6.Java集合-LinkedList实现原理及源码分析
Java中LinkedList的部分源码(本文针对1.7的源码)
LinkedList的基本结构
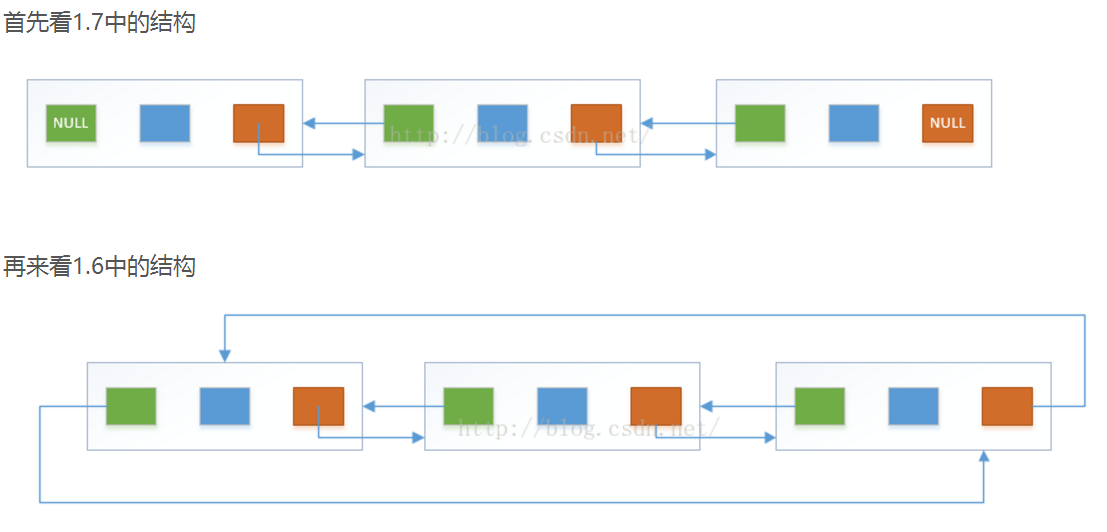
jdk1.7之后,node节点取代了 entry ,带来的变化是,将1.6中的环形结构优化为了直线型链表结构,从双向循环链表变成了双向链表

在LinkedList中,我们把链子的“环”叫做“节点”,每个节点都是同样的结构。节点与节点之间相连,构成了我们LinkedList的基本数据结构,也是LinkedList的核心。
我们再来看一下LinkedList在jdk1.6和1.7之间结构的区别
LinkedList的构造方法
LinkedList包含3个全局参数,size存放当前链表有多少个节点。
first为指向链表的第一个节点的引用
last为指向链表的最后一个节点的引用

LinkedList的构造方法有两个,一个是无参构造,一个是传入Collection对象的构造
// 什么都没做,是一个空实现
public LinkedList() {
} public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
} public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
} public boolean addAll(int index, Collection<? extends E> c) {
// 检查传入的索引值是否在合理范围内
checkPositionIndex(index);
// 将给定的Collection对象转为Object数组
Object[] a = c.toArray();
int numNew = a.length;
// 数组为空的话,直接返回false
if (numNew == 0)
return false;
// 数组不为空
Node<E> pred, succ;
if (index == size) {
// 构造方法调用的时候,index = size = 0,进入这个条件。
succ = null;
pred = last;
} else {
// 链表非空时调用,node方法返回给定索引位置的节点对象
succ = node(index);
pred = succ.prev;
}
// 遍历数组,将数组的对象插入到节点中
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
} if (succ == null) {
last = pred; // 将当前链表最后一个节点赋值给last
} else {
// 链表非空时,将断开的部分连接上
pred.next = succ;
succ.prev = pred;
}
// 记录当前节点个数
size += numNew;
modCount++;
return true;
}
注:Node是LinkedList的内部私有类,也是我们的核心节点类
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkList部分方法分析
addFirst/addLast分析
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f); // 创建新的节点,新节点的后继指向原来的头节点,即将原头节点向后移一位,新节点代替头结点的位置。
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
加入一个新的节点,看方法名就能知道,是在现在的链表的头部加一个节点,既然是头结点,那么头结点的前继必然为null,所以这也是Node<E> newNode = new Node<>(null, e, f);这样写的原因。
之后将first指向了newNode ,指定这个节点以后就就是我们的头结点
之后对原来头节点进行了判断,若在插入元素之前头结点为null,则当前加入的元素就是第一个几点,也就是头结点,所以当前的状况就是:头结点=刚刚加入的节点=尾节点。
若在插入元素之前头结点不为null,则证明之前的链表是有值的,那么我们只需要把新加入的节点的后继指向原来的头结点,而尾节点则没有发生变化。这样一来,原来的头结点就变成了第二个节点了。达到了我们的目的。
