Python5 - 字符编码
Python 字符编码
参考详细文章: py编码终极版
http://www.diveintopython3.net/strings.html
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), 所以 utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
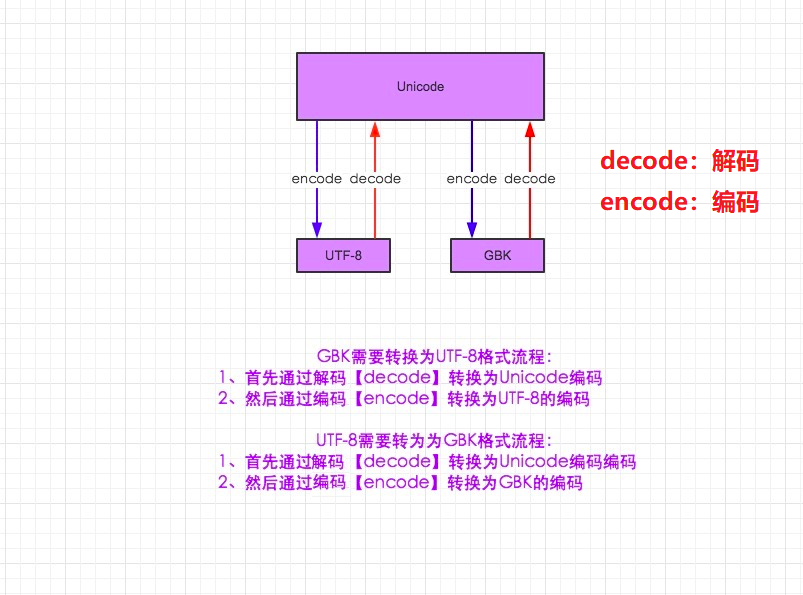
Python3编码实例1:
gbk向下兼容gb18030,gb18030向下兼容gb2312,所以gbk和gb2312的编码是相同的,前提是此中文在gbk和gb2312中都存在
import sys
print(sys.getdefaultencoding()) #python默认编码格式是utf-8
s = "世界你好" #python3所有数据类型都是unicode
# print(type(s))
s_utf8 = s.encode("utf-8") #因为默认Unicode,所以直接编码为utf-8
print("utf-8:", s_utf8) #python3中编码之后用bytes类型输出
s_gb2312 = s_utf8.decode("utf-8").encode("gb2312") #先从utf-8解码为Unicode,再编码为gb2312
print("gb2312:", s_gb2312)
s_gbk = s_gb2312.decode("gb2312").encode("gbk") #gb2312 转 gbk
print("gbk", s_gbk)
s1_gbk = s_utf8.decode("utf-8").encode("gbk") #utf-8 转 gbk
print("gbk", s1_gbk)
s_unicode = s_gbk.decode("gbk") #gbk 解码为Unicode
print("unicode:", s_unicode)
s1_utf8 = s_unicode.encode("utf-8") # unicode 编码为 utf-8
print("utf-8:", s1_utf8)
输出:
utf-8
utf-8: b'\xe4\xb8\x96\xe7\x95\x8c\xe4\xbd\xa0\xe5\xa5\xbd'
gb2312: b'\xca\xc0\xbd\xe7\xc4\xe3\xba\xc3'
gbk b'\xca\xc0\xbd\xe7\xc4\xe3\xba\xc3'
gbk b'\xca\xc0\xbd\xe7\xc4\xe3\xba\xc3'
unicode: 世界你好
utf-8: b'\xe4\xb8\x96\xe7\x95\x8c\xe4\xbd\xa0\xe5\xa5\xbd'
实例1输出
Python3编码实例2:

import sys
print(sys.getdefaultencoding()) #python默认编码格式是utf-8
s = "世界你好" #python3字符串的默认编码是unicode
print(s.encode("gbk"))
print(s.encode("utf-8"))
print(s.encode("utf-8").decode("utf-8").encode("gb2312" ))
上图代码
字符编码的历史
ASCII码
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
中文编码
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
gbk向下兼容gb18030,gb18030向下兼容gb2312,所以gbk和gb2312的编码是相同的,前提是此中文在gbk和gb2312中都存在
万国码
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
#!/usr/bin/env python print "你好,世界
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python
# -*- coding: utf-8 -*- print "你好,世界"
Python5 - 字符编码的更多相关文章
- Python遇到字符编码出问题的一个相对万能的办法
在使用Python做爬虫的过程中,经常遇到字符编码出问题的情况. UnicodeEncodeError: 'ascii' codec can't encode character u'\u6211' ...
- python学习笔记(基础一:'hello world'、变量、字符编码)
第一个python程序: Hello World程序 windows命令行中输入:python,进入python交互器,也可以称为解释器. print("Hello World!" ...
