Spark + sbt + IDEA + HelloWorld + MacOS
构建项目步骤
首先要安装好scala、sbt、spark,并且要知道对应的版本
- sbt版本可以在sbt命令行中使用
sbtVersion查看 spark-shell可以知晓机器上spark以及对应的scala的版本
- sbt版本可以在sbt命令行中使用
IDEA中plugin安装scala插件
- pass
修改配置文件改变IDEA下sbt依赖下载速度慢的问题
参考官网:
 
具体做法:
vi ~/.sbt/repositories
<---加入--->
[repositories]
local
oschina: http://maven.aliyun.com/nexus/content/groups/public/
jcenter: http://jcenter.bintray.com/
typesafe-ivy-releases: http://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
maven-central: http://repo1.maven.org/maven2/
<---结束--->
并在IDEA中找到sbt下的VM parameters,往其中加入:
-Xmx2048M
-XX:MaxPermSize=512m
-XX:ReservedCodeCacheSize=256m
-Dsbt.log.format=true
-Dsbt.global.base=/Users/shayue/.sbt (这里应该替换成.sbt所在地址,下同)
-Dsbt.boot.directory=/Users/shayue/.sbt/boot/
-Dsbt.ivy.home=/Users/shayue/.ivy2 (这里应该替换成.ivy2所在地址,下同)
-Dsbt.override.build.repos=true
-Dsbt.repository.config=/Users/shayue/.sbt/repositories
其中倒数第二句是Jetbrain给出的官方做法,参考https://www.scala-sbt.org/1.0/docs/Command-Line-Reference.html#Command+Line+Options 的最后一行
通过sbt构建scala项目,选对版本
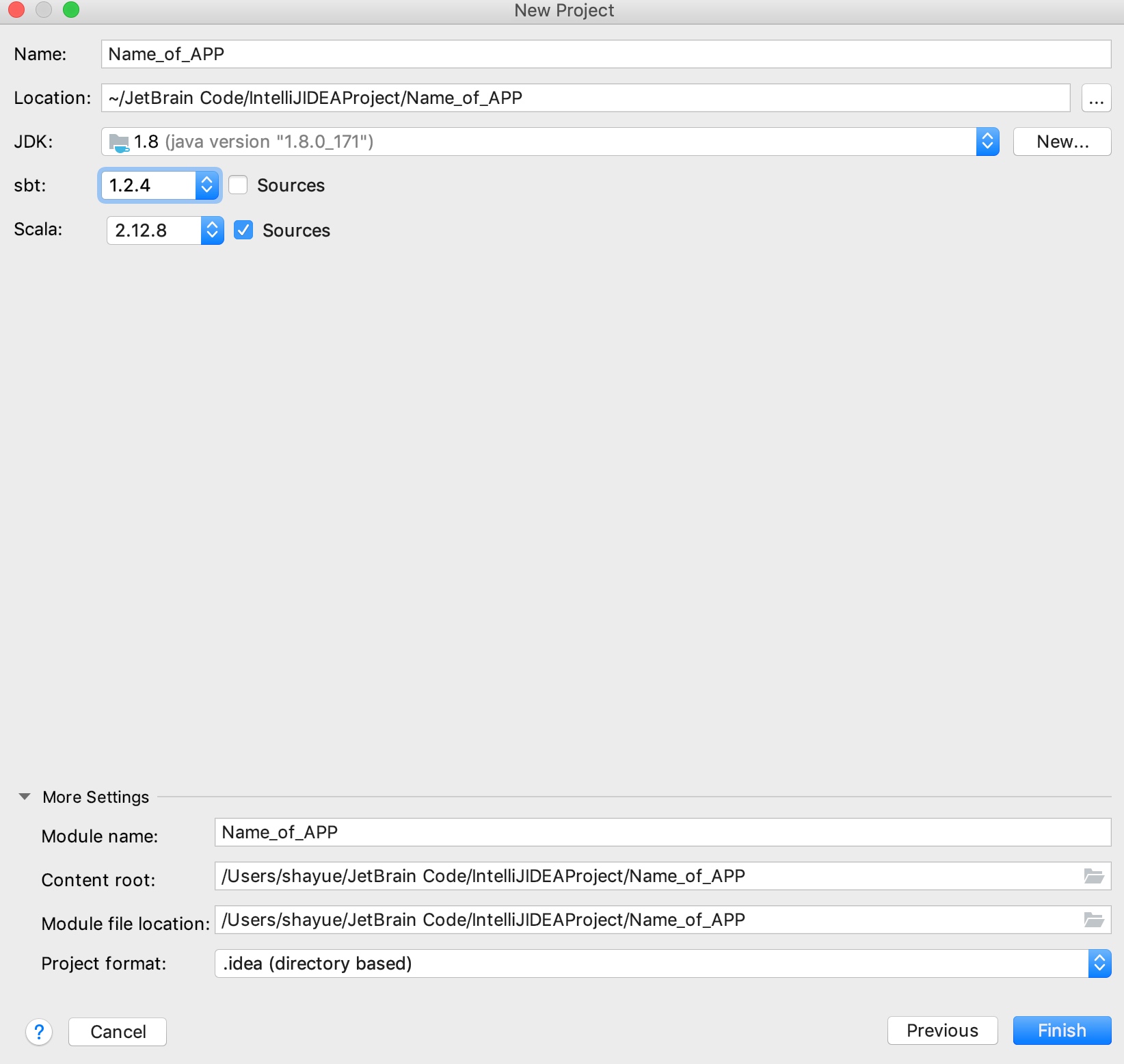 
修改build.sbt和build.properties,在其中加入适合的版本,并引入Spark依赖
# build.sbt
name := "Name_of_APP" version := "0.1" scalaVersion := "2.12.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.2"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.2" # build.properties
sbt.version = 1.2.4其中spark的依赖可以通过spark下载页面找到,或者参考http://spark.apache.org/docs/latest/rdd-programming-guide.html 中的Link with Spark
代码
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.log4j.{Level,Logger}
object ScalaApp {
