【大数据】SmallFile-Analysis-Script
1.root账号先在namenode节点上配置一个定时任务,将fsimage定时传到其他客户机上进行操作
whereis hadoop命令确定安装目录,然后去配置文件找到namenode节点(data-93 emr-header-1)
0 1 * * * sh /root/fsimage.sh 每晚一点将fsimage文件发送到集群其他机器上,fsimage.sh如下
#!/bin/bash
TARGET_HOST=192.168.11.130
SCP_PORT=
IMAGE_DIR=/mnt/disk1/hdfs/name/current
TARGET_DIR=/data/hdfs
DAY=`date +%Y%m%d`
echo "day=$DAY" cd $IMAGE_DIR
fsname=`ls fsimage* | head -`
echo $fsname scp -P $SCP_PORT $fsname ${TARGET_HOST}:${TARGET_DIR}/fsimage.${DAY} echo "done"
脚本在/mnt/disk1/hdfs/name/current下执行【scp -P 58422 fsimage_0000000007741688997 192.168.11.130:/data/hdfs/fsimage.20190920】,将namenode上的fsimage镜像文件传递到data130(192.168.11.130)上的文件夹里
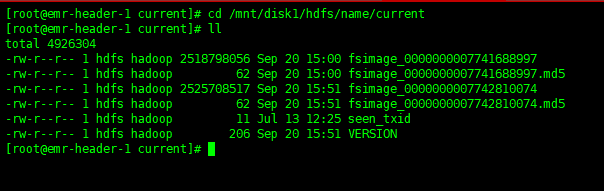
2.切换账号gobblin,在data-130的机子上配置crontab 任务,每天2点执行分析脚本
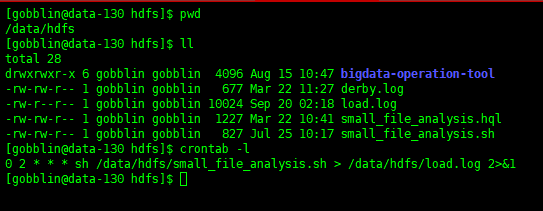
small_file_analysis.sh如下
#!/bin/bash
source /etc/profile basepath=$(cd `dirname $`; pwd)
cd $basepath
IMAGE_DIR="/data/hdfs"
IMAGE_PREFIX="fsimage" # . 解析日期
cur_date="`date +%Y%m%d`"
cur_month="`date +%Y%m`"
cur_day="`date +%d`"
echo "cur month = $cur_month"
echo "cur day = $cur_day"
echo "cur date = $cur_date"
IMAGE_NAME=$IMAGE_PREFIX.$cur_date
echo "fsimage name is $IMAGE_NAME" # . 解析 fsimage 镜像文件,生成txt 文件
export HADOOP_HEAPSIZE=
hdfs oiv -i $IMAGE_NAME -o $IMAGE_NAME.txt -p Delimited # . 将 txt 文件load进 hive 表中
hive -e "load data local inpath '$IMAGE_DIR/$IMAGE_NAME.txt' overwrite into table dataplatform.fsimage partition (month='$cur_month',day='$cur_day');" # . sql
hive -hivevar CUR_MONTH=$cur_month -hivevar CUR_DAY=$cur_day -f small_file_analysis.hql rm -f fsimage*
echo "done"
脚本逻辑很简单:使用image分析工具iov将image转为txt格式的文件,然后将文件导入hive 表(dataplatform.fsimage),再通过hive命令执行sql,将sql查询结果插入分析结果表(dataplatform.small_file_report_day),最后删除fsimage开头的2个文件即可
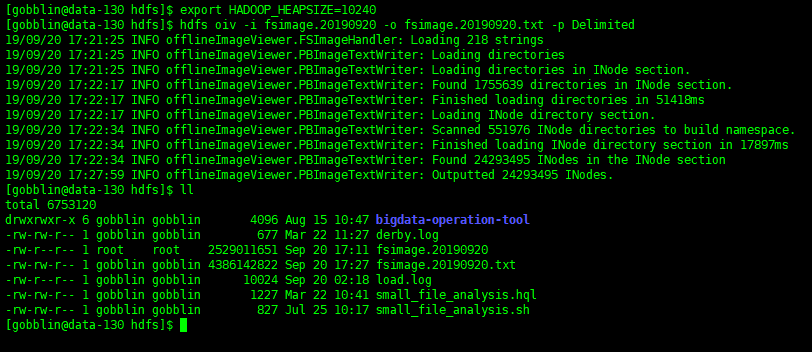
注意:export HADOOP_HEAPSIZE=10240 要加上,不然会报堆内存溢出
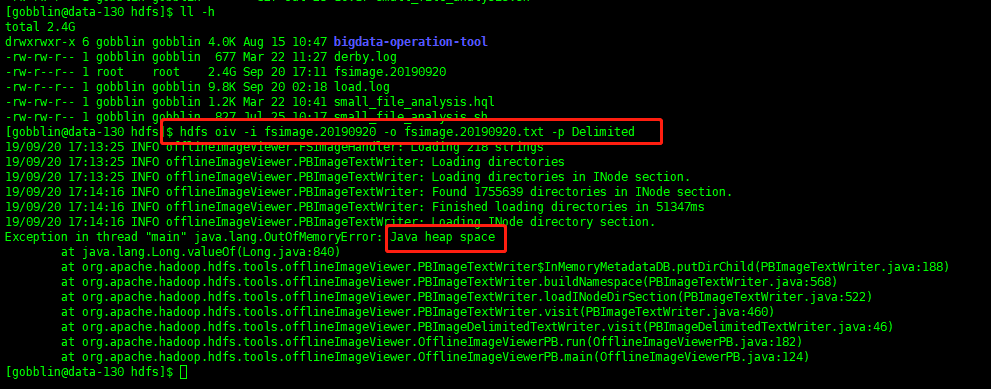
设置堆内存大小之后执行:
small_file_analysis.hql 如下:
set mapreduce.job.queuename=root.production.gobblin;
set mapreduce.job.name=small_file_analysis;
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=4;
set mapreduce.map.memory.mb=1024;
