MLN 讨论 —— inference
We consider two types of inference:
- finding the most likely state of the world consistent with some evidence
- computing arbitrary conditional probabilities.
We then discuss two approaches to making inference more tractable on large , relational problems:
- lazy inference , in which only the groundings that deviate from a "default" value need to be instantiated;
- lifted inference , in which we group indistinguishable atoms together and treat them as a single unit during inference;
3.1 Inference the most probable explanation
A basic inference task is finding the most probable state of the world y given some evidence x, where x is a set of literals;
Formula
For Markov logic , this is formally defined as follows: $$ \begin{align} arg \; \max_y P(y|x) & = arg \; \max_y \frac{1}{Z_x} exp \left( \sum_i w_in_i(x, \; y) \right) \tag{3.1} \\ & = arg \; \max_y \sum_i w_in_i(x, \; y) \tag{3.1} \end{align} $$
$n_i(x, y)$: the number of true groundings of clause $i$ ;
The problem reduces to finding the truth assignment that maximizes the sum of weights of satisfied clauses;
Method
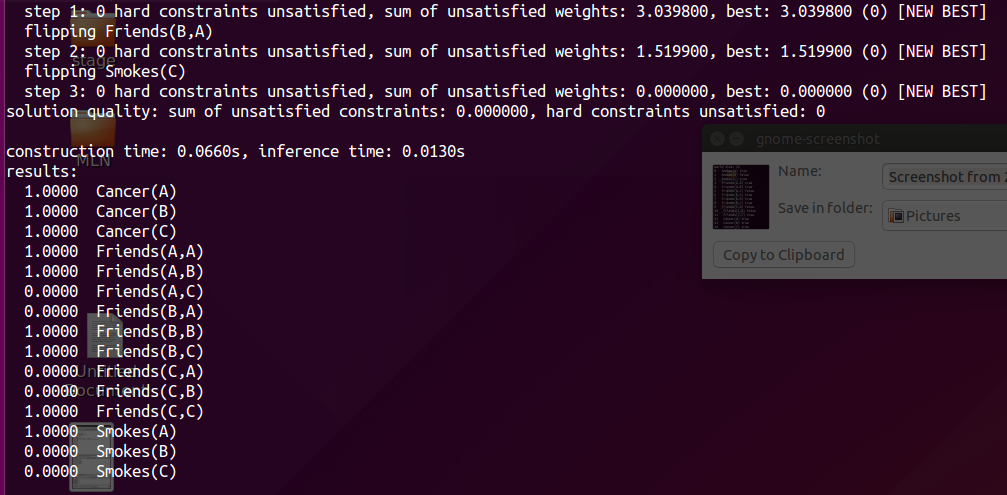
MaxWalkSAT:
Repeatedly picking an unsatisfied clause at random and flipping the truth value of one of the atoms in it.
With a certain probability , the atom is chosen randomly;
Otherwise, the atom is chosen to maximize the sum of satisfied clause weights when flipped;

DeltaCost($v$) computes the change in the sum of weights of unsatisfied clauses that results from flipping variable $v$ in the current solution.
Uniform(0,1) returns a uniform deviate from the interval [0,1]
Example
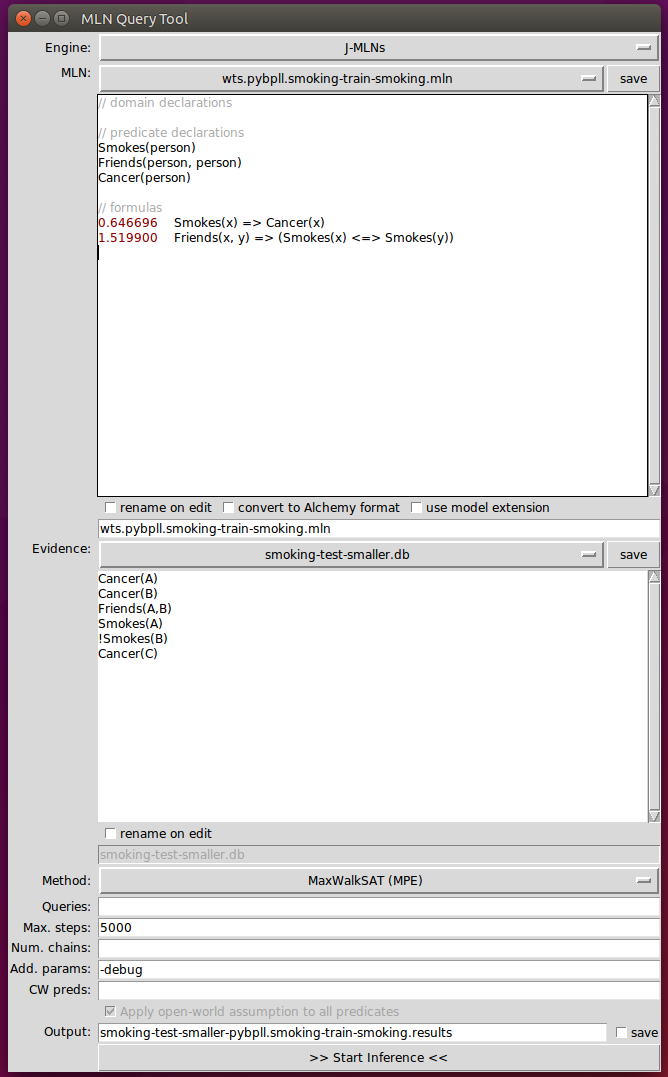
Step1: convert Formula to CNF
0.646696 $\lnot$Smokes(x) $\lor$ Cancer(x)
1.519900 ( $\lnot$Friends(x,y) $\lor$ $\lnot$Smokes(x) $\lor$ Smokes(y)) $\land$ ( $\lnot$Friends(x,y) $\lor$ $\lnot$Smokes(y) $\lor$ Smokes(x))
Clauses:
- $\lnot$Smokes(x) $\lor$ Cancer(x)
- $\lnot$Friends(x,y) $\lor$ $\lnot$Smokes(x) $\lor$ Smokes(y)
- $\lnot$Friends(x,y) $\lor$ $\lnot$Smokes(y) $\lor$ Smokes(x)
Atoms: Smokes(x) 、Cancer(x) 、Friends(x,y)
Constant: {A, B, C}
Step2: Propositionalizing the domain

The truth value of evidences is depent on themselves;
The truth value of others is assigned randomly;
C:#constant ; $\alpha(F_i)$: the arity of $F_i$ ;
world size = $\sum_{i}C^{\alpha(F_i)}$ 指数级增长!!!
Step3: MaxWalkSAT
3.2 Computing conditional Probabilities
