SparkCore的性能优化
1.广播变量
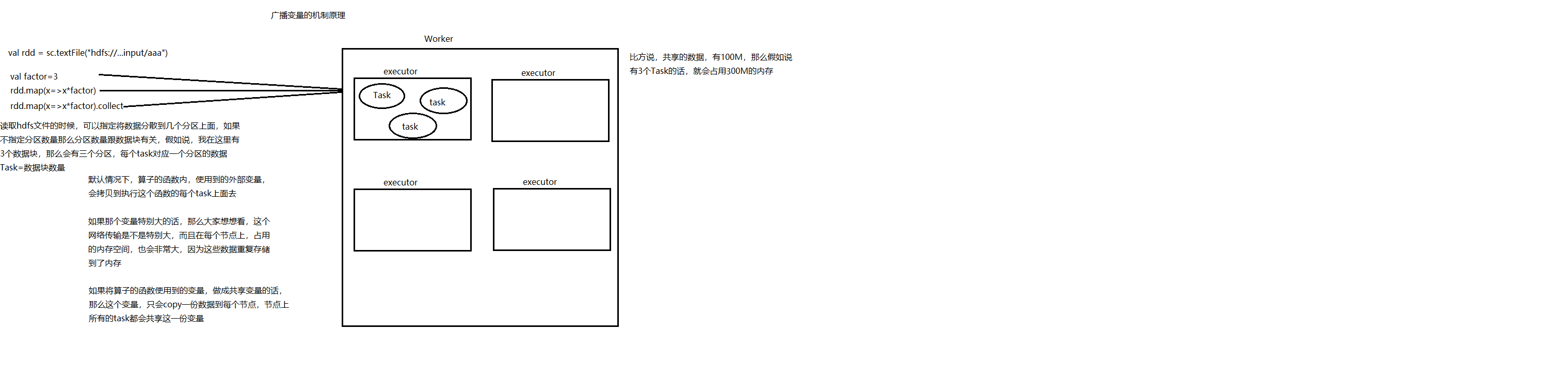
1.1. Spark提供的Broadcast Variable,是只读的,并且在每个节点上只会有一份副本,而不会为每个task都拷贝一份副本
1.2.它的最大作用,就是减少变量到各个节点的网络传输消耗,以及各个节点上的内存消耗
1.3.spark自己内部也是用了高效的广播栓发来减少网络消耗
val factorbroadcast=sc.broadcast(factor)
解读图:
2.1.val rdd=sc.textFile("hdfs://..input/aaa")
读取hdfs文件的时候,可以指定将数据分散到几个分区上面。如果不指定分区数量那么分区数量跟数据块有关
2.2.val factor=3
加入说,我在这里有三个数据块,那么会有三个分区,每个task对应一个分区的数据Task=数据块的数量
2.3.默认情况下,算子的函数内,使用到的外部变量,会拷贝到执行这个函数的task上面去。
2.4.如果那个广播变量特别大的话,这个网络传输也会特别大,而且在每个节点上,占用的内存空间,也会非常到,因为这些数据重复存储到内存
2.5.如果将算子的函数使用到的变量,做到共享变量的话,那么这个变量,只会copy一份数据到每个节点,节点上的所有task都会动向这一份变量
2.缓存
cache既不是tranformation算子也不是action算子
总结:如果内存放不下缓存的数据,那么多余的数据也不会缓存,没有缓存的数据在被使用的时候,需要再次计算
需要注意:
1.缓存的数据不能太大,尽可能缓存需要的数据
2.如果数据只是被使用一簇,那么不要进行缓存,因为缓存后只使用一次的话,性能会降低
3.如果使用完缓存以后,需要及时释放:radd.unperisist(true),否则会始终被占用
3.RDD的Checkpoint(检查点)机制:容错机制
1.检查点(本质是通过RDD写入disk左检查带你)是为了通过lineage(血统)做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销
2.设置checkpoint的目录,可以是本地的文件夹、也可以是HDFS,一般是在具有容错能力,高可靠的文件系统上(比如HDFS, S3等)设置一个检查点路径,用于保存检查点数据
4.访问数据库
//写入mysql
result5.foreachPartition(filter=>{
//创建链接
val conn= DriverManager.getConnection(
"jdbc:mysql://192.168.186.0:3306/test1?serverTimezone=Asia/Shanghai",
"root","")
filter.foreach(tp=>{
//获取sql对象
val ps=conn.prepareStatement("insert into suibian values(?,?)")
//添加字段
ps.setString(,tp._1)
ps.setInt(,tp._2)
//更新
ps.executeUpdate()
//关流
ps.close()
})
conn.close()
})
思考题:
1:SparkContext是在那端生成的?
Driver
2:DAG是在那端构建的?
Driver
3:RDD是在那一端生成的?RDD的分区是在哪一端?
Driver
4:广播变量在那一端进行广播?
Driver
5:要广播的数据应该在那一端创建好再广播?
Driver
6:调用RDD的算子(Tranformation和Action)再那端创建?
Driver
7:RDD再调用Tranformation和Action时需要传入函数,传入的函数是在那一端执行了函数的业务逻辑?
