Python爬虫基础之认识爬虫
一、前言
爬虫Spider什么的,老早就听别人说过,感觉挺高大上的东西,爬网页,爬链接~~~dos黑屏的数据刷刷刷不断地往上冒,看着就爽,漂亮的校花照片,音乐网站的歌曲,笑话、段子应有尽有,全部都过来~~~
前段时间在学习Python打基础,一周时间过去了,是时候要开始写点东西了,Python爬虫刚好可验证下这段时间的学习成果,写写博文记录下自己学习爬虫的经过和遇到的坑,希望对同样是小白的园友有帮助!!!
我用的Python 3.5版本,2.7版本用的人也挺多的。
那么,接下来,我们要搞清楚几个问题:爬虫是什么东西?爬虫可以用来做什么?开发爬虫前需要掌握什么?
二、爬虫是什么东西
百度百科这么定义爬虫:

这里有几个关键词"规则","自动","万维网","程序"或者"脚本",理解了这几个关键词估计对爬虫就有个大体上的认识了。
接下来,会对这几个关键词就行解释.
三、爬虫从哪里爬取数据
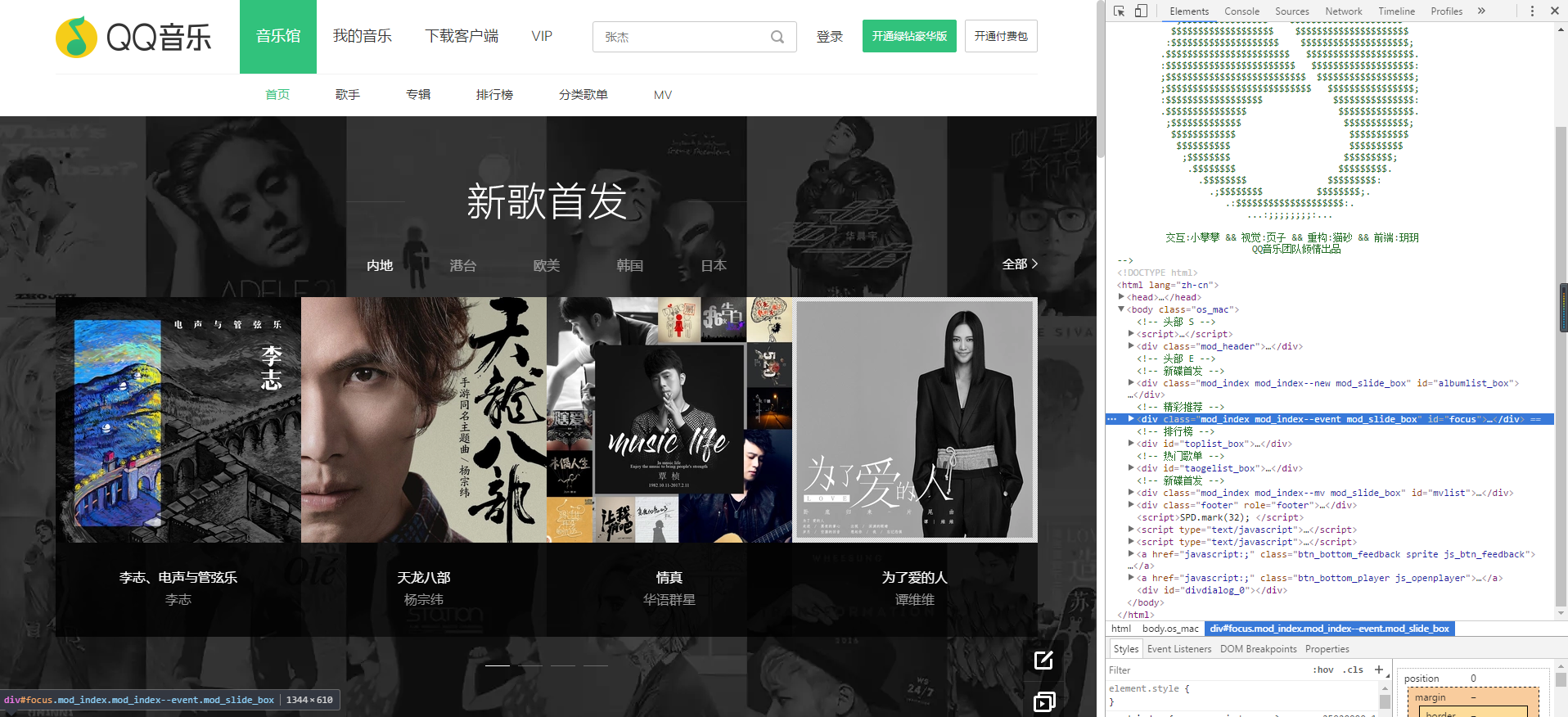
浏览器输入QQ音乐首页的网址:https://y.qq.com/,展现在我们面前的是浏览器解析器后的样子,敲击F12后,我们可以看到网页的源码,都是由一些html标签(标签我们这里用"节点"表示吧)构成。
所有网页的源码结构主要长的是这个样子:
<html>
<head>
<title>title name</title>
</head>
<body>
page content
</body>
</html>
关键词"万维网"?最简单的理解,万维网就是千千万万台电脑相互连接形成的像蜘蛛网一样的东西,我们的爬虫就是在这张网上干活,从网页上爬取信息。
关键词"规则"?这就是爬虫需要遵守的规则,<html>节点是<head>和<body>的父节点,<head>和<body>是子节点, 父节点包含子节点,子节点相邻的节点是兄弟节点,<title>是<html>的子孙节点,
这就构成了HTML DOM(文档对象模型),简单地说,爬虫就是爬取这些节点的内容,例如图片,文本等。。
关键词"自动"和"程序"或者"脚本"?可以理解成非人工的方式,也就是编写代码的方式,通过程序或者一段脚本(我们这里用Python脚本),自动按着我们预设的意愿工作,爬取我们认为有价值的信息,满足我们对信息的需求。
四、我的爬虫知识储备
HTML + CSS + Javascript
掌握一些HTML静态网页的知识,CSS样式,ID,标签,类选择器,还有Javascript如何定位和操作页面上的元素,w3school的教程,有教程和实例,还可以用来调试代码脚本,新手入门和知识查阅十分方便。网页解析方面,后面我们会用到正则表达式、BeautifulSoup和Lxml三种方式。
HTTP协议
具备一些网络方面的知识,了解浏览器和服务器之间的交互,如何发送http请求和处理请求结果。网页请求和下载网页,后面我们会用到Python的库urllib
Python
我们的脚本语言,这个自然不用说,必须掌握,入门推荐 runoob.com,Python基础 和 Python 3
掌握了以上知识,我们就可以开始实战了!!!
Python爬虫基础之认识爬虫的更多相关文章
- python爬虫基础16-cookie在爬虫中的应用
Cookie的Python爬虫应用 Cookie是什么 Cookie,有时也用其复数形式 Cookies,英文是饼干的意思.指某些网站为了辨别用户身份.进行 session 跟踪而储存在用户本地终端上 ...
- Python开发基础-Day15正则表达式爬虫应用,configparser模块和subprocess模块