MLNs can answer arbitraty queries of the form "What is the probability that formula $F_1$ holds given that formula $F_2$ does?". If $F_1$ and $F_2$ are two formulas in first-order logic, C is a finite set of constants including any constants that appear in $F_1$ or $F_2$, and L is an MLN, then $$ \begin{align} P(F_1|F_2, L, C) & = P(F_1|F_2,M_{L,C}) \tag{3.2} \\ & = \frac{P(F_1 \land F_2 | M_{L,C})}{P(F_2|M_{L,C})} \tag{3.2} \\ & = \frac{\sum_{x \in \chi_{F_1} \cap \chi_{F_2} P(X=x|M_{L,C}) }}{\sum_{x \in \chi_{F_2}P(X=x|M_{L, C})}} \tag{3.2} \end{align} $$
where $\chi_{f_i}$ is the set of worlds where $F_i$ holds, $M_{L,C}$ is the Markov network defined by L and C;
Problem
MLN inference subsumes probabilistic inference, which is #P-complete, and logical inference, which is NP-complete;
Method: 数据的预处理
We focus on the case where $F_2$ is a conjunction of ground literals , this is the most frequent type in practice.
In this scenario, further efficiency can be gained by applying a generalization of knowledge-based model construction.
The basic idea is to only construct the minimal subset of the ground network required to answer the query.
This network is construct by checking if the atoms that the query formula directly depends on are in the evidence. If they are, the construction is complete. Those that are not are added to the network, and we in turn check the atoms they depend on. This process is repeated until all relevant atoms have been retrieved;
Markov blanket : parents + children + children's parents , BFS

example

Once the network has been constructed, we can apply any standard inference technique for Markov networks, such as Gibbs sampling;
Problem
One problem with using Gibbs sampling for inference in MLNs is that it breaks down in the presence of deterministic or near-deterministic dependencies. Deterministc dependencies break up the space of possible worlds into regions that are not reachable from each other, violating a basic requirement of MCMC. Near-deterministic dependencies greatly slow down inference, by creating regions of low probability that are very difficult to traverse.
Method
The MC-SAT is a slice sampling MCMC algorithm which uses a combination of satisfiability testing and simulated annealing to sample from the slice. The advantage of using a satisfiability solver(WalkSAT) is that it efficiently finds isolated modes in the distribution, and as a result the Markov chain mixes very rapidly.
Slice sampling is an instance of a widely used approach in MCMC inference that introduces auxiliary variables, $u$, to capture the dependencies between observed variables, $x$. For example, to sample from P(X=$x$) = (1/Z) $\prod_k \phi_k(x_{\{k\}})$, we can define P(X=$x$, U=$u$)=(1/Z) $\prod_k I_{[0, \; \phi_k(x_{\{k\}})]}(u_k)$
MLN 讨论 —— inference的更多相关文章
- MLN 讨论 —— 基础知识
一. MLN相关知识的介绍 1. First-order logic A first-order logic knowledge base (KB) is a set of formulas in f ...