set mapreduce.reduce.memory.mb=1024; INSERT OVERWRITE TABLE dataplatform.small_file_report_day PARTITION (month='${CUR_MONTH}', day='${CUR_DAY}')
SELECT b.path as path, b.total_num as total_num FROM (
SELECT path, total_num, root_path
FROM
(
SELECT
SUBSTRING_INDEX(path, '/', 4) AS path,
COUNT(1) AS total_num,
SUBSTRING_INDEX(path, '/', 2) AS root_path
FROM
dataplatform.fsimage
WHERE
file_size < 1048576
AND month='${CUR_MONTH}' AND day='${CUR_DAY}'
AND SUBSTRING_INDEX(path, '/', 2) in ('/warehouse', '/tmp')
GROUP BY SUBSTRING_INDEX(path, '/', 4),SUBSTRING_INDEX(path, '/', 2)
UNION
SELECT
SUBSTRING_INDEX(path, '/', 5) AS path,
COUNT(1) as total_num,
SUBSTRING_INDEX(path, '/', 3) AS root_path
FROM
dataplatform.fsimage
WHERE
file_size < 1048576
AND month='${CUR_MONTH}' AND day='${CUR_DAY}'
AND SUBSTRING_INDEX(path, '/', 3) = '/gobblin/source'
GROUP BY SUBSTRING_INDEX(path, '/', 5),SUBSTRING_INDEX(path, '/', 3)
) a
dataplatform.fsimage建表语句
CREATE TABLE `fsimage`(
`path` string,
`block_num` int,
`create_time` string,
`update_time` string,
`block_size` bigint,
`unknown1` int,
`file_size` bigint,
`unknown2` int,
`unknown3` int,
`permission` string,
`user` string,
`group` string)
PARTITIONED BY (
`month` string,
`day` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'serialization.format'='\t')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://emr-cluster/warehouse/dataplatform.db/fsimage'
dataplatform.small_file_report_day建表语句:
CREATE TABLE `dataplatform.small_file_report_day`(
`path` string,
`total_num` bigint)
PARTITIONED BY (
`month` string,
`day` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://emr-cluster/warehouse/dataplatform.db/small_file_report_day'
TBLPROPERTIES
'parquet.compression'='SNAPPY'

【大数据】SmallFile-Analysis-Script的更多相关文章
- 杂记- 3W互联网的圈子,大数据敏捷BI与微软BI的前端痛点
开篇介绍 上周末参加了一次永洪科技在中关村 3W 咖啡举行的一次线下沙龙活动 - 关于它们的产品大数据敏捷 BI 工具的介绍.由此活动,我想到了三个话题 - 3W 互联网的圈子,永洪科技的大数据敏捷 ...
- 一篇文章看懂TPCx-BB(大数据基准测试工具)源码
TPCx-BB是大数据基准测试工具,它通过模拟零售商的30个应用场景,执行30个查询来衡量基于Hadoop的大数据系统的包括硬件和软件的性能.其中一些场景还用到了机器学习算法(聚类.线性回归等).为了 ...
- PayPal高级工程总监:读完这100篇论文 就能成大数据高手(附论文下载)
100 open source Big Data architecture papers for data professionals. 读完这100篇论文 就能成大数据高手 作者 白宁超 2016年 ...
