Hadoop HDFS DataNode 目录结构
DataNode 目录结构
和namenode不同的是,datanode的存储目录是初始阶段自动创建的,不需要额外格式化。
1、 在/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current这个目录下查看版本号
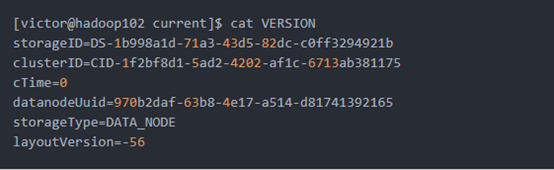
[victor@hadoop102 current]$ cat VERSION
storageID=DS-1b998a1d-71a3-43d5-82dc-c0ff3294921b
clusterID=CID-1f2bf8d1-5ad2-4202-af1c-6713ab381175
cTime=0
datanodeUuid=970b2daf-63b8-4e17-a514-d81741392165
storageType=DATA_NODE
layoutVersion=-56
2、具体解释
(1)storageID:存储id号
(2)clusterID集群id,全局唯一
(3)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(4)datanodeUuid:datanode的唯一识别码
(5)storageType:存储类型
(6)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
3、在/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-97847618-192.168.10.102-1493726072779/current这个目录下查看该数据块的版本号
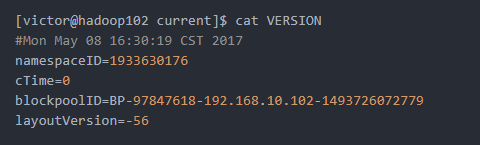
[victor@hadoop102 current]$ cat VERSION
#Mon May 08 16:30:19 CST 2017
namespaceID=1933630176
cTime=0
blockpoolID=BP-97847618-192.168.10.102-1493726072779
layoutVersion=-56
4、具体解释
(1)namespaceID:是datanode首次访问namenode的时候从namenode处获取的storageID对每个datanode来说是唯一的(但对于单个datanode中所有存储目录来说则是相同的),namenode可用这个属性来区分不同datanode。
(2)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(3)blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
(4)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
Hadoop HDFS DataNode 目录结构的更多相关文章
- Hadoop HDFS元数据目录分析
元数据目录分析 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘: $HADOOP_HOME/bin/hdfs namenode -format 格式化完成之后 ...
- Hadoop HDFS本地存储目录结构解析
转自:https://blog.csdn.net/superman_xxx/article/details/51689398 HDFS metadata以树状结构存储整个HDFS上的文件和目录,以及相 ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
- hadoop安装包的目录结构
初次接触Hadoop,了解了Hadoop安装包的目录结构,和大家分享下: bin:Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理 ...
- hadoop fs -put上传文件失败,WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: master:8020
hadoop fs -put上传文件失败 报错信息:(test文件夹是已经成功建好的) [root@master ~]# hadoop fs -put test1.txt /test // :: WA ...
- ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Incompatible namespaceIDs
用三台centos操作系统的机器搭建了一个hadoop的分布式集群.启动服务后失败,查看datanode的日志,提示错误:ERROR org.apache.hadoop.hdfs.server.dat ...
- hadoop的目录结构介绍
hadoop的目录结构介绍 解压缩hadoop 利用tar –zxvf把hadoop的jar包放到指定的目录下. tar -zxvf /home/software/aa.tar.gz -C /home ...
- hadoop目录结构
Hadoop目录结构 重要目录结构: bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本 etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件 lib目录:存放H ...
- Hadoop1.x目录结构及Eclipse导入Hadoop源码项目
这是解压hadoop后,hadoop-1.2.1目录 各目录结构及说明: Eclipse导入Hadoop源码项目: 注意:如果没有ant的包可以去网上下,不是hadoop里面的. 然后如果通过以上还报 ...
随机推荐
- robotframework·RIDE基础
date:2018520 day09 一.学习环境 1.安装python27 2.安装robotframework(cmd→[pip install robotframework]) 3.安装WxPy ...
- Semaphore计数信号量
ExecutorService exec = Executors.newCachedThreadPool(); final Semaphore semp = new Semaphore(5); for ...
- Spring Boot 揭秘与实战(八) 发布与部署 - 开发热部署
文章目录 1. spring-boot-devtools 实现热部署 2. Spring Loaded 实现热部署 3. 模板文件热部署 4. 源代码 Spring Boot 支持页面与类文件的热部署 ...
- Oracle表的查询(一)
表查询关键字.字段.表名不加引号时不区分大小写引号定义的内容区分大小写运算中有null值时,结果为null*nvl(字段,赋值):如果字段值为null,则取后面一个值*like 关键字:%表示若干个字 ...
- Micro- and macro-averages
https://datascience.stackexchange.com/questions/15989/micro-average-vs-macro-average-performance-in- ...
- Windows编程___创建窗口
创建Windows窗口不难,可以简要的概括为: 1,# 注册一个窗口类 填充WNDCLASS结构 书写窗口消息处理函数WinProc 2,# 创建一个窗口 填写基本的窗口信息 3,# 显示窗口 4,# ...
- PowerDesigner15 增加Domain域
第一步: 第二步: 点击此按钮,在弹出框中对Domain域打钩即可
- Prime Test(POJ 1811)
素数判定的模板题,运用米勒-罗宾素数判定,然后用Pollard_Rho法求出质因数.使用相应的模板即可,不过注意存储质因子的数组需要使用vector,并且使用long long类型存储,不然存储不下, ...
- ODOO区分测试库和正式库的简单方法
ODOO区分测试库和正式库的简单方法.1. 打开 开发者模式,右上角能显示数据库名称,缺点是,太耗系统资源了,数据多的时候就明显感觉慢了.2. 安装社区的显示测试帐套的模块, 若是正式环境还是尽量少装 ...
- C++ 作业 (循环链表构建队列)
/* author screen name Andromeda_Galaxy; chinese name 杨子俊 */ #include<bits/stdc++.h> using name ...