python urllib应用
urlopen 爬取网页
爬取网页
read() 读取内容
read() , readline() ,readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样
ret = request.urlopen("http://www.baidu.com")
print(ret.read()) #read() 读取网页
urlretrieve 写入文件
直接 将你要爬取得 网页 写到本地
import urllib.request
ret = urllib.request.urlretrieve("url地址","保存的路径地址")
urlcleanup 清除缓存
清除 request.urlretrieve 产生的缓存
print(request.urlcleanup())
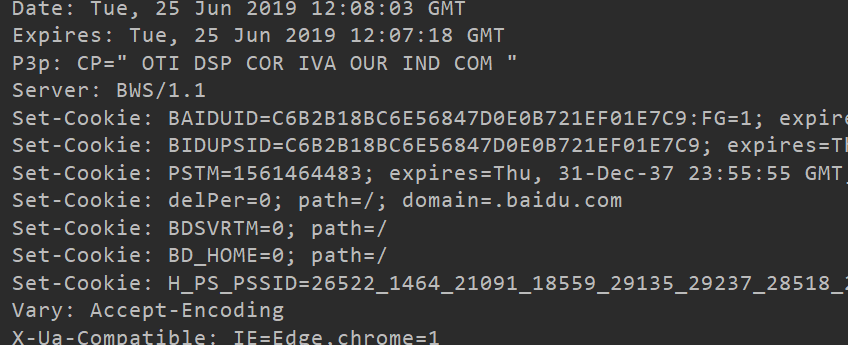
info 显示请求信息
info 返回一个httplib.HTTPMessage对象,表示远程服务器返回的头信息
ret = request.urlopen("http://www.baidu.com")
print(ret.info())
etcode 获取状态码
ret = request.urlopen("http://www.baidu.com")
print(ret.getcode()) # 返回200 就是 正常

geturl 获取当前正在爬取的网址
ret = request.urlopen("http://www.baidu.com")
print(ret.geturl)

超时设置
timeout 是以秒来计算的
ret = request.urlopen("http://www.baidu.com",timeout="设置你的超时时间")
print(ret.read())
模拟get 请求
from urllib import request
name = "python" # 你要搜索的 内容
url = "http://www.baidu.com/s?wd=%s"%name
ret_url = request.Request(url) # 发送请求
ret = request.urlopen(url)
print(ret.read().decode("utf-8"))
print(ret.geturl())
解决中文问题 request.quote
from urllib import request
name = "春生" # 你要搜索的 内容
url = "http://www.baidu.com/s?wd=%s"%name
ret_url = request.Request(url) # 发送请求
ret = request.urlopen(url)
print(ret.read().decode("utf-8"))
print(ret.geturl())

解决 request.quote
name = "春生" # 你要搜索的 内容
name = request.quote(name) # 解决中文问题
url = "http://www.baidu.com/s?wd=%s"%name
ret_url = request.Request(url) # 发送请求
ret = request.urlopen(url)
print(ret.read().decode("utf-8"))
模拟post 请求
from urllib import request, parse
url = "https://www.iqianyue.com/mypost"
mydata = parse.urlencode({
"name":"哈哈",
"pass":"123"
}).encode("utf-8")
ret_url = request.Request(url, mydata) # 发送请求
ret = request.urlopen(ret_url) # 爬取网页
print(ret.geturl()) # 打印当前爬取的url
print(ret.read().decode("utf-8"))
模拟浏览器 发送请求头
request.Request(url, headers=headers) 加上请求头 模拟浏览器
from urllib import request, parse
url = "http://www.xiaohuar.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
ret_url = request.Request(url, headers=headers) # 发送请求
ret = request.urlopen(ret_url)
print(ret.geturl())
print(ret.read().decode("gbk"))
编码出现错误 报错 解决方式
出线的问题
from urllib import request, parse
url = "http://www.xiaohuar.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
ret_url = request.Request(url, headers=headers) # 发送请求
ret = request.urlopen(ret_url)
print(ret.geturl())
print(ret.read().decode("utf-8"))

