
- 《MySQL数据分析实战》八句箴言前四句解析
大家好,我是jacky朱元禄,很高兴继续跟大家学习<MySQL数据分析实战>,从本节课程开始,jacky将从SQL语句入手,给大家解析八句箴言: 不管三七二十一,先把数据show来看: 数 ...
- Python中匹配IP的正则表达式
下面是IPv4的IP正则匹配表达式 import re #简单的匹配给定的字符串是否是ip地址,下面的例子它不是IPv4的地址,但是它满足正则表达式 if re.match(r"^(?:[0 ...
- java把一段时间分成周,月,季度,年的时间段
package com.mq.test.activeMQ; import java.text.DateFormat; import java.text.ParseException; import j ...
- Leetcode第三题《Longest Substring Without Repeating Characters》
题目: Given a string, find the length of the longest substring without repeating characters. For examp ...
- JavaScript中获取html元素常用手法和区分
对于许多前端开发项目来说,获取元素进行操作是必不可少的,例如tab标签,全屏切换,自动滚播等效果都需要通过获取节点元素来实现.下面我来总结下JavaScript最常用的4个Document对象中获取元 ...
- 一键分享QQ、微信、微博等
github上找到的,合并了一个二维码在线支持API,直接修改样式可用. 二维码API说明网址:http://www.liantu.com/pingtai/ <html> <head ...