Week08_day01 (Hive开窗函数 row_number()的使用 (求出所有薪水前两名的部门))
数据准备:
7369,SMITH,CLERK,7902,1980-12-17,800,null,20
7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30
7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30
7566,JONES,MANAGER,7839,1981-04-02,2975,null,20,
7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981-05-01,2850,null,30
7782,CLARK,MANAGER,7839,1981-06-09,2450,null,10
7788,SCOTT,ANALYST,7566,1987-04-19,3000,null,20
7839,KING,PRESIDENT,null,1981-11-17,5000,null,10
7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30
7876,ADAMS,CLERK,7788,1987-05-23,1100,null,20
7900,JAMES,CLERK,7698,1981-12-03,950,null,30
7902,FORD,ANALYST,7566,1981-12-03,3000,null,20
7934,MILLER,CLERK,7782,1982-01-23,1300,null,10
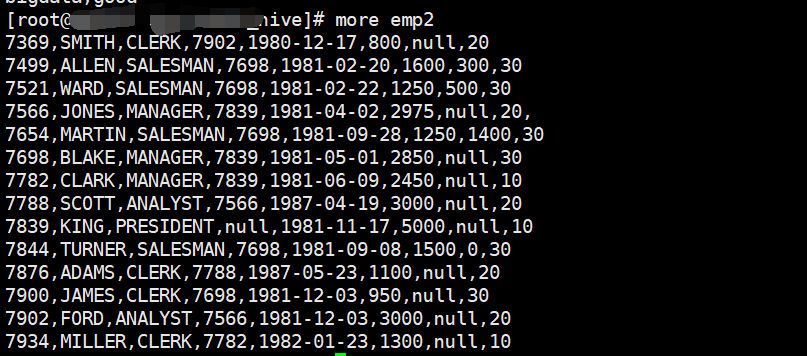
在Hive中创建表(当然建表语句肯定不是这个,这个是字段)
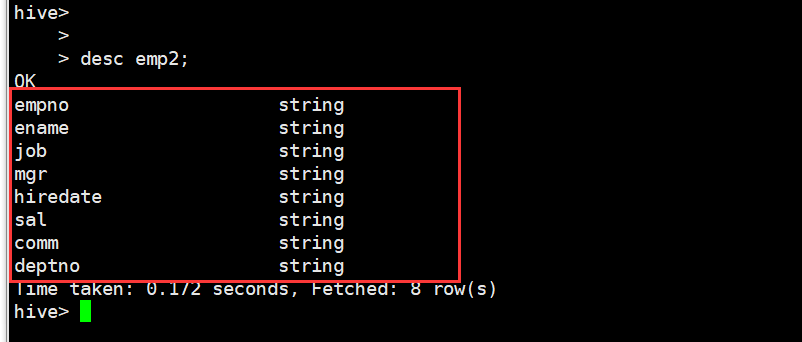
使用本地加载命令加载数据 load data local inpath '文件的绝对路径' into table emp2;
查看
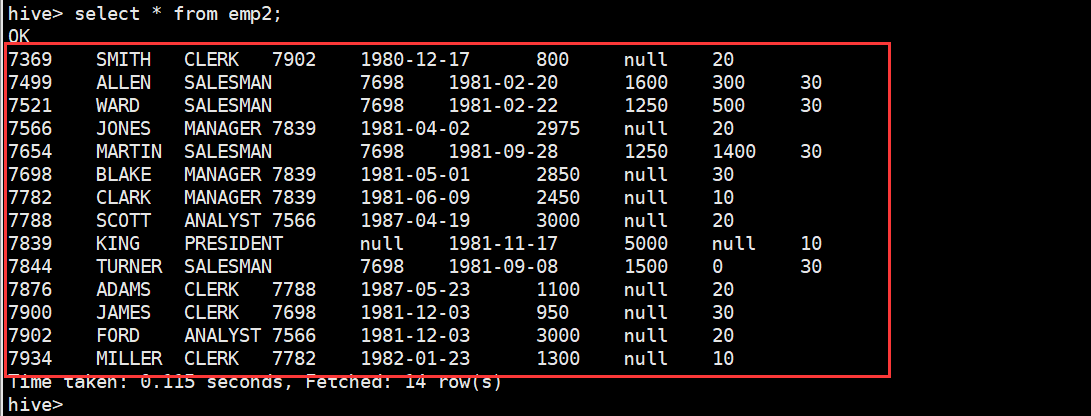
现在有一个需求:求出所有薪水前两名的部门。
第一步,使用开窗函数 row_number()进行分组编号‘降序使用 DESC
