yarn application ID 增长达到10000后

Job, Task, and Task Attempt IDs
In Hadoop 2, MapReduce job IDs are generated from YARN application IDs that arecreated by the YARN resource manager.
The format of an application ID is composedof the time that the resource manager (not the application) started and an incrementingcounter maintained by the resource manager to uniquely identify the application to that instance of the resource manager.
So the application with this ID:
appllcation_1410450250506_0003
is the third (0003; application IDs are 1 -based) application run by the resource manager,which started at the time represented by the timestamp 1410450250506.
The counter is formatted with leading zeros to make IDs sort nicely —in directory listings, for example.
However, when the counter reaches 10000, it is not reset, resulting in longer application IDs (which don’t sort so well). The corresponding job ID is created simply by replacing the application prefix of an application ID with a job prefix:
job_1410450250506_0003
Tasks belong to a job, and their IDs are formed by replacing the job prefix of a job ID with a task prefix and adding a suffix to identify the task within the job. For example:
task_1410450250506_0003_n_000003
is the fourth (000003; task IDs are 0-based) map (n) task of the job with ID job_1410450250506_0003. The task IDs arc created for a job when it is initialized, so they do not necessarily dictate the order in which the tasks will be executed. Tasks may be executed more than once, due to failure (see MTask FailurcM on page 193) or speculative execution (see speculative Execution" on page 204), so to identify different instances of a task execution, task attempts are given unique IDs. For example:
attenpt_1410450256506_0003_n_000003_0
is the first (0; attempt IDs are O-based) attempt at running task
task_141045O250506_O003_m_000003.
Task attempts arc allocated during the job run as needed, so their ordering represents the order in which they were created to run.
简而言之,就是当yarn application id超过了4位数的范围,也就是达到10000后,yarn直接做增加位数操作,来扩展id空间范围。同时官方承认,这会导致根据id排序结果出现偏差。
2018-01-02,实际截图补充:
按提交时间排序:
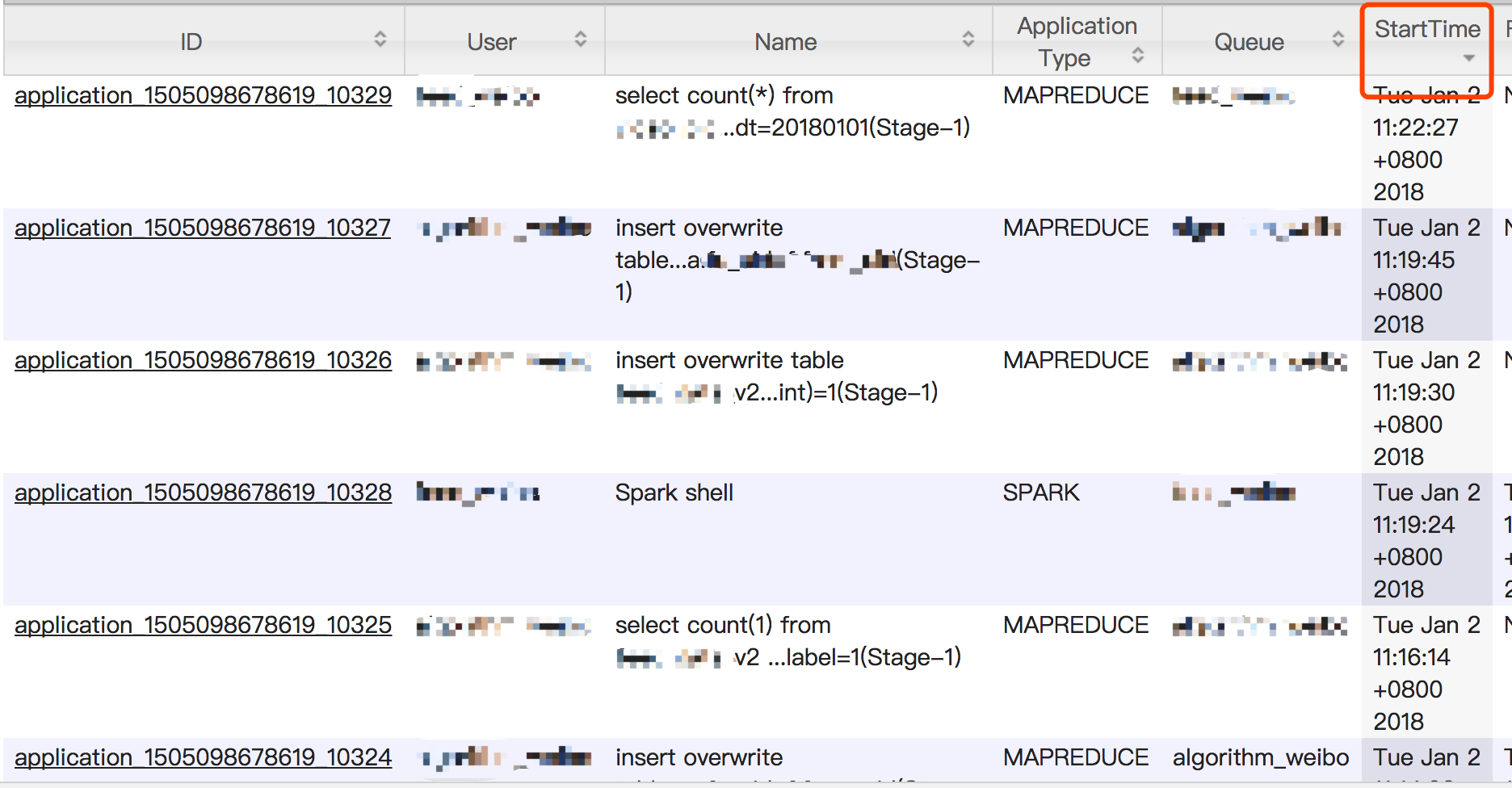
按照id排序:
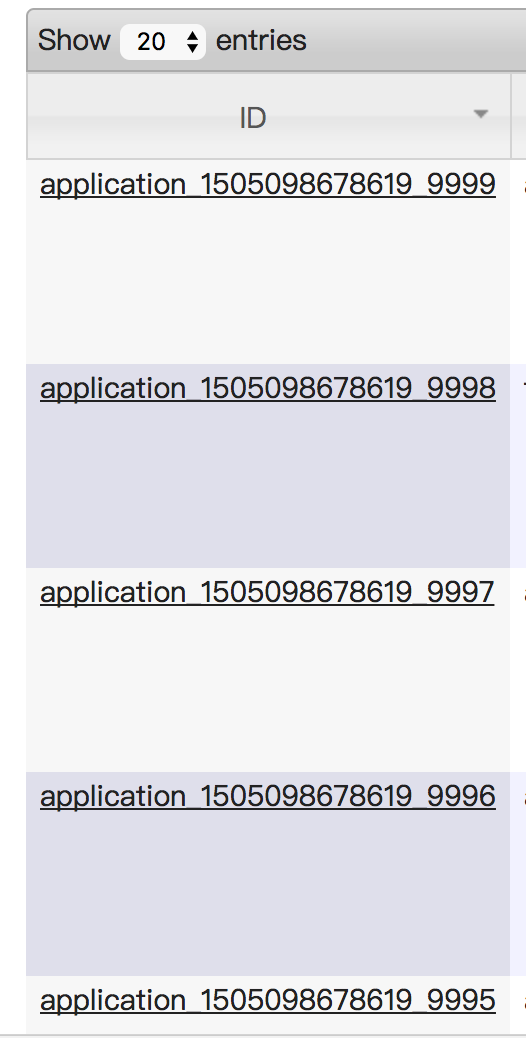
yarn application Id在到达10000后,会通过增加位数来扩展id空间容量,但这会导致页面按照ID进行排序结果出现偏差。
Hadoop: The Definitive Guide: Storage and Analysis at Internet Scale
yarn application ID 增长达到10000后的更多相关文章
- spark-shell启动报错:Yarn application has already ended! It might have been killed or unable to launch application master
spark-shell不支持yarn cluster,以yarn client方式启动 spark-shell --master=yarn --deploy-mode=client 启动日志,错误信息 ...