def main(args: Array[String]) {
//屏蔽启动spark等日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
// 设置数据路径
val path = "/Users/shayue/Sample_Code/Machine-Learning-with-Spark/Chapter01/scala-spark-app/data/UserPurchaseHistory.csv"
// 初始化SparkContext
val sc = new SparkContext("local[2]", "First Spark App")
// 将 CSV 格式的原始数据转化为(user,product,price)格式的记录集
val data = sc.textFile(path)
.map(line => line.split(","))
.map(purchaseRecord => (purchaseRecord(0), purchaseRecord(1), purchaseRecord(2)))
// 求购买总次数
val numPurchases = data.count()
// 求有多少个不同用户购买过商品
val uniqueUsers = data.map{ case (user, product, price) => user }.distinct().count()
// 求和得出总收入
val totalRevenue = data.map{ case (user, product, price) => price.toDouble }.sum()
// 求最畅销的产品是什么
val productsByPopularity = data
.map{ case (user, product, price) => (product, 1) }
.reduceByKey(_ + _ ).collect()
.sortBy(-_._2)
val mostPopular = productsByPopularity(0)
// 打印
println("Total purchases: " + numPurchases)
println("Unique users: " + uniqueUsers)
println("Total revenue: " + totalRevenue)
println("Most popular product: %s with %d purchases" .format(mostPopular._1, mostPopular._2))
}
}
输出:
Total purchases: 5
Unique users: 4
Total revenue: 39.91
Most popular product: iPhone Cover with 2 purchases
参考
- 第一张VM parameter修改参考https://blog.csdn.net/jameshadoop/article/details/522957109153012.html
- 代码来自《Spark机器学习》第二版
Spark + sbt + IDEA + HelloWorld + MacOS的更多相关文章
- IDEA 学习笔记之 Spark/SBT项目开发
Spark/SBT项目开发: 下载Scala SDK 下载SBT 配置IDEA SBT:(如果不配置,就会重新下载SBT, 非常慢,因为以前我已经下过了,所以要配置为过去使用的SBT) 新建立SBT项 ...