select deptno,sal,row_number() over(partition by deptno order by sal desc) from emp2;
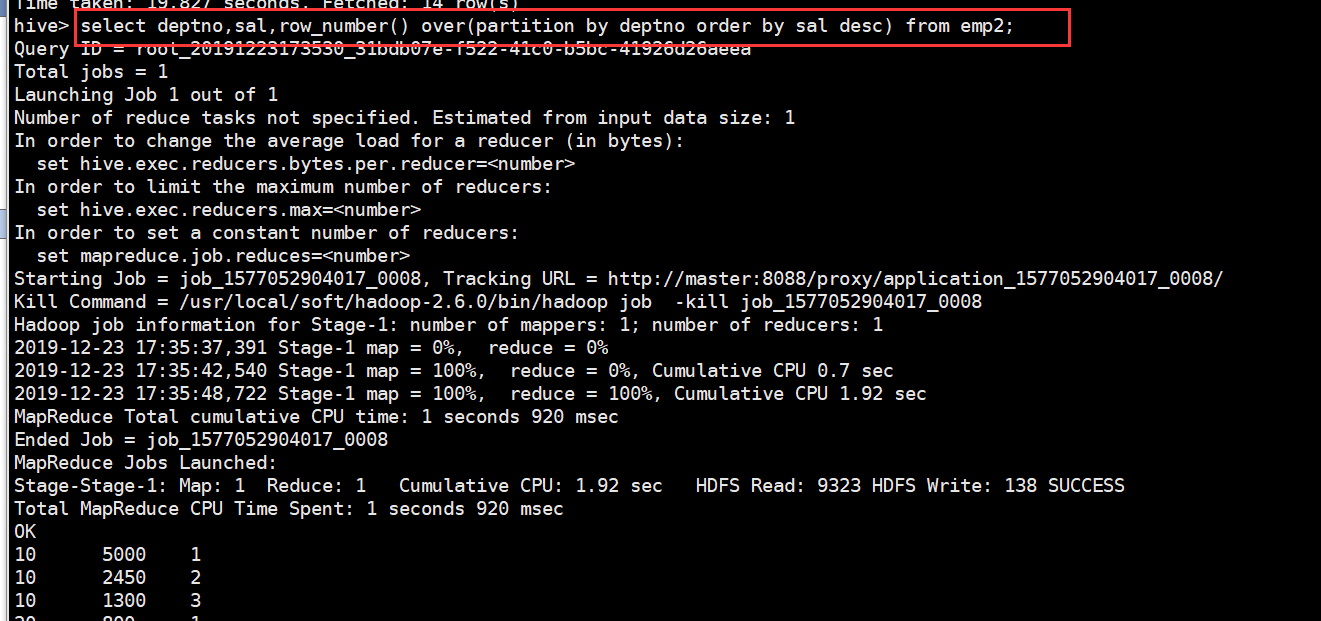
得到如下数据:
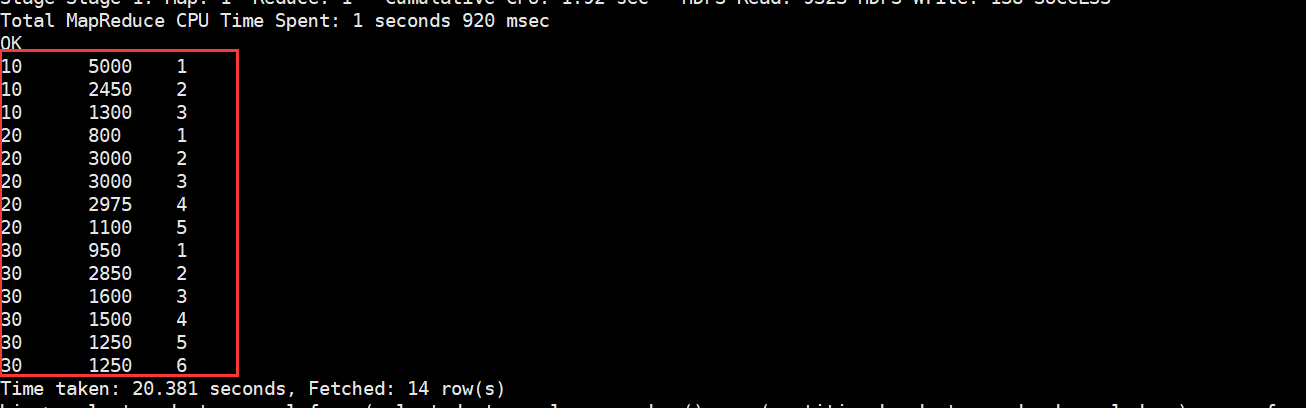
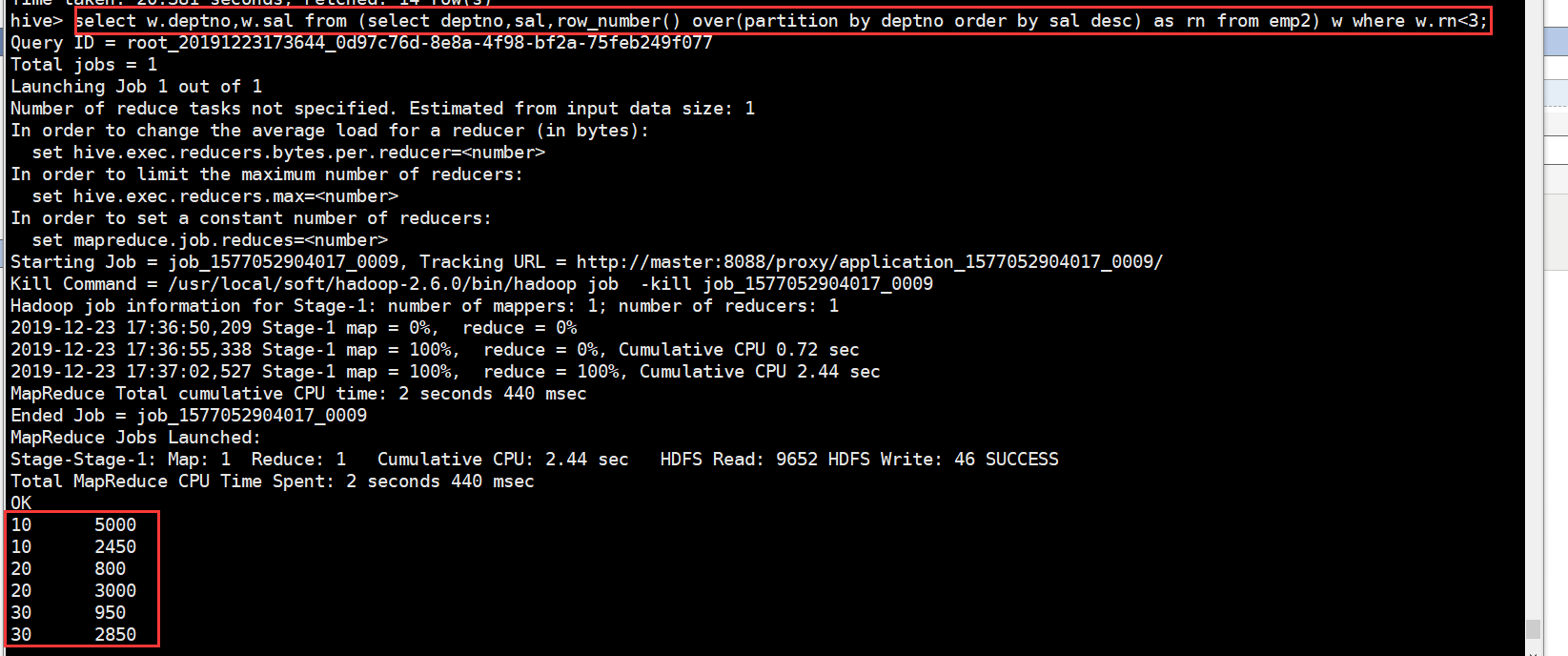
再对其进行分组,取出编号小于3的数据得到结果:
select w.deptno,w.sal from (select deptno,sal,row_number() over(partition by deptno order by sal desc) as rn from emp2) w where w.rn<3;
Week08_day01 (Hive开窗函数 row_number()的使用 (求出所有薪水前两名的部门))的更多相关文章
- 1.hive开窗函数,分析函数
http://yugouai.iteye.com/blog/1908121 分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行.开窗函数指 ...