- pgm5
这部分讨论 inference 里面基本的问题,即计算 这类 query,这一般可以认为等价于计算 ,因为我们只需要重新 normalize 一下关于 的分布就得到了需要的值,特别是像 MAP 这类 ...
- 论文笔记:Integrated Object Detection and Tracking with Tracklet-Conditioned Detection
概要 JiFeng老师CVPR2019的另一篇大作,真正地把检测和跟踪做到了一起,之前的一篇大作FGFA首次构建了一个非常干净的视频目标检测框架,但是没有实现帧间box的关联,也就是说没有实现跟踪.而 ...
- PRML读书会第十章 Approximate Inference(近似推断,变分推断,KL散度,平均场, Mean Field )
主讲人 戴玮 (新浪微博: @戴玮_CASIA) Wilbur_中博(1954123) 20:02:04 我们在前面看到,概率推断的核心任务就是计算某分布下的某个函数的期望.或者计算边缘概率分布.条件 ...
- 听同事讲 Bayesian statistics: Part 2 - Bayesian inference
听同事讲 Bayesian statistics: Part 2 - Bayesian inference 摘要:每天坐地铁上班是一件很辛苦的事,需要早起不说,如果早上开会又赶上地铁晚点,更是让人火烧 ...
- <A Decomposable Attention Model for Natural Language Inference>(自然语言推理)
http://www.xue63.com/toutiaojy/20180327G0DXP000.html 本文提出一种简单的自然语言推理任务下的神经网络结构,利用注意力机制(Attention Mec ...
- Intelligence Beyond the Edge: Inference on Intermittent Embedded Systems
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 以下是对本文关键部分的摘抄翻译,详情请参见原文. Abstract 能量收集技术为未来的物联网应用提供了一个很有前景的平台.然而,由于这些 ...
- [NodeJS] 优缺点及适用场景讨论
概述: NodeJS宣称其目标是“旨在提供一种简单的构建可伸缩网络程序的方法”,那么它的出现是为了解决什么问题呢,它有什么优缺点以及它适用于什么场景呢? 本文就个人使用经验对这些问题进行探讨. 一. ...
- CSS常见居中讨论
先来一个常见的案例,把一张图片和下方文字进行居中: 首先处理左右居中,考虑到img是一个行内元素,下方的文字内容也是行内元素,因此直接用text-align即可: <style> .con ...
随机推荐
- springboot中使用cache和redis
知识点:springboot中使用cache和redis (1)springboot中,整合了cache,我们只需要,在入口类上加 @EnableCaching 即可开启缓存 例如:在service层 ...
- JavaScript001,鼠标点击改变文字或图片
<h3>我的第一个Javascript</h3> <p id="demo1">1.点击按钮,改变内容!</p> <!-- 设置 ...
- JavaScript基础习题
1.实现输入框的双向绑定 解析:所谓双向绑定,即view->model, model->view,可以考虑对象劫持,监听对象属性的变化 <input type="input ...
- 3.使用webpack配置文件webpack.confg.js配置打包文件的入口和出口
在项目根目录下新建webpack.config.js文件 webpack.config.js文件配置如下: // Node的路径操作使用的是path模块 const path=require('pat ...
- [转载]Java 应用性能调优实践
Java 应用性能调优实践 Java 应用性能优化是一个老生常谈的话题,笔者根据个人经验,将 Java 性能优化分为 4 个层级:应用层.数据库层.框架层.JVM 层.通过介绍 Java 性能诊断工具 ...
- 安装卸载JDK
卸载JDK 删除Java的安装目录 删除JAVA_HOME 删除path下关于Java的目录 java-version 安装JDK 百度搜索JDK8,找到下载地址 同意协议 下载电脑对应的版本 双击安 ...
- node.js接收异步任务结果的两种方法----callback和事件广播
事件广播 发送方调用emit方法,接收方调用on方法,无论发送方或是接收方,都会工作在一个频道 声明了一个模块,用于读取mime.json中的记录 var fs = require('fs'); va ...
- .Net Core:Middleware自定义中间件
新建standard类库项目,添加引用包 Microsoft.AspNetCore 1.扩展IApplicationBuilder using Microsoft.AspNetCore.Builder ...
- 题解[NOIP2017] 列队
题解[NOIP2017] 列队 题面 解析 看到这题时感觉这个编号很难维护啊? 后来看了lzf大佬的题解才会.. 首先,考虑一个稍微暴力的做法, 维护每一行的前\(m-1\)个人和最后一列的\(n\) ...
- vue使用Echarts图表
vue使用Echarts图表 童话_xxv 关注 0.5 2018.12.11 09:09* 字数 325 阅读 1456评论 2喜欢 13 在开发后台系统时,使用图表进行数据可视化,这样会使数据更 ...