Exceutor
8:自定义分区器这个类实在那一端被实例化?
Driver
9:分区器中的getpartition是在那一端被调用?
Executor端的Task中被执行
10:Task是在那一端生成的?
Driver端生成Task,对Task进行序列化,通过网络发送,Executor接收到Task以后,需要进行反序列化,实现了一个Runable接口的实现类进行包装,丢到线程池进行执行
11:Dag是在那一端构建好并被切分成一个或者多个stage
Driver
12:Dag是哪个类完成的切分Stage的功能?
DAGScheduler
13:DagScheduler将切分好的Stage以什么样的形式给TaskSceduler
TaskSet
SparkCore的性能优化的更多相关文章
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- 03.SQLServer性能优化之---存储优化系列
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 概 述:http://www.cnblogs.com/dunitian/p/60413 ...
- Web性能优化:What? Why? How?
为什么要提升web性能? Web性能黄金准则:只有10%~20%的最终用户响应时间花在了下载html文档上,其余的80%~90%时间花在了下载页面组件上. web性能对于用户体验有及其重要的影响,根据 ...
- Web性能优化:图片优化
程序员都是懒孩子,想直接看自动优化的点:传送门 我自己的Blog:http://cabbit.me/web-image-optimization/ HTTP Archieve有个统计,图片内容已经占到 ...
- C#中那些[举手之劳]的性能优化
隔了很久没写东西了,主要是最近比较忙,更主要的是最近比较懒...... 其实这篇很早就想写了 工作和生活中经常可以看到一些程序猿,写代码的时候只关注代码的逻辑性,而不考虑运行效率 其实这对大多数程序猿 ...
- JavaScript性能优化
如今主流浏览器都在比拼JavaScript引擎的执行速度,但最终都会达到一个理论极限,即无限接近编译后程序执行速度. 这种情况下决定程序速度的另一个重要因素就是代码本身. 在这里我们会分门别类的介绍J ...
- 02.SQLServer性能优化之---牛逼的OSQL----大数据导入
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 上一篇:01.SQLServer性能优化之----强大的文件组----分盘存储 http ...
- C++ 应用程序性能优化
C++ 应用程序性能优化 eryar@163.com 1. Introduction 对于几何造型内核OpenCASCADE,由于会涉及到大量的数值算法,如矩阵相关计算,微积分,Newton迭代法解方 ...
- Android性能优化之利用LeakCanary检测内存泄漏及解决办法
前言: 最近公司C轮融资成功了,移动团队准备扩大一下,需要招聘Android开发工程师,陆陆续续面试了几位Android应聘者,面试过程中聊到性能优化中如何避免内存泄漏问题时,很少有人全面的回答上来. ...
随机推荐
- Python 多线程Ⅲ
线程优先级队列( Queue) Python的Queue模块中提供了同步的.线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列Prior ...
- jq load()方法实现html 模块化。
在我们写项目的时候,会遇到一个模块在多个页面使用,如果没有页面都写一次,那就太费劲了. 如果你使用了框架(vue,react,Angular)的话,那框架都有模块化,可以轻松解决. 如果你使用原生开发 ...
- 微信公众号开发不能使用session原因
今天做微信公众号开发整合功能的时候,使用session保存记录.用postman测试好使,但是一旦用手机就不好使.上网查了好久才明白,微信开发是不能用session的.具体原因如下:因为微信的所有请求 ...
- jQuery.getScript(url, [callback])
jQuery.getScript(url, [callback]) 概述 通过 HTTP GET 请求载入并执行一个 JavaScript 文件.大理石平台精度等级 jQuery 1.2 版本之前,g ...
- TensorFlow使用记录 (八): 梯度修剪 和 Max-Norm Regularization
梯度修剪 梯度修剪主要避免训练梯度爆炸的问题,一般来说使用了 Batch Normalization 就不必要使用梯度修剪了,但还是有必要理解下实现的 In TensorFlow, the optim ...
- vscode编辑器
插件 Auto Close Tag 自动关闭标签 Auto Rename Tag 自动修改标签 Bracket Pair Colorizer 多层括号不同颜色显示 EditorConfig fo ...
- Oracle DBCA工具检测不到ASM磁盘组
本例环境: 操作系统OEL 6.5 数据库版本:11.2.0.4 问题:DBCA建库的时候,检测不到ASM磁盘组 因素一:可能是在授权的时候执行了 chown –R 775 /u01/app等修改权限 ...
- vue-property-decorator知识梳理
仓库地址: /* npm 仓库地址 */ // https://www.npmjs.com/package/vue-property-decorator /* github地址 */ // https ...
- 给string定义一个扩展方法
创建一个 static 的类,并且里面的方法也必须是static的,第一个参数是被扩展的对象,必须标注为this,使用时,必须保证namespace using进来了. 实例: using Syste ...
- Vuex的基本原理与使用
我们需要知道 vue 是单向数据流的方式驱动的 什么是vuex? 为什么要使用vuex ? - 多个视图依赖于同一状态. - 来自不同视图的行为需要变更同一状态. vuex 类似Redux 的状态管理 ...