- jquery.datatable.js与CI整合 异步加载(大数据量处理)
http://blog.csdn.net/kingsix7/article/details/38928685 1.CI 控制器添加方法 $this->show_fields_array=arra ...
- Azure HDInsight 和 Spark 大数据实战(一)
What is HDInsight? Microsoft Azure HDInsight 是基于 Hortonoworks Data Platform (HDP) 的 Hadoop 集群,包括Stor ...
- Ambari——大数据平台的搭建利器
转载自http://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/ 扩展 Ambari 管理一个自定义的 Service ...
- (原创)大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 决策树分析算法)
随着大数据时代的到来,数据挖掘的重要性就变得显而易见,几种作为最低层的简单的数据挖掘算法,现在利用微软数据案例库做一个简要总结. 应用场景介绍 其实数据挖掘应用的场景无处不在,很多的环境都会应用到数据 ...
- WebService - 怎样提高WebService性能 大数据量网络传输处理
直接返回DataSet对象 返回DataSet对象用Binary序列化后的字节数组 返回DataSetSurrogate对象用Binary序列化后的字节数组 返回DataSetSurrogate对象用 ...
- 爱上MVC3~MVC+ZTree大数据异步树加载
回到目录 理论部分: MVC+ZTree:指在.net MVC环境下进行开发,ZTree是一个jquery的树插件 大数据:一般我们系统中,有一些表结构属于树型的,如分类,地域,菜单,网站导航等等,而 ...
- PayPal 高级工程总监:读完这 100 篇文献,就能成大数据高手
原文地址 开源(Open Source)对大数据影响,有二:一方面,在大数据技术变革之路上,开源在众人之力和众人之智推动下,摧枯拉朽,吐故纳新,扮演着非常重要的推动作用:另一方面,开源也给大数据技术构 ...
随机推荐
- 解决Jmeter跨线程组取参数值难题!(还没试)
来源 https://mp.weixin.qq.com/s/q7ArxwnX1sOfa9tfHouSBQ 如果你工作中已经在用jmeter做接口测试,或性能测试了,你可能会遇到一个麻烦. 那就是j ...
- Intellij-编译
目录 IntelliJ IDEA 编译方式介绍 编译方式介绍 编译触发按钮 运行之前的编译 @(目录) IntelliJ IDEA 编译方式介绍 编译方式介绍 相比较于 Eclipse 的实时自动编译 ...
- 浏览器最小显示12px字体的解决方法
今天做打印标签,发现浏览器最小字体限制了12px,标签那么小,12px随便几个字就给占满了: 最后通过 transform:scale(1,0.8) 搞定: 这个属性允许将元素移动.压缩.旋转:这里 ...
- (十六)集合框架(Collection和Map)和比较器(Comparable和comparator)
一.集合框架 1.1 为什么要使用集合框架? 当我们需要保持一组一样(类型相同)的元素的时候,我们应该使用一个容器来保存,数组就是这样一个容器. 那么,数组的缺点是什么呢? 数组一旦定义,长度将不能再 ...
- Core Data 的线程安全问题
前言: 很多小的App只需要一个ManagedContext在主线程就可以了,但是有时候对于CoreData的操作要耗时很久的,比如App开启的时候要载入大量数据,如果都放在主线程,毫无疑问会阻塞UI ...
- python学习笔记-电子书
程序输入和raw_inoput() 内建函数 字符解释 f% :对应小数 >>> print "%s is number %d" % ("python& ...
- 如何区分进程和线程ps -eLf
方式 使用ls /proc/pid/task/ 查看线程 使用ps -eLf命令/ps aux -L/ps aux -el 使用pstree 进程和线程 进程是资源分配的最小单位 线程是cpu时间片分 ...
- 【c# 学习笔记】使用virtual和override关键字实现方法重写
只有基类成员声明为virtual或abstract时,才能被派生类重写:而如果子类想改变虚方法的实现行为,则必须使用override关键字. public class Animal { private ...
- 机器学习算法K-NN的一个使用实例:预测一个人是否患有糖尿病 (KNN-Predict whether a person will have diabetes or not )
学习中...不断更新. 在糖尿病人的数据库中有几列是不能为0的 比如葡萄糖 胰岛素 身体指数和皮肤厚度.所以在数据预处理阶段需要对这些列的数据进行替换. remeber we did 12 minus ...
- rebbitMQ的实现原理
引言 你是否遇到过两个(多个)系统间需要通过定时任务来同步某些数据?你是否在为异构系统的不同进程间相互调用.通讯的问题而苦恼.挣扎?如果是,那么恭喜你,消息服务让你可以很轻松地解决这些问题.消息服务擅 ...