正则表达式爬虫应用(校花网) import requests import re import json #定义函数返回网页的字符串信息 def getPage_str(url): page_stri ...
- python基础整理6——爬虫基础知识点
爬虫基础 什么是爬虫: 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁. ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- Python爬虫入门:爬虫基础了解
有粉丝私信我想让我出更基础一些的,我就把之前平台的copy下来了,可以粗略看一下,之后都会慢慢出. 1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫 ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
随机推荐
- Docker镜像拉不下来?试试这些
DaoCloud 加速器1.0(永久免费) DaoCloud是国内第一家Dock Hub加速器提供商 注意,加速器 2.0 需要使用 DaoCloud 自己的云服务器才可以使用.官方宣称会继续支持加速 ...
- 允许外网连接到云服务器的mongodb服务器
通过 vi /etc/mongdb.conf 修改bind_ip 进行配置.
- setData优化过程
https://blog.csdn.net/rolan1993/article/details/88106343 在做一个小球跟随手指移动的效果时候,由于在touchmove事件中频繁调用setDat ...
- SpringBoot返回date日期格式化,解决返回为TIMESTAMP时间戳格式或8小时时间差
问题描述 在Spring Boot项目中,使用@RestController注解,返回的java对象中若含有date类型的属性,则默认输出为TIMESTAMP时间戳格式 ,如下所示: 解决方案 ...
- gitignore的使用
gitignore的作用是忽略文件的提交,被加入到gitignore中的文件不会被提交到文件服务器 通常需要添加到.gitignore的文件有: (1)缓存相关文件,编译相关文件,运行时相关文件 (2 ...
- Python——Django-模板
一.模板的种类 1.变量 {{变量名}} 2.语句类{% %} 2.1 {%for i in booklist%} {{i}} {%endfor%} 2.2 {%if 10>5%} {%else ...
- Python 离线 安装requests第三方库
一.介绍 requests是Python的一个HTTP客户端库,跟urllib,urllib2类似,不过requests的优势在于使用简单,相同一个功能,用requests实现起来代码量要少很多.毕竟 ...
- 不同系统下的字长------typedef的意义
int的字节长度是由CPU和操作系统编译器共同决定的, 一般情况下,主要是由操作系统决定,比如,你在64位AMD的机器上安装的是32位操作系统,那么,int默认是32位的:如果是64位操作系统,64位 ...
- Django JSON,AJAX
JSON 概念 JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation) JSON 是轻量级的文本数据交换格式 JSON 独立于语言 * JSON 具 ...
- mongoDB 数据库操作
mongoDB 数据库操作 数据库命名规则 . 使用 utf8 字符,默认所有字符为 utf8 . 不能含有空格 . / \ "\0" 字符 (c++ 中会将 "\0&q ...