4.无监督学习--K-means聚类
K-means方法及其应用
1.K-means聚类算法简介:
k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。主要处理过程包括:
1.随机选择k个点作为初始的聚类中心。
2.对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇。
3.对每个簇,计算所有点的均值作为新的聚类中心。
4.重复2、3直到聚类中心不再发生改变。
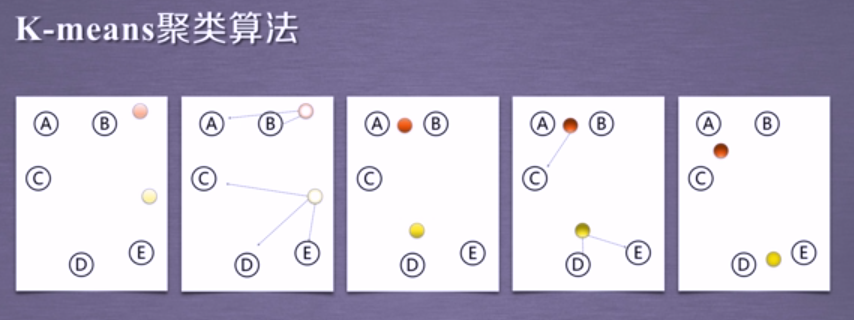
举例:对于A、B、C、D、E这5个点,我们先随机选择两个点作为簇中心点,标记为红色和黄色,对于第一次聚类结果,我们分别计算所有的点到这两个中心点之间的聚类,我们发现A、B亮点离红色的点距离更近,、C、D、E三点离黄色的点距离更近,所以在第一次聚类过程中,这个簇被定义为:A、B为一个簇,C、D、E为一个簇,接下来,我们将A、B这个簇重新计算它的聚类中心,标记为一个更深颜色的红色的点,C、D、E重新计算他们的簇中心,为一个更深颜色的黄色的点,我们再重新计算这些所有点距离簇中心的距离,接下来我们可以发现,A、B、C可以聚为一个簇,而D、E相对于黄色的簇中心距离更近,所以D、E为一个簇,因此我们再重新计算一下A、B、C这个簇的簇中心和D、E的簇中心,第5张图我们就可以看到簇的组成已经相对稳定了,那么这5个点的聚类结果就是:A、B、C为一个簇,D、E为一个簇,红色和黄色的点分别为这两个簇的簇中心;演变过程如下:
2.K-means的应用
1.数据介绍:
现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主要变量数据,这8个变量分别是:食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、 娱乐教育文化服务、居住以及杂项商品和服务。利用已有数据,对31个省份进行聚类。
2.实验目的:
通过聚类,了解1999年各个省份的消费水平在国内的情况。
3.技术路线:sklearn.cluster.Kmeans
4.数据实例展示:
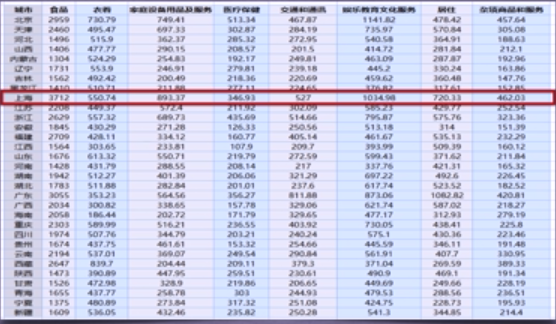
1999年全国31个省份城镇居民家庭平均每人全年消费性支出数据,如下所示:
5.实验过程:
1.使用算法:K-means聚类算法
2.实现过程:
1.建立工程,导入sklearn相关包
import numpy as np
from sklearn.cluster import KMeans
2.加载数据,创建K-means算法实例,并进行训练,获得标签:

注意:调用K-Means方法所需参数:
1.n_clusters:用于指定聚类中心的个数
2.init:初始聚类中心的初始化方法
3.max_iter:最大的迭代次数
4.一般调用时只用给出n_clusters即可,init默认是k-means++,max_iter默认是300。
其它参数:
1.data:加载的数据
2.label:聚类后各数据所属的标签
3.fit_predict():计算簇中心以及为簇分配序号
重点方法解释:
data,cityName = loadData('city.txt') #loadData()函数是我们自己定义的,具体代码为:
def loadData(filePath):
fr = open(filePath,'r+') #r+:读写方式打开一个文本文件
lines = fr.readlines()
retData = []
retCityName = []
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append(float(items[1]))
for i in range(1,len(items)):
return retData,retCityName
注意:loadData()函数中的readlines()方法一次性读取整个文件,类似于.read()
retCityName用于存储城市名称;
retData 用于存储城市的各项消费信息
返回值:返回城市名称以及该城市的各项消费信息
展示的时候:

3.输出标签,查看结果
1.我们将城市按照消费水平n_clusters分为几个类,消费水平相近的城市聚集在一类中。
2.expenses:聚类中心店的数值加和,也就是平均消费水平。
如下展示了:当n_clusters=2时,消费水平的聚类结果,聚成2类,我们可以看到其中一类是:北京、天津、上海、浙江、福建、广东、重庆、西藏为一个消费水平的;

当n_clusters=3或者n_clusters=4的时候的聚类情况如下所示:

