NLP自然语言处理中英文分词工具集锦与基本使用介绍
一、中文分词工具
(1)Jieba

(2)snowNLP分词工具

(3)thulac分词工具

(4)pynlpir 分词工具

(5)StanfordCoreNLP分词工具
1.from stanfordcorenlp import StanfordCoreNLP
2.with StanfordCoreNLP(r'E:\Users\Eternal Sun\PycharmProjects\1\venv\Lib\stanford-corenlp-full-2018-10-05', lang='zh') as nlp:
3. print("stanfordcorenlp分词:\n",nlp.word_tokenize(Chinese))
(6)Hanlp分词工具

分词结果如下:

二、英文分词工具
1. NLTK:
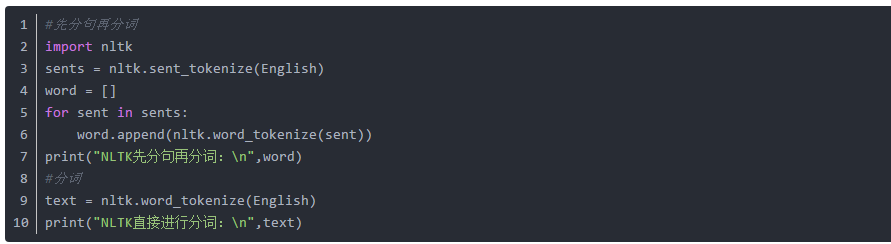
二者之间的区别在于,如果先分句再分词,那么将保留句子的独立性,即生成结果是一个二维列表,而对于直接分词来说,生成的是一个直接的一维列表,结果如下:

2. SpaCy:

3. StanfordCoreNLP:

分词结果

NLP自然语言处理中英文分词工具集锦与基本使用介绍的更多相关文章
- NLP(十三)中文分词工具的使用尝试
本文将对三种中文分词工具进行使用尝试,这三种工具分别为哈工大的LTP,结巴分词以及北大的pkuseg. 首先我们先准备好环境,即需要安装三个模块:pyltp, jieba, pkuseg以及L ...
- 中文分词工具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnltk、snownlp、thulac)
2.1 jieba 2.1.1 jieba简介 Jieba中文含义结巴,jieba库是目前做的最好的python分词组件.首先它的安装十分便捷,只需要使用pip安装:其次,它不需要另外下载其它的数据包 ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- Python分词工具——jieba
jieba简介 python在数据挖掘领域的使用越来越广泛.想要使用python做文本分析,分词是必不可少的一个环节在python的第三方包里,jieba应该算得上是分词领域的佼佼者. GitHub地 ...
- NLP(一) Python常用开发工具
一.Numpy NumPy系统是Python的一种开源的数值计算包. 包括: 1.一个强大的N维数组对象Array: 2.比较成熟的(广播)函数 库: 3.用于整合C/C++和Fortran代码的工具 ...
- NLP 自然语言处理实战
前言 自然语言处理 ( Natural Language Processing, NLP) 是计算机科学领域与人工智能领域中的一个重要方向.它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和 ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- PHP+mysql数据库开发搜索功能:中英文分词+全文检索(MySQL全文检索+中文分词(SCWS))
PHP+mysql数据库开发类似百度的搜索功能:中英文分词+全文检索 中文分词: a) robbe PHP中文分词扩展: http://www.boyunjian.com/v/softd/robb ...
- 开源中文分词工具探析(五):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
随机推荐
- xml配置文件 操作
public class ConfigFile { protected readonly string configBasePath = "Root/Config"; /// &l ...
- ga
https://developers.google.com/analytics/devguides/collection/gtagjs/events ga 添加事件示例: 在代码中指定您自己的值,就可 ...
- CDOJ 1135 邱老师看电影 概率dp
邱老师看电影 Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) Submit St ...
- (Java多线程系列二)线程间同步
Java多线程间同步 1.什么是线程安全 通过一个案例了解线程安全 案例:需求现在有100张火车票,有两个窗口同时抢火车票,请使用多线程模拟抢票效果. 先来看一个线程不安全的例子 class Sell ...
- $message的问题
项目中出现$message的问题: 拉取数据成功后 this.$message.success("数据拉取成功")点击拉取第一次不出现,但是代码执行了,后来多次点击就出现了 原因: ...
- zookeeper系列(六)zookeeper的系统模型(数据树)
作者:leesf 掌控之中,才会成功:掌控之外,注定失败. 出处:http://www.cnblogs.com/leesf456/p/6072597.html尊重作者原创,奇文共欣赏,大家共同学 ...
- flask第二篇 三剑客+特殊返回值
1.Flask中的HTTPResponse 在Flask 中的HttpResponse 在我们看来其实就是直接返回字符串 2.Flask中的Redirect 每当访问"/redi" ...
- Linux远程连接工具 Shell Xshell6 XFtp6 绿色破解免安装版
百度云下载链接: https://pan.baidu.com/s/1HMkuxv1yaAM1yhtz09zpfQ 关注以下公众号,回复xshell,获取提取码 关注公众号githubcn,免费获取更多 ...
- LeetCode 136. 只出现一次的数字(Single Number)
题目描述 给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次.找出那个只出现了一次的元素. 说明: 你的算法应该具有线性时间复杂度. 你可以不使用额外空间来实现吗? 示例 1: ...
- excel中如何设置只打印第一页
在打印表格时,怎样设置只打印第一页呢,操作很简单,下面,小编说下操作方法. 方法/步骤 打开要打印的工作表, 再点击“文件” 弹出的页面中,在左侧这里,点击“打印” 在右边弹出与打 ...