addLast方法在实现上是个addFirst是一致的,这里就不在赘述了。有兴趣的朋友可以看看源代码。
其实,LinkedList中add系列的方法都是大同小异的,都是创建新的节点,改变之前的节点的指向关系。仅此而已。
getFirst/getLast方法分析
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
get方法分析(node方法的调用)
public E get(int index) {
// 校验给定的索引值是否在合理范围内
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
注:关键在于,判断给定的索引值,若索引值大于整个链表长度的一半,则从后往前找,若索引引用值小于整个链表长度的一半,则从前往后找。这样就可以保证,不管链表的长度有多大,搜索的时候最多只搜索链表长度的一半就可以找打,大大提升了效率
removeFirst/removeLast方法分析
public E get(int index) {
// 校验给定的索引值是否在合理范围内
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
摘掉头结点,将原来的第二个节点变为头结点,改变first的指向,若之前仅剩一个节点,移除之后全部置为null
对于LinkList的其他方法,大致上都是包装了以上这几个方法
关于集合的一个小补充:
在ArrayList,LinkedList,HashMap等等的增、删、改方法中,我们总能看到modCount的身影,modCount字面意思就是修改次数,但为什么要记录modCount的修改次数呢?
大家发现一个公共特点没有,所有使用modCount属性的集合全是线程不安全的,这是为什么呢?说明modCount 可能和线程安全有关
阅读源码,发现这玩意只有在本数据结构对应的迭代器中才使用,以HashMap为例:
private abstract class HashIterator<E> implements Iterator<E> {
Entry<K,V> next; // next entry to return
int expectedModCount; // For fast-fail
int index; // current slot
Entry<K,V> current; // current entry
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
public void remove() {
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
}
由以上代码可以看出,在一个迭代器初始的时候会赋予它调用这个迭代器的对象的mCount,如果在迭代器遍历的过程中,一旦发现这个对象的mcount和迭代器存储的mcount 不一样,那就抛出异常
所以在以下情况下,会抛出异常:1.单线程的情况下,使用迭代器对象进行遍历,但是在修改长度,使用的是对象本身,对象的mcount产生变化,但是迭代器的mcount不变,差异产生,抛出异常
2.多线程情况下,且集合为共享变量,那么在使用迭代器遍历的时候,如果其他线程修改对象本身的mcount,那么也会产生差异,抛出异常
下面详细解释:
Fail-Fast机制
我们知道java.util.HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓的fail-fast策略。这一策略在源码中的实现是通过 modCount 域,modCount顾名思义就是修改次数,对HashMap内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount。在迭代过程中,判断 modCount跟expectedModCount是否相等,如果不相等就表示,我还在迭代呢,就有其他线程对Map进行了修改,注意到 modCount 声明为 volatile,保证线程之间修改的可见性。
所以在这里和大家建议,当大家遍历那些非线程安全的数据结构时,尽量使用迭代器
6.Java集合-LinkedList实现原理及源码分析的更多相关文章
- 1.Java集合-HashMap实现原理及源码分析
哈希表(Hash Table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常 ...