- Eclipse + Idea + Maven + Scala + Spark +sbt
http://jingpin.jikexueyuan.com/article/47043.html 新的scala 编译器idea使用 https://www.jetbrains.com/idea/h ...
- spark入门(helloworld插件)
1 http://www.cnblogs.com/openfire/archive/2013/04/26/3044722.html 2 在bulid文件夹下,(注意为主目录不是插件下的bulid.xm ...
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- Spark环境搭建(六)-----------sprk源码编译
想要搭建自己的Hadoop和spark集群,尤其是在生产环境中,下载官网提供的安装包远远不够的,必须要自己源码编译spark才行. 环境准备: 1,Maven环境搭建,版本Apache Maven 3 ...
- sbt安装
使用 Scala 编写的程序需要使用 sbt 进行编译打包,官网sbt下载解压 在解压路径下创建脚本: #!/bin/bash SBT_OPTS="-Xms512M -Xmx1536M -X ...
- Spark和pyspark的配置安装
如何安装Spark和Pyspark构建Spark学习环境[MacOs] JDK环境 Python环境 Spark引擎 下载地址:Apache-Spark官网 MacOs下一般安装在/usr/local ...
- 查看Spark与Hadoop等其他组件的兼容版本
安装与Spark相关的其他组件的时候,例如JDK,Hadoop,Yarn,Hive,Kafka等,要考虑到这些组件和Spark的版本兼容关系.这个对应关系可以在Spark源代码的pom.xml文件中查 ...
随机推荐
- Ubuntu安装依赖文件
我们在安装软件的时候,有时会出现由于依赖的软件没有被安装,会导致软件安装的失败,其实我们可以用命令来安装依赖的软件,这里以Ubuntu为例进行说明. 我在安装wps-office的时候,显示安装成功了 ...
- python自动华 (八)
Python自动化 [第八篇]:Python基础-Socket编程进阶 本节内容: Socket语法及相关 SocketServer实现多并发 1. Socket语法及相关 sk = socket.s ...
- tarjan等
有向图注意v在栈中时,才用dfn更新low.无向图不用判断这个. SCC和边双,都是在返回时判断low==dfn. 点双就是找割点,low(v)>=dfn(u)时,把tarjan(v)过程中放入 ...
- 彻底搞清楚setState
setState最常见的问题是,是异步的还是同步的? setState在React.Component中的函数,是同步函数.但是我们调用的时候,不同的传参和不同的调用位置都会导致不同的结果. 从页面看 ...
- SpingMVC入门
Springmvc简介及配置 1. 什么是springMVC? Spring Web MVC是一种基于Java的实现了MVC设计模式的.请求驱动类型的.轻量级Web框架. 2. SpringMVC处理 ...
- UDP广播,组播服务器
广播 #include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/ ...
- 【概率论】1-3:组合(Combinatorial Methods)
title: [概率论]1-3:组合(Combinatorial Methods) categories: Mathematic Probability keywords: Combination 组 ...
- Asp.Net跨平台 Jexus 5.8.1 独立版
在Linux上运行ASP.NET网站或WebApi的传统步骤是,先安装libgdiplus,再安装mono,然后安装Jexus.在这个过程中,虽然安装Jexus是挺简便的一件事,但是安装mono就相对 ...
- Hdu5178
Hdu5178 题意: 题目给你N个点,问有多少对点的长度小于K . 解法: 首先将所给的坐标从大到小排序,则此题转化为:对排序后的新数列,对每个左边的\(x_a\)找到它右边最远的 $ x_b $ ...
- HTML页面预览表格文件内容
背景简介 在将一个表格文件上传到服务器上之前,JS读取表格文件并将文件内容输出到页面中 vue项目 第三方 exceljs 安装 npm install exceljs 插件使用 github 中文文 ...