- Python学习Day2笔记(字符编码和函数)
1.字符编码 #ASCII码里只能存英文和特殊字符 不能存中文 存英文占1个字节 8位#中文编码为GBK 操作系统编码也为GBK#为了统一存储中文和英文和其他语言文字出现了万国码Unicode 所有一 ...
- mysql 5.5 修改字符编码
修改/etc/mysql/my.cnf 配置文件: 最后重启mysql 服务,再查看: 编码已经改好了,可以支持中文字符编码了.
- mysql命令行修改字符编码
1.修改数据库字符编码 mysql> alter database mydb character set utf8 ; 2.创建数据库时,指定数据库的字符编码 mysql> create ...
- 关于Unicode,字符集,字符编码,每个程序员都应该知道的事
关于Unicode,字符集,字符编码,每个程序员都应该知道的事 作者:Jack47 李笑来的文章如何判断一个人是否聪明?中提到: 必要.清晰.且准确的概念,是一切思考的基石.所谓思考,很大程度上,就是 ...
- java中文乱码解决之道(二)-----字符编码详解:基础知识 + ASCII + GB**
在上篇博文(java中文乱码解决之道(一)-----认识字符集)中,LZ简单介绍了主流的字符编码,对各种编码都是点到为止,以下LZ将详细阐述字符集.字符编码等基础知识和ASCII.GB的详情. 一.基 ...
- ASP.NET 字符编码的那些事
ASP.NET 中的字符编码问题,一般会有两个场景: HTML 编码:一般是动态显示 HTML 字符或标签,写法是:HttpUtility.HtmlDecode(htmlString) 或 Html. ...
- 【字符编码】Java字符编码详细解答及问题探讨
一.前言 继上一篇写完字节编码内容后,现在分析在Java中各字符编码的问题,并且由这个问题,也引出了一个更有意思的问题,笔者也还没有找到这个问题的答案.也希望各位园友指点指点. 二.Java字符编码 ...
随机推荐
- SQL Server 备份还原
SQL Server支持三种备份方式 完全备份: 差异备份 事务日志备份 一般备份方式为,完全备份/每周,差异备份/每天,事务日志备份/按分钟计,这样可确保备份的高效性和可恢复性. 1. 完全备份 备 ...
- 一步步使用Code::Blocks进行设置断点调试程序
一.调试之前要做的工作 首先,我们要确保Code::Blocks的配置正确,调试工作才能进行得更顺利 为此,我们需要生成调试符号.调试符号可以让调试器知道代码的哪一行正在执行,这样你就可以知道程序运行 ...
- Your Database is downloaded and backed up on....(腾讯云的mysql被攻击)
今天发现自己的服务器被黑客攻击,自己的mysql服务器的库被删掉,并且新创了一个warning库,只有一个readme表.不知道原因,也许是自己再github上的项目暴漏了自己的密码,还要0.6比特币 ...
- CodeForces Contest #1137: Round #545 (Div. 1)
比赛传送门:CF #1137. 比赛记录:点我. 每次都自闭的 div1 啊,什么时候才能上 IM 呢. [A]Skyscrapers 题意简述: 有一个 \(n\times m\) 的矩阵 \(a_ ...
- JavaScript内置对象——Math对象
这几天在刷leetcode的时候用到了一些Math对象的知识,故作一下总结~ JavaScript中的Math对象也是一个常见的内置对象,然而与String等其它常见对象不同,Math对象没有构造函数 ...
- 嵌入式系统C编程之错误处理
前言 本文主要总结嵌入式系统C语言编程中,主要的错误处理方式.文中涉及的代码运行环境如下: 一 错误概念 1.1 错误分类 从严重性而言,程序错误可分为致命性和非致命性两类.对于致命性错误,无法执行 ...
- 用rand()和srand()产生伪随机数的方法总结 【转】
转自:http://blog.chinaunix.net/uid-26722078-id-3754502.html 标准库(被包含于中)提供两个帮助生成伪随机数的函数: 函数一:int rand(vo ...
- eclipse自定义工具栏
设置:1.Window2.Customize Perspective说明:Tool Bar Visibility定义菜单栏,Shortcuts定义右键new菜单
- 量化投资与Python之NumPy
数组计算 NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础.NumPy的主要功能:ndarray,一个多维数组结构,高效且节省空间无需循环对整组数据进行快速运算的 ...
- 集成Struts2+Spring+Hibernate_两种方案
集成Struts2+Spring+Hibernate 第一种方案:让Spring创建Struts2的Action,不让Spring完全管理Struts2的Action Struts2 Act ...