- SparkSQL开窗函数 row_number()
开始编写我们的统计逻辑,使用row_number()函数 先说明一下,row_number()开窗函数的作用 其实就是给每个分组的数据,按照其排序顺序,打上一个分组内行号 比如说,有一个分组20151 ...
- 2d游戏中求出一个向量的两个垂直向量
function cc.exports.VerticalVector(vec)--求出两个垂直向量 local result = {} result[1] = cc.p(vec.y/vec.x,-1) ...
- hive开窗函数over(partition by ......)用法
一.over(partition by ......)主要和聚合函数sum().count().avg()等结合使用,实现分组聚合的功能 示列:根据day_id日期和mac_id机器码进行聚合分组求每 ...
- Hive开窗函数的理解
1.从一个sql语句开始 select id,sum(price) over(partition by id order by price desc) from books; sum作为聚合函数的时候 ...
- Week08_day01 (Hive 自定义函数 UDF 一个输入,一个输出(最常用))
当我们进入企业就会发现,很多时候,企业的数据都是加密的,我们拿到的数据没办法使用Hive自带的函数去解决,我们就需要自己去定义函数去查看,哈哈,然而企业一般不会将解密的代码给你的,只需要会用,但是我们 ...
- hive SQL 初学者题目,实战题目 字符串函数,日期拼接,开窗函数。。。。
sql:Hive实现按照指定格式输出每七天的消费平均数输出格式:2018-06-01~2018-06-07 12.29...2018-08-10~2018-08-16 80.67 答案:-- 1.先将 ...
- 【Spark篇】---SparkSQL中自定义UDF和UDAF,开窗函数的应用
一.前述 SparkSQL中的UDF相当于是1进1出,UDAF相当于是多进一出,类似于聚合函数. 开窗函数一般分组取topn时常用. 二.UDF和UDAF函数 1.UDF函数 java代码: Spar ...
- over(partition by)开窗函数的使用
开窗函数是分析函数中的一种,开窗函数与聚合函数的区别是:开窗函数是用于计算基于组的某种聚合值且每个的组的聚合计算结果可以有多行,而聚合函数每个组的聚合计算结果只有一个.使用开窗函数可以在没有group ...
随机推荐
- 性能优化-service进程防杀
service作为后台服务,其重要性不言而喻,但很多时候service会被杀死,从而失去了我们原本想要其发挥的作用,在这种情况下我们该如何确保我们的service不被杀死就是本节需要讨论的内容了 se ...
- 记录项目中easyui的运用
1.实现合并列,且文字显示居左,背景为固定颜色 效果图: 实现代码: $('#tab').datagrid({ title : '', //表格标题 iconCls : 'icon-list', // ...
- C语言各数据类型大小和取值范围
- golang 切片和map查询比较
package main import ( "fmt" "time" ) var testTimeSlice = []string{"aa" ...
- Appium移动端自动化测试--元素操作与触摸动作
常见自动化动作支持 click sendKeys swipe touch action 元素操作 1.click()点击操作 也可以用tab实现点击操作 driver.find_element_by_ ...
- python学习-28 map函数
1. num_1 = [10,2,3,4] def map_test(array): ret = [] for i in num_1: ret.append(i**2) # 列表里每个元素都平方 re ...
- Hadoop的理解笔记
1.2Hadoop与云计算的关系1.什么是云计算:一种基于互联网的计算,在其中共享的资源.软件和信息以一种按需的方式提供给计算机和设备 , 就如同日常生活中的电网一样. 什么是Hadoop:Hadoo ...
- docker相关--dockerd日志设置
背景 线上容器dockerd的后台程序打印了超过几十G的日志 Docker daemon日志的位置: Docker daemon日志的位置,根据系统不同各不相同. Ubuntu - /var/log/ ...
- C# Combox控件绑定自定义数据
DataTable dt = new DataTable(); dt.Columns.Add("name"); dt.Columns.A ...
- krpano 全景学习
krpano 切片工具下载 https://krpano.com/tools/ krpano 案例使用 https://krpano.com/examples/usage/#top krpano 是 ...