【转载】Hadoop mapreduce 实现原理
1. 如何用通俗的方法解释MapReduce
MapReduce是Google开源的三大技术之一,是对海量数据进行“分而治之”计算框架。为了简单的理解并讲述给客户理解。我们举下面的例子来说明.
首先,面对一堆杂乱的东西,有若干个汉堡、若干个冰淇淋、若干个可乐。如果级别都是上万数量的情况下,有没有方法把他们较快的分析出来?

第一步,调度员简单的将这一堆东西分解成若干堆。

第二步,调度员为每堆物品分配一个分拣员,注意只分拣不计数,分拣员对应MAPReduce中的Map角色。分拣员干的事情,就是将物品按类别分拣,比如分拣后的每一堆的状态应该是如下图所示。分拣员所做的也分成简单,从自己面前这一堆物品中拿一个,看是面包的话,就扔面包那。是可乐就扔可乐那。

第三步,调度员为每类物品分配一个计数员(Reducer),把所有该类型的物品都发给他计数。比如所有的面包类别都分给第一个计数员来负责计数。计数员统计出每个类别的数目,再告诉调度员。

总结:Mapper用来分类,Reduce则用来对同类型的东西做进一步处理。对于互联网的应用场景,比如分析一个网页中出现的词汇最多的单词是什么。Mapper用来将网页中的文字段落分解成一个个单词。相同的单词会被送给同一个Reducer。Reducer会计算出该单词出现了多少次。最后按照各单词出现的次数得出结论。
2. 一个文本文件的处理过程
1)对应这样一个源文本文件

2)首先由调度员通过job.setInputFormatClass(TextInputFormat.class),知道应该转换成偏移量加文本方式的键-值对;再根据当前机器个数,文件大小确定应该分解成几个待处理的片段,比如说分解成两个片段,对应两个Map程序。

3)第一个Map程序每次被调用,接受到的入参(key,value)是

Map程序的输出是
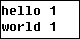
4)第二个Map程序接受的输入将是

第二个Map的输出将是

5)Map程序的输出,会被重新组合,同一个Key的内容,会被分配到同一个Reduce上。
比如上面三个单词,会被分到三个Reducer上
6)第一个Reducer接收到,如下图,注意是两个1,来自两个Map的结果

第一个Reducer的输出会是如下图,意味着hello这个单词出现了两次

7)第二个Reducer接收到

第二个Reducer输出会是

8)第三个Reducer接收到

第三个Reducer输出是

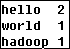
9)最后将三个Reducer进行合并,得到的结果就是
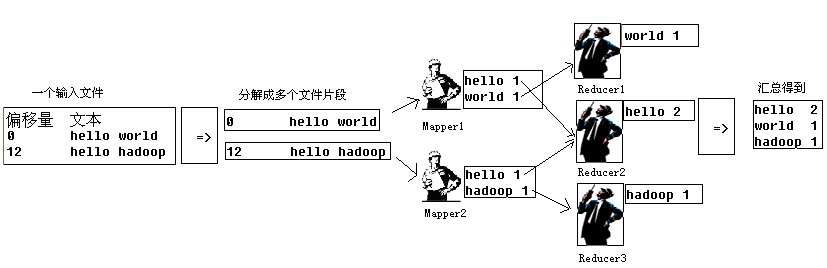
10)汇总流程描述如图所示
转载自
Hadoop的MapReduce实现原理解释
如侵删
【转载】Hadoop mapreduce 实现原理的更多相关文章
- [转载] Hadoop MapReduce
转载自http://blog.csdn.net/yfkiss/article/details/6387613和http://blog.csdn.net/yfkiss/article/details/6 ...
- Hadoop MapReduce工作原理
在学习Hadoop,慢慢的从使用到原理,逐层的深入吧 第一部分:MapReduce工作原理 MapReduce 角色 •Client :作业提交发起者. •JobTracker: 初始化作业,分配 ...
- 一图看懂hadoop MapReduce工作原理
MapReduce执行流程及单词统计WordCount示例
- [转载] MapReduce工作原理讲解
转载自http://www.aboutyun.com/thread-6723-1-1.html 有时候我们在用,但是却不知道为什么.就像苹果砸到我们头上,这或许已经是很自然的事情了,但是牛顿却发现了地 ...
- Hadoop化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- 一起学Hadoop——MapReduce原理
一致性Hash算法. Hash算法是为了保证数据均匀的分布,例如有3个桶,分别是0号桶,1号桶和2号桶:现在有12个球,怎么样才能让12个球平均分布到3个桶中呢?使用Hash算法的做法是,将1 ...
随机推荐
- 面试官问我,使用Dubbo有没有遇到一些坑?我笑了
17年的时候,因为一时冲动没把持住(当然最近也有粉丝叫我再冲动一把再更新一波),结合面试题写了一个系列的Dubbo源码解析.目前公众号大部分粉丝都是之前的粉丝,这里不过多介绍. 根据我的面试经验而言, ...
- android-support-v4.jar 免积分下载
资源名称:android扩展插件 android-support-v4.jar 资源大小:137KB 上传日期:2012-10-08 资源积分:1 下载次数:136 电信下载地址:http://www ...
- JavaScript 获得 坐标
<!DOCTYPE html> <html> <head> <title>location</title> <meta http-eq ...
- luogu1984 烧水问题 (找规律)
为了节省能量,我们会希望一个已经烧开了的水温度越低越好 那么可以得到结论,它要依次去碰当前温度从大到小的水 然后再把温度最高的烧开呗 可是直接模拟会T 稍微写一写大概能找到每次烧开花费能量的一个规律 ...
- UVALive - 6434 (思维题)
题目链接:https://vjudge.net/contest/241341#problem/A 题目大意,给你n个数字,让你分成m组,每组的花费为每组的最大值-最小值,总的花费就是各组花费相加,要求 ...
- 省选前的CF题
RT,即将退役的人懒得一篇篇写题解,于是有了这个东西 CF1004E 树上选一条不超过k个点的链,最小化其余点到链上点的最大距离 这个思路很有意思,不像平时一般的树上问题,是从叶子开始一点点贪心合并直 ...
- babel的使用及babel与gulp结合工作流
Babel 通过语法转换器支持最新版本的 JavaScript . 它有非常多的插件,这些插件能够允许我们立刻使用新语法,无需等待浏览器支持. 那我们怎么使用babel呢? 首先我们来了解babel基 ...
- springboot配置多环境
https://www.cnblogs.com/jason0529/p/6567373.html Spring的profiles机制,是应对多环境下面的一个解决方案,比较常见的是开发和测试环境的配 ...
- linux反向删除文件
Linux反选删除文件 最简单的方法是 # shopt -s extglob (打开extglob模式) # rm -fr !(file1) 如果是多个要排除的,可以这样: # rm -r ...
- jmeter oracle 多机 jdbc url配置
jmeter oracle 多机 jdbc url配置: jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HO ...