解决问题
decode("utf-8","ignore")
加上 "ignore" 就可以忽略掉
from urllib import request, parse
url = "http://www.xiaohuar.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
ret_url = request.Request(url, headers=headers) # 发送请求
ret = request.urlopen(ret_url)
print(ret.geturl())
print(ret.read().decode("utf-8","ignore"))

python urllib应用的更多相关文章
- python urllib模块的urlopen()的使用方法及实例
Python urllib 库提供了一个从指定的 URL 地址获取网页数据,然后对其进行分析处理,获取想要的数据. 一.urllib模块urlopen()函数: urlopen(url, data=N ...
- Python:urllib和urllib2的区别(转)
原文链接:http://www.cnblogs.com/yuxc/ 作为一个Python菜鸟,之前一直懵懂于urllib和urllib2,以为2是1的升级版.今天看到老外写的一篇<Python: ...
- Python urllib和urllib2模块学习(一)
(参考资料:现代魔法学院 http://www.nowamagic.net/academy/detail/1302803) Python标准库中有许多实用的工具类,但是在具体使用时,标准库文档上对使用 ...
- python urllib和urllib2 区别
python有一个基础的库叫httplib.httplib实现了HTTP和HTTPS的客户端协议,一般不直接使用,在python更高层的封装模块中(urllib,urllib2)使用了它的http实现 ...
- Python urllib urlretrieve函数解析
Python urllib urlretrieve函数解析 利用urllib.request.urlretrieve函数下载文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 Ur ...
- python+urllib+beautifulSoup实现一个简单的爬虫
urllib是python3.x中提供的一系列操作的URL的库,它可以轻松的模拟用户使用浏览器访问网页. Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能 ...
- HTTP Header Injection in Python urllib
catalogue . Overview . The urllib Bug . Attack Scenarios . 其他场景 . 防护/缓解手段 1. Overview Python's built ...
- python urllib urllib2
区别 1) urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL.这意味着,用urllib时不可以伪装User Agent字符串等. 2) u ...
- python urllib基础学习
# -*- coding: utf-8 -*- # python:2.x __author__ = 'Administrator' #使用python创建一个简单的WEB客户端 import urll ...
- python urllib模块
1.urllib.urlopen(url[,data[,proxies]]) urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像 ...
随机推荐
- maven 引入的jar有出现两种图标
两种同样都引入到maven项目中,但是第二种在打包的过程中会显示找不到jar,无法调用!
- TestCase--网站创建新用户管理模块
对于web测试,用户权限管理模块是必测的一个点,所以今天就来总结一下创建新用户管理模块的测试用例 参考图如下: 测试用例设计如下: 一.功能测试 1. 什么都不输入,单击“立即提交”,页面是否有提示 ...
- redis 队列模式
1.插入队列(生产者) private static RedisClient client = new RedisClient("127.0.0.1", 6379, null);c ...
- socket编程(二)
TCP下粘包问题 两种情况下会发生粘包. 1.发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包) 发送方:AB #其实放在缓存里没发送 发送方:B #其 ...
- mysql order by rand() 优化方法
mysql order by rand() 优化方法 适用于领取奖品等项目<pre>mysql> select * from user order by rand() limit 1 ...
- LeetCode 20. 有效的括号(Valid Parentheses)
20. 有效的括号 20. Valid Parentheses 题目描述 给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效. 有效字符串需满足: 左括号必须 ...
- LeetCode 112. 路径总和(Path Sum) 10
112. 路径总和 112. Path Sum 题目描述 给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和. 说明: 叶子节点是指没有子节点的节 ...
- python基础学习(十四)
28.模块当脚本执行 !!!! 注意 这是分两个文件的 一个是student.py和app3.py student.py name = "Song Ke" name_list ...
- C++ 用 vector 生成三维数组,并计算行、列、高
//Microsoft Visual Studio 2015 Enterprise //用vector生成三维数组,并计算行.列.高 #include <iostream> #includ ...
- typedef用法和陷阱
一.typedef的用法 1.用typedef来声明新的类型名,来代替已有的类型名,也就是给类型起别名.比如 typedef float REAL; //用REAL来代表float类型 REAL a; ...