【转】机器学习笔记之(3)——Logistic回归(逻辑斯蒂回归)
原文链接:https://blog.csdn.net/gwplovekimi/article/details/80288964
本博文为逻辑斯特回归的学习笔记。由于仅仅是学习笔记,水平有限,还望广大读者朋友多多赐教。
假设现在有一些数据点,我们用一条直线对这些点进行拟合(该直线称为最佳拟合直线),这个拟合的过程就称为回归。
利用Logistic(逻辑斯蒂)回归是一个分类模型而不回归模型。其进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。这里的“回归”一词源于最佳拟合,表示要找到最佳拟合参数。而最佳拟合参数就是在训练分类器时,通过最优化算法获得。
首先,逻辑斯蒂回归是一种线性分类器,针对的是线性可分问题(接下来会有博客专门介绍一系列线性分类器)。
几率比:指特定事件发生的几率。如下式所示。其中p为事件1发生的概率。
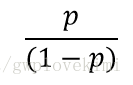
进一步地,我们可以logit函数,为几率比的对数函数
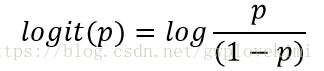
logit函数的输入值范围介于区间[0,1],它能将输入转换到整个实数范围内,由此可以将对数几率记为输入特征值的线性表达式:
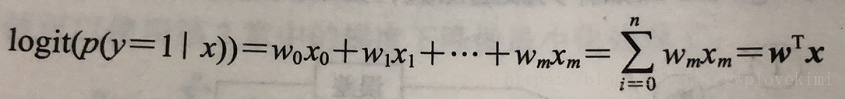
此处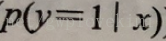
而对于某一样本属于特定类别的概率,为logit函数的反函数,称为logistic函数,由于它的图像呈S形,有时也称为sigmoid函数:
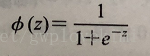
其中,z为净输入,为样本特征与权重的线性组合:

下面用Python绘制一下sigmoid图
- import matplotlib.pyplot as plt
- import numpy as np
- def sigmoid(z):
- return 1.0/(1.0+np.exp(-z))
- z=np.arange(-6,6,0.05)
- plt.plot(z,sigmoid(z))
- plt.axvline(0.0,color='k')
- plt.axhline(y=0.0,ls='dotted',color='k')
- plt.axhline(y=1.0,ls='dotted',color='k')
- plt.axhline(y=0.5,ls='dotted',color='k')
- plt.yticks([0.0,0.5,1.0])
- plt.ylim(-0.1,1.1)
- plt.xlabel('z')
- plt.ylabel('$\phi (z)$')
- plt.show()
结果图如下:

sigmoid函数以实数值作为输入,并将其映射到[0,1]区间,拐点在0.5处。
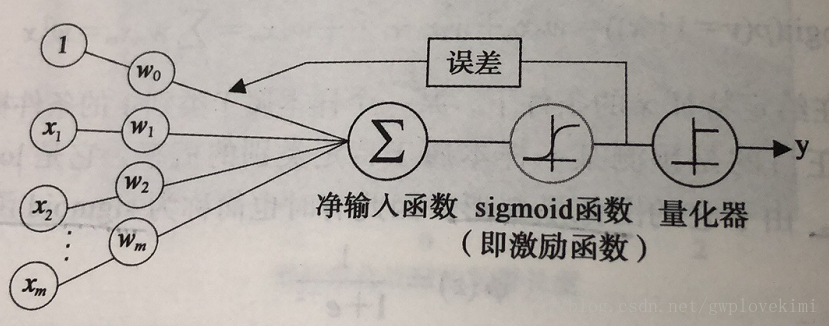
为了实现逻辑斯蒂回归分类器,在每个特征上都乘以一个回归系数,然后把所有的结果值相加,再代入sigmoid函数中(激励函数),进而可以得到一个范围为0~1之间的数值(可以看成概率)。量化器则是设置一个阈值,大于阈值则归类为1,小于则归类为0。其模型如下图所示:
那么现在问题来了,这组权重应该等于多少,就是说最佳的回归系数是多少。通过最小化代价函数获得。
代价函数:定义为通过模型得到的输出与实际类标之间的误差平方和(sum of square error,SSE):

在自适应神经网络中通过最小化代价函数,就可以获得分类模型的权重w。后面的部分直接给出书上的照片吧(这个我没看太懂。。。。也没做详细的理论推导)



sigmoid函数的输入记为z,由下面公式可得:

下面介绍一下梯度上升算法。梯度上升发的基本思想是:要找到某个函数的最大值,最好的方法是沿着该函数的梯度方向寻找。函数f(x,y)的表示如下:

这个梯度意味着要沿x的方向移动


由图可得,梯度算子总是指向函数值增长最快的方向。而对于移动的步长,记为
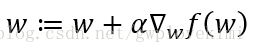
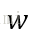

在scikit-learn中已经有现成的经过高度优化的逻辑斯蒂算法,所以可以直接使用该函数
给出python代码如下:
- #逻辑斯蒂分类算法
- import numpy as np
- ###############################################################################
- #画图的函数
- from matplotlib.colors import ListedColormap
- import matplotlib.pyplot as plt
- def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
- # setup marker generator and color map
- markers = ('s', 'x', 'o', '^', 'v')
- colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
- cmap = ListedColormap(colors[:len(np.unique(y))])#通过ListedColormap来定义一些颜色和标记号,并通过颜色列表生成了颜色示例图
- # plot the decision surface
- #对两个特征的最大值最小值做了限定(使用两个特征来训练感知器)
- x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- #利用meshgrid函数,将最大值、最小值向量生成二维数组xx1和xx2
- xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
- #创建一个与数据训练集中列数相同的矩阵,以预测多维数组中所有对应点的类标z
- Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
- Z = Z.reshape(xx1.shape)#将z变换为与xx1和xx2相同维度
- #使用contourf函数,对于网格数组中每个预测的类以不同的颜色绘制出预测得到的决策区域
- plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
- plt.xlim(xx1.min(), xx1.max())
- plt.ylim(xx2.min(), xx2.max())
- for idx, cl in enumerate(np.unique(y)):
- plt.scatter(x=X[y == cl, 0],
- y=X[y == cl, 1],
- alpha=0.8,
- c=colors[idx],
- marker=markers[idx],
- label=cl,
- edgecolor='black')
- # highlight test samples
- if test_idx:
- # plot all samples
- X_test, y_test = X[test_idx, :], y[test_idx]
- plt.scatter(X_test[:, 0],
- X_test[:, 1],
- c='',
- edgecolor='black',
- alpha=1.0,
- linewidth=1,
- marker='o',
- s=100,
- label='test set')
- ###############################################################################
- #训练集与测试集的获取,采用鸢尾花数据集
- from sklearn import datasets
- iris=datasets.load_iris()
- x=iris.data[:,[2,3]]
- y=iris.target
- #对数据集进行划分
- from sklearn.cross_validation import train_test_split
- #采用scikit-learn中的cross_validation模块中的train_test_split()函数,随机将iris数据特征矩阵x与类标向量y按照3:7划分为测试数据集和训练数据集
- x_train,x_test, y_train, y_test =train_test_split(x,y,test_size=0.3, random_state=0)
- #为了优化性能,对特征进行标准化处理
- from sklearn.preprocessing import StandardScaler
- sc=StandardScaler()
- sc.fit(x_train)#通过fit方法,可以计算训练数据中每个特征的样本均值和方差
- x_train_std=sc.transform(x_train)#通过调用transform方法,可以使用前面获得的样本均值和方差来对数据做标准化处理
- x_test_std=sc.transform(x_test)
- ###############################################################################
- from sklearn.linear_model import LogisticRegression
- lr=LogisticRegression(C=1000.0,random_state=0)
- lr.fit(x_train_std,y_train)
- print("Training Score:%f"%lr.score(x_train_std,y_train))#返回在(X_train,y_train)上的准确率
- print("Testing Score:%f"%lr.score(x_test_std,y_test))#返回在(X_test,y_test)上的准确率
- x_combined_std = np.vstack((x_train_std, x_test_std))#将数组垂直排列成多个子数组的列表。
- y_combined = np.hstack((y_train, y_test))# 按水平顺序(列)顺序堆栈数组。
- plot_decision_regions(X=x_combined_std, y=y_combined, classifier=lr, test_idx=range(105, 150))
- plt.xlabel('petal length [standardized]')
- plt.ylabel('petal width [standardized]')
- plt.legend(loc='upper left')
- plt.show()
结果如下图所示

进一步地,可以通过下图所示,来预测样本属于某一类别的概率:

其实,直接用库的函数真的是非常的简单,所以说机器学习是每个人都可以用的。但是要完全搞透、搞明白,就有需要有比较扎实的数学功底,本人的数学功底暂时有待提高,所以在博客里面,主要还是偏向于函数的介绍与应用。
下面通过以下操作来获得权重向量:
程序里面的C=1000.0是正则化系数的倒数,通过减少C值,可以增加正则化项的强度(C为正则化系数的倒数)。
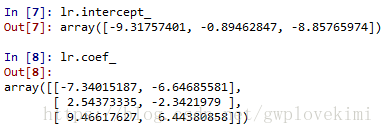
下面先通过程序来衡量C变化的影响:
- #逻辑斯蒂分类算法
- import numpy as np
- ###############################################################################
- #训练集与测试集的获取,采用鸢尾花数据集
- from sklearn import datasets
- iris=datasets.load_iris()
- x=iris.data[:,[2,3]]
- y=iris.target
- #对数据集进行划分
- from sklearn.cross_validation import train_test_split
- #采用scikit-learn中的cross_validation模块中的train_test_split()函数,随机将iris数据特征矩阵x与类标向量y按照3:7划分为测试数据集和训练数据集
- x_train,x_test, y_train, y_test =train_test_split(x,y,test_size=0.3, random_state=0)
- #为了优化性能,对特征进行标准化处理
- from sklearn.preprocessing import StandardScaler
- sc=StandardScaler()
- sc.fit(x_train)#通过fit方法,可以计算训练数据中每个特征的样本均值和方差
- x_train_std=sc.transform(x_train)#通过调用transform方法,可以使用前面获得的样本均值和方差来对数据做标准化处理
- x_test_std=sc.transform(x_test)
- ###############################################################################
- from sklearn.linear_model import LogisticRegression
- Cs=np.logspace(-2,4,num=100)
- scores=[]
- for C in Cs:
- lr = LogisticRegression(C=C)
- lr.fit(x_train_std, y_train)
- scores.append(lr.score(x_test_std, y_test))
- ###############################################################################
- ## 绘图
- import matplotlib.pyplot as plt
- fig=plt.figure()
- ax=fig.add_subplot(1,1,1)
- ax.plot(Cs,scores)
- ax.set_xlabel(r"C")
- ax.set_ylabel(r"score")
- ax.set_xscale('log')
- ax.set_title("LogisticRegression")
- plt.show()
结果如下图所示:
随着C的增大(即正则化项的减小),预测的准确率上升。(上图为正则化强度减少对于测试集的影响)
减少正则化参数的倒数C的值,相当于增加正则化的强度,正则化可以避免过拟合,但同时正则化强度太大也会使得预测性能降低。
下面给出正则化强度减少对于训练集的影响:
- #逻辑斯蒂分类算法
- import numpy as np
- ###############################################################################
- #训练集与测试集的获取,采用鸢尾花数据集
- from sklearn import datasets
- iris=datasets.load_iris()
- x=iris.data[:,[2,3]]
- y=iris.target
- #对数据集进行划分
- from sklearn.cross_validation import train_test_split
- #采用scikit-learn中的cross_validation模块中的train_test_split()函数,随机将iris数据特征矩阵x与类标向量y按照3:7划分为测试数据集和训练数据集
- x_train,x_test, y_train, y_test =train_test_split(x,y,test_size=0.3, random_state=0)
- #为了优化性能,对特征进行标准化处理
- from sklearn.preprocessing import StandardScaler
- sc=StandardScaler()
- sc.fit(x_train)#通过fit方法,可以计算训练数据中每个特征的样本均值和方差
- x_train_std=sc.transform(x_train)#通过调用transform方法,可以使用前面获得的样本均值和方差来对数据做标准化处理
- x_test_std=sc.transform(x_test)
- ###############################################################################
- from sklearn.linear_model import LogisticRegression
- Cs=np.logspace(-2,4,num=100)
- scores=[]
- for C in Cs:
- lr = LogisticRegression(C=C)
- lr.fit(x_train_std, y_train)
- scores.append(lr.score(x_train_std, y_train))
- ###############################################################################
- ## 绘图
- import matplotlib.pyplot as plt
- fig=plt.figure()
- ax=fig.add_subplot(1,1,1)
- ax.plot(Cs,scores)
- ax.set_xlabel(r"C")
- ax.set_ylabel(r"score")
- ax.set_xscale('log')
- ax.set_title("LogisticRegression")
- plt.show()
结果如图所示:

正则化增强,会使得训练误差增大,而避免了过拟合,会使得测试误差减少。但是上面看来,正则化增强均会使得测试和训练的 误差增大。可能跟数据本身有关。就是本来没有过拟合,这里加了正则化,就会导致效果变差。这也正是“正则化使得对训练数据的预测性能降低,对测试数据的预测性能先升后降”
通过正则化来解决过拟合问题
所谓的过拟合是指——模型过于复杂,所以虽然模型在训练数据集上表现良好,但是用于未知数据(测试数据)时性能不佳。若一个模型出现了过拟合的问题,就是说这模型有高方差,可能是因为使用了相关数据中过多的参数,从而使得模型变得过于复杂。
而欠拟合是指——模型过于简单,无法发现训练数据集中隐含的模式,这也使得训练好的模型用于未知数据(测试数据)时性能不佳。
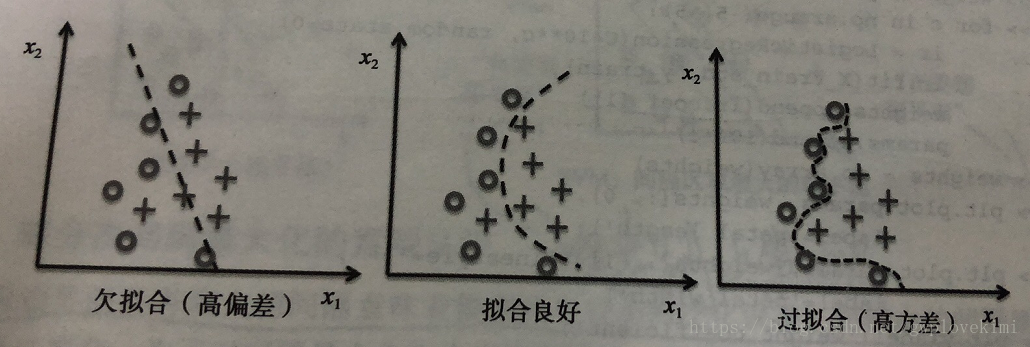
机器学习中,方差与偏差的区别
首先,欠拟合的模型,就是因为具有高的偏差。而过拟合的模型则是因为具有高的方差。
- 方差——当我们多次重复训练一个模型,如果使用训练数据集中的不同子集,那么方差可以用来衡量模型对特定样本实例预测的一致性(或者说变化)。可以说模型对训练数据中的随机性是敏感的。
- 偏差——当我们在不同的训练数据集上多次重建模型时,偏差可以从总体上衡量预测值与实际值之间的差异;偏差不是由系统的随机性导致的,它衡量的是系统的误差。
所以。高方差是指,对于不同样本的预测变化很大,那么就是过拟合。高偏差,是指,对样本的预测与实际偏离很大,那么就是欠拟合。
而偏差-方差权衡就是通过正则化调整模型的复杂度(模型太复杂就会导致高方差,过拟合;太简单就会导致高偏差,欠拟合)。
正则化是引入额外的信息(偏差)来对极端参数权重作出严惩。常用的正则化为L2正则化:
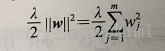
只需要在逻辑斯蒂回归的代价函数中加入正则化项即可:

除此以外,之所以上面程序中要对特征做标准化处理,就是为了使得正则化可以起作用。要确保所有特征的衡量标准统一。
好~逻辑斯蒂回归的学习笔记告一段落。后面有新的体会与感悟会及时更新本博客
参考资料如下:
- 《机器学习实战》
- 《Python机器学习》
- 《机器学习Python实践》
- 《Python机器学习算法》
- 《Python大战机器学习》
- 《Python与机器学习实战》
【转】机器学习笔记之(3)——Logistic回归(逻辑斯蒂回归)的更多相关文章
- 机器学习之LinearRegression与Logistic Regression逻辑斯蒂回归(三)
一 评价尺度 sklearn包含四种评价尺度 1 均方差(mean-squared-error) 2 平均绝对值误差(mean_absolute_error) 3 可释方差得分(explained_v ...
- [置顶] 局部加权回归、最小二乘的概率解释、逻辑斯蒂回归、感知器算法——斯坦福ML公开课笔记3
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9113681 最近在看Ng的机器学习公开课,Ng的讲法循循善诱,感觉提高了不少 ...
- spark机器学习从0到1逻辑斯蒂回归之(四)
逻辑斯蒂回归 一.概念 逻辑斯蒂回归(logistic regression)是统计学习中的经典分类方法,属于对数线性模型.logistic回归的因变量可以是二分类的,也可以是多分类的.logis ...
- python机器学习实现逻辑斯蒂回归
逻辑斯蒂回归 关注公众号"轻松学编程"了解更多. [关键词]Logistics函数,最大似然估计,梯度下降法 1.Logistics回归的原理 利用Logistics回归进行分类的 ...
- 【分类器】感知机+线性回归+逻辑斯蒂回归+softmax回归
一.感知机 详细参考:https://blog.csdn.net/wodeai1235/article/details/54755735 1.模型和图像: 2.数学定义推导和优化: 3.流程 ...
- 【项目实战】pytorch实现逻辑斯蒂回归
视频指导:https://www.bilibili.com/video/BV1Y7411d7Ys?p=6 一些数据集 在pytorch框架下,里面面有配套的数据集,pytorch里面有一个torchv ...
- 逻辑斯蒂回归(Logistic Regression)
逻辑回归名字比较古怪,看上去是回归,却是一个简单的二分类模型. 逻辑回归的模型是如下形式: 其中x是features,θ是feature的权重,σ是sigmoid函数.将θ0视为θ0*x0(x0取值为 ...
- deep learning (六)logistic(逻辑斯蒂)回归中L2范数的应用
zaish上一节讲了线性回归中L2范数的应用,这里继续logistic回归L2范数的应用. 先说一下问题:有一堆二维数据点,这些点的标记有的是1,有的是0.我们的任务就是制作一个分界面区分出来这些点. ...
- 逻辑斯蒂回归VS决策树VS随机森林
LR 与SVM 不同 1.logistic regression适合需要得到一个分类概率的场景,SVM则没有分类概率 2.LR其实同样可以使用kernel,但是LR没有support vector在计 ...
随机推荐
- python-面向对象-07_继承
继承 目标 单继承 多继承 面向对象三大特性 封装 根据 职责 将 属性 和 方法 封装 到一个抽象的 类 中 继承 实现代码的重用,相同的代码不需要重复的编写 多态 不同的对象调用相同的方法,产生不 ...
- XtraBackup之踩过的坑
xtrabackup相信目前使用已经非常广泛了,备份innodb表的首选工具,但是其中还是有点小坑,虽然发生的概率不大,但是我还是踩坑了.关于xtrabackup的详细参考请查阅官方文档http:// ...
- php魔术变量和13个PHP魔术函数
PHP魔术变量确切地说是PHP魔术常量,不过很多常量都是由不同的扩展库定义的,只有在加载了这些扩展库时才会出现,或者动态加载后,或者在编译时已经包括进去了.比如说__LINE__放在不同的地方是显示不 ...
- 同一局域网运行两套LVS
两套LVS的ID必须不一致 ,原文: http://blog.chinaunix.net/uid-29578485-id-5671910.html 在LVS服务器中修改配置文件 vi /etc/ke ...
- mysql跨库复制: replicate_wild_do_table和replicate-wild-ignore-table
使用replicate_do_db和replicate_ignore_db时有一个隐患,跨库更新时会出错. 如设置 replicate_do_db=testuse mysql;update test. ...
- shell脚本编写实例
实际案例 1.判断接收参数个数大于1 [ $# -lt 1 ] && echo "至少需要一个参数" && { echo "我要退出了.. ...
- TCP接收缓存大小的手动调整
给出了几个可调节的参数,它们可以帮助您提高 Linux TCP/IP 栈的性能. 表 1. TCP/IP 栈性能使用的可调节内核参数 可调节的参数 默认值 选项说明 /proc/sys/net/cor ...
- axios的使用
一.首先要安装axios npm install axios 使用: -先在main中配置: import axios from 'axios' //要把axios放进一个全局变量中 //把axios ...
- crontab 详解
1.crontab文件格式 {minute} {hour} {day-of-month} {month} {day-of-week} {full-path-to-shell-script} ● mi ...
- [LeetCode] 130. Surrounded Regions_Medium tag: DFS/BFS
Given a 2D board containing 'X' and 'O' (the letter O), capture all regions surrounded by 'X'. A reg ...