从这些结果中我们可以看出,消费水平相近的城市聚集在一个类中,而北京、上海、广东很稳定的一直聚集在了同一个类中!
如下,我们简单谈一下sklearn库中的k-means算法的拓展和改进;
3.拓展 && 改进
计算两条数据相似性时,Sklearn的K-Means默认用的是欧氏距离。虽然还有余弦相似度,马氏距离等多种方法,但sklearn中的k-means算法没有设定计算距离方法的参数。如果大家想要使用自定义计算距离的计算方法,那么我们可以更改k-means的源代码,在这里我们建议使用scipy.spatial.distance.cdist方法。

当设置metric="cosine"的时候,就相当于我们要使用余弦距离了,使用形式:scipy.spatial.distance.cdist(A,B,metric="cosine")

4.无监督学习--K-means聚类的更多相关文章
- 无监督学习——K-均值聚类算法对未标注数据分组
无监督学习 和监督学习不同的是,在无监督学习中数据并没有标签(分类).无监督学习需要通过算法找到这些数据内在的规律,将他们分类.(如下图中的数据,并没有标签,大概可以看出数据集可以分为三类,它就是一个 ...
- K均值聚类
聚类(cluster)与分类的不同之处在于, 分类算法训练过程中样本所属的分类是已知的属监督学习. 而聚类算法不需要带有分类的训练数据,而是根据样本特征的相似性将其分为几类,又称为无监督分类. K均值 ...
- 无监督学习(Unsupervised Learning)
无监督学习(Unsupervised Learning) 聚类无监督学习 特点 只给出了样本, 但是没有提供标签 通过无监督学习算法给出的样本分成几个族(cluster), 分出来的类别不是我们自己规 ...
- 【机器学习基础】无监督学习(1)——PCA
前面对半监督学习部分作了简单的介绍,这里开始了解有关无监督学习的部分,无监督学习内容稍微较多,本节主要介绍无监督学习中的PCA降维的基本原理和实现. PCA 0.无监督学习简介 相较于有监督学习和半监 ...
- AI之强化学习、无监督学习、半监督学习和对抗学习
1.强化学习 @ 目录 1.强化学习 1.1 强化学习原理 1.2 强化学习与监督学习 2.无监督学习 3.半监督学习 4.对抗学习 强化学习(英语:Reinforcement Learning,简称 ...
- 斯坦福机器学习视频笔记 Week8 无监督学习:聚类与数据降维 Clusting & Dimensionality Reduction
监督学习算法需要标记的样本(x,y),但是无监督学习算法只需要input(x). 您将了解聚类 - 用于市场分割,文本摘要,以及许多其他应用程序. Principal Components Analy ...
- 易百教程人工智能python修正-人工智能无监督学习(聚类)
无监督机器学习算法没有任何监督者提供任何指导. 这就是为什么它们与真正的人工智能紧密结合的原因. 在无人监督的学习中,没有正确的答案,也没有监督者指导. 算法需要发现用于学习的有趣数据模式. 什么是聚 ...
- <机器学习>无监督学习算法总结
本文仅对常见的无监督学习算法进行了简单讲述,其他的如自动编码器,受限玻尔兹曼机用于无监督学习,神经网络用于无监督学习等未包括.同时虽然整体上分为了聚类和降维两大类,但实际上这两类并非完全正交,很多地方 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
随机推荐
- python 遍历list并删除部分元素
python 遍历list并删除部分元素https://blog.csdn.net/afgasdg/article/details/82844403有两个list,list_1 为0-9,list_2 ...
- 在RAC执行相关操作发生ora-01031:insufficient privileges解决方法
grid用户下 寻找命令的路径 如which crsctl su - root用户 然后根据找到的路径去执行命令 如 /u01/app/oracle/product/11.2.0/db_1/bin/c ...
- JavaWeb学习总结——文件上传和下载
在Web应用系统开发中,文件上传和下载功能是非常常用的功能,今天来讲一下JavaWeb中的文件上传和下载功能的实现. 对于文件上传,浏览器在上传的过程中是将文件以流的形式提交到服务器端的,如果直接使用 ...
- 【前端技术】web 开发常见问题--GET POST 区别
web 开发常见问题--GET POST 区别 首先,get和post是什么? --两种 HTTP 请求方法:GET 和 POST HTTP Request Methods GET.POST 专业 ...
- Amazon SQS(Simple Queue Service) 简单介绍
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/hongchangfirst/article/details/25877059 SQS即Simple ...
- oracle常用分析函数 over(partition by xxx order by xxx)
--over order by 连续累加的意思,把by后面相同的字段,一个组组累加起来SELECT id_,name_,proc_def_id_, count(*) over(order by nam ...
- Java中的boxing和unboxing(转)
测试代码: System.out.println(0L == 0);//true System.out.println(((Long)0L).equals(0));//false Integer i1 ...
- sap gui 配置
1: sap gui 安全配置 ,在左下角搜索sap gui configuration.
- sap QG3搜索
先创建一个QG3系统,创建一个用户. 1: 进入搜索模板 2: 选择软件组件,点击执行 3: 设置过滤条件. 4: 选择在哪一列 设置过滤条件. 5: 定义搜索值 6: 设置值 可以将搜索的结果删除. ...
- request.getSession(true)和request.getSession(false)的区别
request.getSession(true)和request.getSession(false)的区别 request.getSession(true):若存在会话则返回该会话,否则新建一个会 ...