- yarn application -kill application_id yarn kill 超时任务脚本
需求:kill 掉yarn上超时的任务,实现不同队列不同超时时间的kill机制,并带有任务名的白名单功能 此为python脚本,可配置crontab使用 # _*_ coding=utf-8 _*_ ...
- hadoop job -kill 和 yarn application -kill 区别
hadoop job -kill 调用的是CLI.java里面的job.killJob(); 这里会分几种情况,如果是能查询到状态是RUNNING的话,是直接向AppMaster发送kill请求的.Y ...
- Eclipse插件开发_异常_01_java.lang.RuntimeException: No application id has been found.
一.异常现象 在运行RCP程序时,出现 java.lang.RuntimeException: No application id has been found. at org.eclipse.equ ...
- yarn application命令介绍
yarn application 1.-list 列出所有 application 信息 示例:yarn application -list 2.-appStates <Stat ...
- Hibernate在oracle中ID增长的方式
引用链接:http://blog.csdn.net/w183705952/article/details/7367272 Hibernate在oracle中ID增长的方式 第一种:设置ID的增长策略是 ...
- 【深入浅出 Yarn 架构与实现】3-1 Yarn Application 流程与编写方法
本篇学习 Yarn Application 编写方法,将带你更清楚的了解一个任务是如何提交到 Yarn ,在运行中的交互和任务停止的过程.通过了解整个任务的运行流程,帮你更好的理解 Yarn 运作方式 ...
- eclipse 4 rcp: java.lang.RuntimeException: No application id has been found.
错误详情: java.lang.RuntimeException: No application id has been found. at org.eclipse.equinox.internal. ...
- [JAVA][RCP]Clean project之后报错:java.lang.RuntimeException: No application id has been found.
Clean了一下Project,然后就报了如下错误 !ENTRY com.release.nattable.well_analysis 2 0 2015-11-20 17:04:44.609 !MES ...
随机推荐
- java- WatchService监控
java7中新增WatchService可以监控文件的变动信息(监控到文件是修改,新增.删除等事件:) 其中注册事件是需要的: StandardWatchEventKinds.ENTRY_MODIFY ...
- 系统编码、文件编码与python系统编码
在linux中获取系统编码结果: Windows系统的编码,代码页936表示GBK编码 可以看到linux系统默认使用UTF-8编码,windows默认使用GBK编码.Linux环境下,文件默认使用U ...
- eclipse preference plugin development store and get
eclipse plugin development: E:\workspaces\Eclipse_workspace_rcp\.metadata\.plugins\org.eclipse.pde.c ...
- pycharm修改快捷键
1.keymap 2.找到需要修改的功能 3.鼠标右键选择——选择“add keyboard shortcut” 4.直接按需要设置的快捷键位,如F6 5.确定
- zip压缩解压
zip在linux中使用相对不太频繁,但是在window中使用频繁! zip参数 -q //不显示指令的执行过程,静默执行-r //递归处理文件-T //检测zip文件是否可用-u //更新文件,根据 ...
- [AaronYang]那天有个小孩跟我说Js正则
按照自己的思路学习Node.Js 随心出发.突破正则冷门知识点,巧妙复习正则常用知识点 标签:AaronYang 茗洋 Node.Js 正则 Javascript 本篇博客地址:http://ww ...
- html中<a>标签的种类
在html中a 标签是一个链接标签,然而a 标签也有非常多的种类,在此做一个小结. 一.普通链接 <a href="http://www.baidu.com">百度&l ...
- linux下编译安装pthreads扩展
这里讲的是如何编译安装pthreads,以后编译安装其他PHP扩展可以参考此方法. 下载pthreads源码:http://pecl.php.net/package/pthreads 首先确定安装的p ...
- DataTable转成List集合
项目开发中,经常会获取到DataTable对象,如何把它转化成一个List对象呢?前几天就碰到这个问题,网上搜索整理了一个万能类,用了泛型和反射的知识.共享如下: public class Model ...
- select 语法
select 语句主要语法: SELECT select_list [ INTO new_table ] FROM table_source [ WHERE search_condition ] [ ...