- 4.Java集合-ArrayList实现原理及源码分析
一.ArrayList概述: ArrayList 是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存 ArrayList不是线程安全的,只能用在单线程的情况 ...
- 3.Java集合-HashSet实现原理及源码分析
一.HashSet概述: HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持,它不保证set的迭代顺序很久不变.此类允许使用null元素 二.HashSet的实现: 对于Ha ...
- 2.Java集合-ConcurrentHashMap实现原理及源码分析
一.为何用ConcurrentHashMap 在并发编程中使用HashMap可能会导致死循环,而使用线程安全的HashTable效率又低下. 线程不安全的HashMap 在多线程环境下,使用HashM ...
- Java集合详解及List源码分析
对于数组我们应该很熟悉,一个数组在内存中总是一块连续的存储空间,数组的创建使用new关键字,数组是引用类型的数据,一旦第一个元素的位置确定,那么后面的元素位置也就确定了,数组有一个最大的局限就是数组一 ...
- Java ThreadPoolExecutor线程池原理及源码分析
一.源码分析(基于JDK1.6) ThreadExecutorPool是使用最多的线程池组件,了解它的原始资料最好是从从设计者(Doug Lea)的口中知道它的来龙去脉.在Jdk1.6中,Thread ...
- java集合【13】——— Stack源码分析走一波
前言 集合源码分析系列:Java集合源码分析 前面已经把Vector,ArrayList,LinkedList分析完了,本来是想开始Map这一块,但是看了下面这个接口设计框架图:整个接口框架关系如下( ...
- Java集合框架之接口Collection源码分析
本文我们主要学习Java集合框架的根接口Collection,通过本文我们可以进一步了解Collection的属性及提供的方法.在介绍Collection接口之前我们不得不先学习一下Iterable, ...
- Java集合之Map和Set源码分析
以前就知道Set和Map是java中的两种集合,Set代表集合元素无序.不可重复的集合:Map是代表一种由多个key-value对组成的集合.然后两个集合分别有增删改查的方法.然后就迷迷糊糊地用着.突 ...
随机推荐
- bat 脚本之 使用函数
bat 脚本之 使用函数 摘自:https://blog.csdn.net/peng_cao/article/details/73999076 2017年06月30日 15:06:37 pengcao ...
- 123456---com.twoapp.huanYingMotro--- 幻影摩托
123456---com.twoapp.huanYingMotro--- 幻影摩托
- LeetCode_168. Excel Sheet Column Title
168. Excel Sheet Column Title Easy Given a positive integer, return its corresponding column title a ...
- python 递归和匿名函数
1.理解函数执行流程 def foo1(b, b1=3): print("foo1 called", b, b1) def foo2(c): foo3(c) print(" ...
- jenkins的slave/agent如何通过tcp端口和master建立连接
Jenkins是master-slave/agent结构,可以通过代理把任务下发到各个agent/slave上去执行 如图,首先在master上开启代理配置,指定master上开启的tcp端口,以及和 ...
- destoon 6.0 手机站支持在所有浏览器访问
我们的在本地调试destoon 6.0的手机站模板时,用浏览器的自带审查元素很不方便. 可是destoon 默认是在电脑端打不开手机站,如果这个设置能够去除掉,那就可以了. 去掉这个限制,指需要两步 ...
- table列表全选
<table><tr><td><input type="checkbox" /></td><td></ ...
- CenOS 7 安装JDK
1.输入安装命令 yum install java-1.8.0-openjdk-devel.x86_64
- malloc/free和new/delete详解与应用
C++面试经常会问到关于malloc/free和new/delete的区别,网上有不同版本的解释,这里总结下并加上个人理解和使用. 两者相同点 1.都可以申请动态堆内存. 两者不同点 1.new/de ...
- 删除列表的三个方式(python)
del是个语句而不是方法 del member[1]:通过下标进行删除 del member:也可删除整个列表 remove():根据列表元素本身来删除,而不是通过下标 member.remove(' ...