Python爬虫基础之认识爬虫
一、前言
爬虫Spider什么的,老早就听别人说过,感觉挺高大上的东西,爬网页,爬链接~~~dos黑屏的数据刷刷刷不断地往上冒,看着就爽,漂亮的校花照片,音乐网站的歌曲,笑话、段子应有尽有,全部都过来~~~
前段时间在学习Python打基础,一周时间过去了,是时候要开始写点东西了,Python爬虫刚好可验证下这段时间的学习成果,写写博文记录下自己学习爬虫的经过和遇到的坑,希望对同样是小白的园友有帮助!!!
我用的Python 3.5版本,2.7版本用的人也挺多的。
那么,接下来,我们要搞清楚几个问题:爬虫是什么东西?爬虫可以用来做什么?开发爬虫前需要掌握什么?
二、爬虫是什么东西
百度百科这么定义爬虫:

这里有几个关键词"规则","自动","万维网","程序"或者"脚本",理解了这几个关键词估计对爬虫就有个大体上的认识了。
接下来,会对这几个关键词就行解释.
三、爬虫从哪里爬取数据
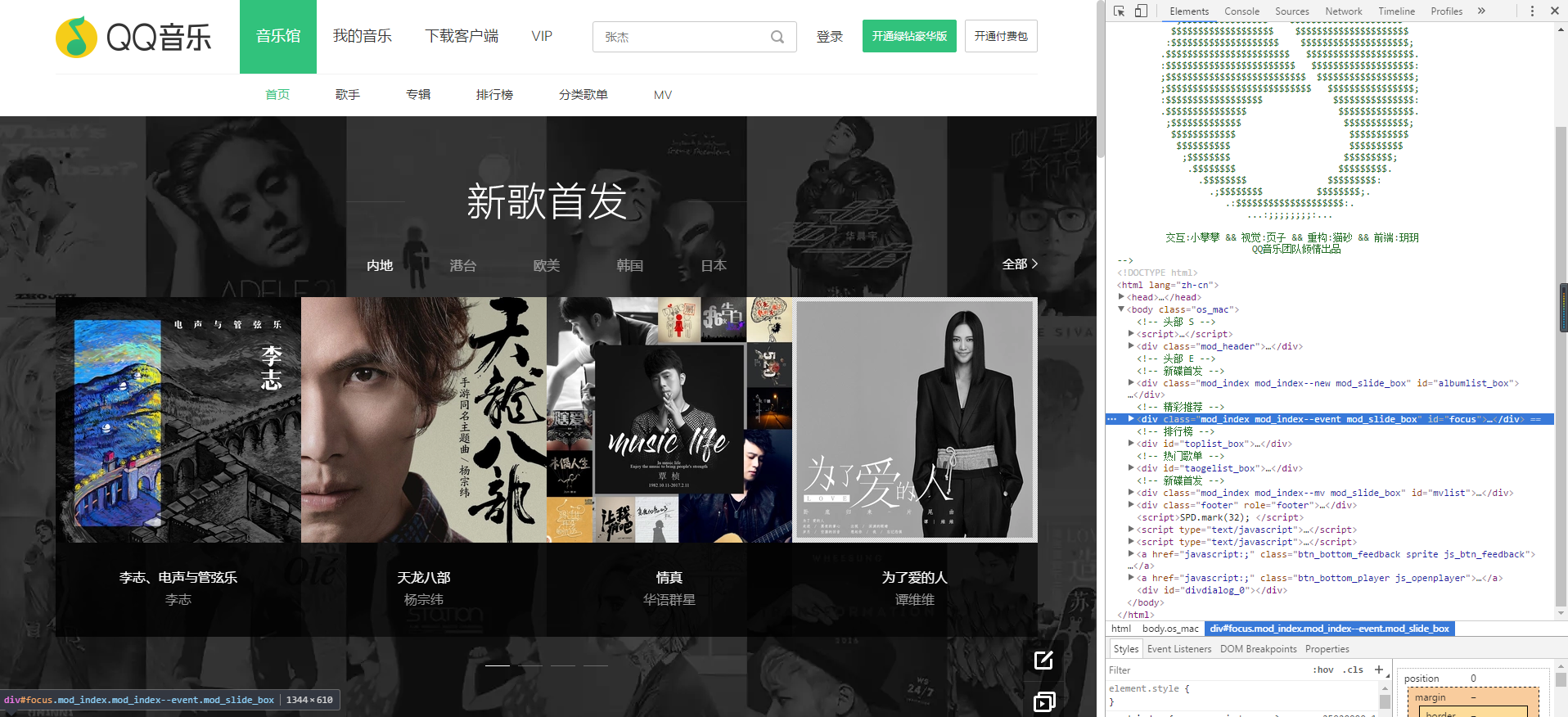
浏览器输入QQ音乐首页的网址:https://y.qq.com/,展现在我们面前的是浏览器解析器后的样子,敲击F12后,我们可以看到网页的源码,都是由一些html标签(标签我们这里用"节点"表示吧)构成。
所有网页的源码结构主要长的是这个样子:
<html>
<head>
<title>title name</title>
</head>
<body>
page content
</body>
</html>
关键词"万维网"?最简单的理解,万维网就是千千万万台电脑相互连接形成的像蜘蛛网一样的东西,我们的爬虫就是在这张网上干活,从网页上爬取信息。
关键词"规则"?这就是爬虫需要遵守的规则,<html>节点是<head>和<body>的父节点,<head>和<body>是子节点, 父节点包含子节点,子节点相邻的节点是兄弟节点,<title>是<html>的子孙节点,
这就构成了HTML DOM(文档对象模型),简单地说,爬虫就是爬取这些节点的内容,例如图片,文本等。。
关键词"自动"和"程序"或者"脚本"?可以理解成非人工的方式,也就是编写代码的方式,通过程序或者一段脚本(我们这里用Python脚本),自动按着我们预设的意愿工作,爬取我们认为有价值的信息,满足我们对信息的需求。
四、我的爬虫知识储备
HTML + CSS + Javascript
掌握一些HTML静态网页的知识,CSS样式,ID,标签,类选择器,还有Javascript如何定位和操作页面上的元素,w3school的教程,有教程和实例,还可以用来调试代码脚本,新手入门和知识查阅十分方便。网页解析方面,后面我们会用到正则表达式、BeautifulSoup和Lxml三种方式。
HTTP协议
具备一些网络方面的知识,了解浏览器和服务器之间的交互,如何发送http请求和处理请求结果。网页请求和下载网页,后面我们会用到Python的库urllib
Python
我们的脚本语言,这个自然不用说,必须掌握,入门推荐 runoob.com,Python基础 和 Python 3
掌握了以上知识,我们就可以开始实战了!!!
Python爬虫基础之认识爬虫的更多相关文章
- python爬虫基础16-cookie在爬虫中的应用
Cookie的Python爬虫应用 Cookie是什么 Cookie,有时也用其复数形式 Cookies,英文是饼干的意思.指某些网站为了辨别用户身份.进行 session 跟踪而储存在用户本地终端上 ...
- Python开发基础-Day15正则表达式爬虫应用,configparser模块和subprocess模块
