【Hadoop学习之十】MapReduce案例分析二-好友推荐
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
最应该推荐的好友TopN,如何排名?
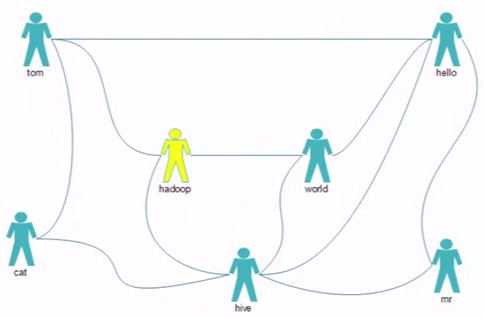

tom hello hadoop cat
world hadoop hello hive
cat tom hive
mr hive hello
hive cat hadoop world hello mr
hadoop tom hive world
hello tom world hive mr
package test.mr.fof; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class MyFOF { /**
* 最应该推荐的好友TopN,如何排名? * @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(true);
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
conf.set("sleep", otherArgs[2]); Job job = Job.getInstance(conf,"FOF");
job.setJarByClass(MyFOF.class); //Map
job.setMapperClass(FMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //Reduce
job.setReducerClass(FReducer.class); //HDFS 输入路径
Path input = new Path(otherArgs[0]);
FileInputFormat.addInputPath(job, input );
//HDFS 输出路径
Path output = new Path(otherArgs[1]);
if(output.getFileSystem(conf).exists(output)){
output.getFileSystem(conf).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output ); System.exit(job.waitForCompletion(true) ? 0 :1);
}
// tom hello hadoop cat
// world hadoop hello hive
// cat tom hive
// mr hive hello
// hive cat hadoop world hello mr
// hadoop tom hive world
// hello tom world hive mr }
package test.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils; public class FMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text mkey= new Text();
IntWritable mval = new IntWritable(); @Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException { //value: 0-直接关系 1-间接关系
//tom hello hadoop cat : hello:hello 1
//hello tom world hive mr hello:hello 0 String[] strs = StringUtils.split(value.toString(), ' '); String user=strs[0];
String user01=null;
for(int i=1;i<strs.length;i++){
//与好友清单中好友属于直接关系
mkey.set(fof(strs[0],strs[i]));
mval.set(0);
context.write(mkey, mval); for (int j = i+1; j < strs.length; j++) {
Thread.sleep(context.getConfiguration().getInt("sleep", 0));
//好友列表内 成员之间是间接关系
mkey.set(fof(strs[i],strs[j]));
mval.set(1);
context.write(mkey, mval);
}
}
} public static String fof(String str1 , String str2){ if(str1.compareTo(str2) > 0){
//hello,hadoop
return str2+":"+str1;
}
//hadoop,hello
return str1+":"+str2;
} }
package test.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class FReducer extends Reducer<Text, IntWritable, Text, Text> { Text rval = new Text();
@Override
protected void reduce(Text key, Iterable<IntWritable> vals, Context context)
throws IOException, InterruptedException
{
//是简单的好友列表的差集吗?
//最应该推荐的好友TopN,如何排名? //hadoop:hello 1
//hadoop:hello 0
//hadoop:hello 1
//hadoop:hello 1
int sum=0;
int flg=0;
for (IntWritable v : vals)
{
//0为直接关系
if(v.get()==0){
//hadoop:hello 0
flg=1;
}
sum += v.get();
} //只有间接关系才会被输出
if(flg==0){
rval.set(sum+"");
context.write(key, rval);
}
}
}
【Hadoop学习之十】MapReduce案例分析二-好友推荐的更多相关文章
- MapReduce深度分析(二)
MapReduce深度分析(二) 五.JobTracker分析 JobTracker是hadoop的重要的后台守护进程之一,主要的功能是管理任务调度.管理TaskTracker.监控作业执行.运行作业 ...
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- 【Hadoop学习之十三】MapReduce案例分析五-ItemCF
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 推荐系统——协同过滤(Collab ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- [b0012] Hadoop 版hello word mapreduce wordcount 运行(二)
目的: 学习Hadoop mapreduce 开发环境eclipse windows下的搭建 环境: Winows 7 64 eclipse 直接连接hadoop运行的环境已经搭建好,结果输出到ecl ...
- 【第二课】kaggle案例分析二
Evernote Export 推荐系统比赛(常见比赛) 推荐系统分类 最能变现的机器学习应用 基于应用领域分类:电子商务推荐,社交好友推荐,搜索引擎推荐,信息内容推荐等 **基于设计思想:**基于协 ...
- 【Hadoop学习之十二】MapReduce案例分析四-TF-IDF
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 概念TF-IDF(term fre ...
- 【Hadoop学习之九】MapReduce案例分析一-天气
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 找出每个月气温最高的2天 1949 ...
随机推荐
- python摸爬滚打之day010----函数进阶
1.函数动态传参 *args : 将所有的位置参数打包成一个元组的形式. **kwargs : 将所有的关键字参数打包成一个字典的形式. 形参的接收顺序: 位置参数 > *args > ...
- MySQL中varchar最大长度是多少?
一. varchar存储规则: 4.0版本以下,varchar(20),指的是20字节,如果存放UTF8汉字时,只能存6个(每个汉字3字节) 5.0版本以上,varchar(20),指的是20字符,无 ...
- 文件压缩:zip
[root@localhost ~]# yum install -y zip unzip // 安装 zip 和 unzip [root@localhost ~]# ..txt // 压缩文件,要同时 ...
- shell分析日志常用指令合集
数据分析对于网站运营人员是个非常重要的技能,日志分析是其中的一个.日志分析可以用专门的工具进行分析,也可以用原生的shell脚本执行,下面就随ytkah看看shell分析日志常用指令有哪些吧.(log ...
- SQL assistant
SQL assistant取消自动生成别名 SQL assistant-->Options-->DB option -->SQL Servers-->Auto Complete ...
- 003-JSR303校验
一.JSR303校验 1.1.概述 JSR-303 是 JAVA EE 6 中的一项子规范,叫做 Bean Validation,官方参考实现是Hibernate Validator. 此实现与 Hi ...
- golang gui library 库
andlabs/ui已经重写,稳定性增强,但是组件很少,只提供了几种基础的控件,慎用.gxui死了,别用.linuxdeepin转QT了,所以…… windows系统最好的选择是walk. 首先,写w ...
- sap 对dynamic query parameters 设置条件。
- 将 context node 中的内容 分配给 desing layer
1 将 context node 中的内容 分配给 desing layer 选中context node 右键>assignment to design layer.
- Android使用SpannableString设置多样式文本
Android将一行文本设置为多种样式时,可以使用 SpannableString 来实现 private void setTips(){ String big = "大字深色"; ...