正则表达式爬虫应用(校花网) import requests import re import json #定义函数返回网页的字符串信息 def getPage_str(url): page_stri ...
- python基础整理6——爬虫基础知识点
爬虫基础 什么是爬虫: 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁. ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- Python爬虫入门:爬虫基础了解
有粉丝私信我想让我出更基础一些的,我就把之前平台的copy下来了,可以粗略看一下,之后都会慢慢出. 1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫 ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
随机推荐
- 【第二篇】ASP.NET MVC快速入门之数据注解(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- Java 最常见的 200+ 面试题汇总
这份面试清单是我从 2015 年做 TeamLeader 之后开始收集的,一方面是给公司招聘用,另一方面是想用它来挖掘我在 Java 技术栈中的技术盲点,然后修复和完善它,以此来提高自己的技术水平.虽 ...
- c++入门之函数指针和函数对象
函数指针可以方便我们调用函数,但采用函数对象,更能体现c++面向对象的程序特性.函数对象的本质:()运算符的重载.我们通过一段代码来感受函数指针和函数对象的使用: int AddFunc(int a, ...
- openstack搭建之-keystone配置(8)
一. Base Node配置 mysql -uroot -proot CREATE DATABASE keystone GRANT ALL PRIVILEGES ON keystone.* to 'k ...
- safari打开的页面数字识别变为蓝色
今天网页碰到一个很怪异的问题:app打开的一个网页样式是好的,但通过safari打开后数字的颜色变为蓝色,并且还变得可点击了! 原来safari总会把长串数字识别为电话号码,文字变成蓝色,点击还会弹出 ...
- Python——socketserver编程(客户端/服务器)
一.socketserver是标准库中的高级模块,它的目标是简化很多多样板代码,是创建网络客户端和服务器所必须的代码.(事件驱动) 二.模块类 BaseServer :包含核心服务器功能和mix-in ...
- Nginx ServerName指令
L:47
- vue+webpack+vue-cli获取URL地址参数
在没有使用webpack+vue router开发中,想要获取RUL传的参数地址,直接通过一个函数就可以获得. 比如在 www.test.com/test.html?sign=test 地址中,想 ...
- 利用zabbix api添加、删除、禁用主机
python环境配置yum -y install python-pip安装argparse模块pip install -i https://pypi.douban.com/simple/ argpar ...
- 使用Spring Boot Actuator将指标导出到InfluxDB和Prometheus
使用Spring Boot Actuator将指标导出到InfluxDB和Prometheus Spring Boot Actuator是Spring Boot 2发布后修改最多的项目之一.它经过 ...