2018-2019-1 20189201 《LInux内核原理与分析》第七周作业
我的愿望是 好好学习Linux
一、书本第六章知识总结【进程的描述和进程的创建】
基础知识1
- 操作系统内核实现操作系统的三大管理功能,即进程管理功能,内存管理和文件系统。对应的三个抽象的概念是进程,虚拟内存和文件。
其中,操作系统最核心的功能是进程管理。 - 进程标识值:内核通过唯一的PID来标识每个进程。
- 进程状态:进程描述符中state域描述了进程的当前状态。
- iret与int 0x80指令对应,一个是离开系统调用弹出寄存器值,一个是进入系统调用压入寄存器的值。
- fork()函数最大的特点就是被调用一次,返回两次,在父进程中返回新创建子进程的 pid;在子进程中返回 0。
- 在Linux中,fork,vfork和clone这3个系统调用都通过do_fork来实现进程的创建。
- 在Linux中1号进程是所有用户态进程的祖先,2号进程是所有内核线程的祖先。
基础知识2
- 在操作系统原理中,通过进程控制块PCB描述进程;在Linux内核中,通过一个数据结构struct task_struct来描述进程。
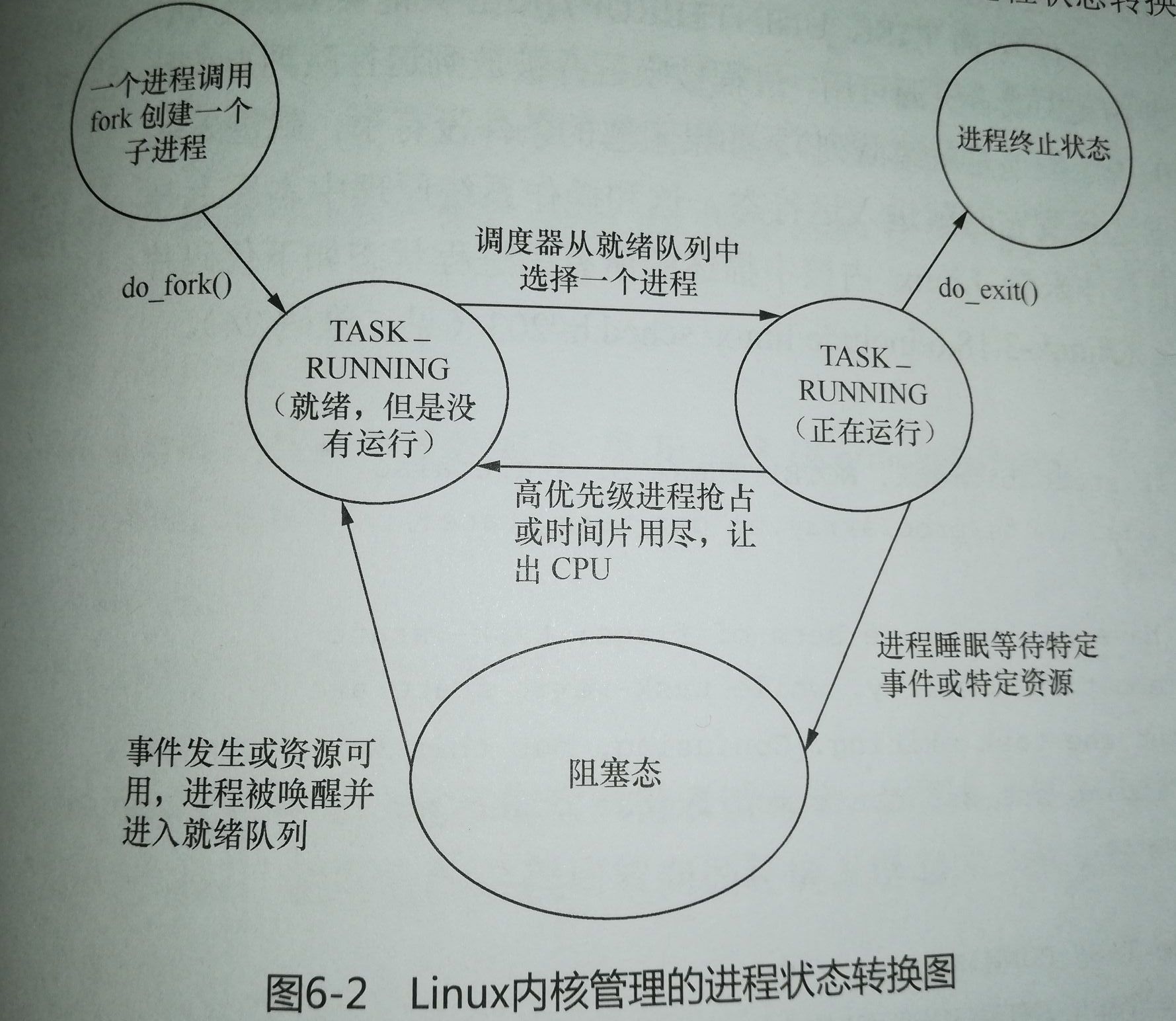
- 在操作系统原理中,进程有就绪态、运行态和阻塞态;在Linux内核中,就绪态和运行态都是相同的TASK_RUNNING状态另加上一个阻
塞态。在Linux内核中,当进程是TASK_RUNNING状态时,它是可运行的,就是就绪态,是否在运行取决于它有没有获得CPU的控制权。 - 对于一个正在运行的进程,调用用户态库函数exit()会陷入内核执行该内核函数do_exit(),进程会进入TASK_ZOMBIE状态,即中止状态,
Linux内核会在适当的时候把该进程处理掉,后释放进程描述符。一个正在运行的进程在等待特定事件或资源时会进入阻塞态,阻塞态分为两
种:TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE。前者可以被信号和wake_up()唤醒,后者只能被wake_up()唤醒。总结来说分这四种: - TASK_RUNNING:包括两种状态:进程就绪且没有运行、进程正在运行。这两种状态的区分取决于进程有没有获得CPU的分配权。
- TASK_ZOMBIE:进程的终止状态,此状态的进程被称作僵尸进程,在此状态下的进程会被Linux内核在适当的时候处理掉,同时进程描述符也将被释放。
- TASK_INTERRUPTIBLE :可以被信号或者是wake_up()唤醒。信号来临时,进程会被设置为TASK_RUNNING(仅仅是就绪状态而没有执行)
- TASK_UNINTERRUPTIBLE:只能被wake_up()唤醒
进程状态转换图如下图所示:
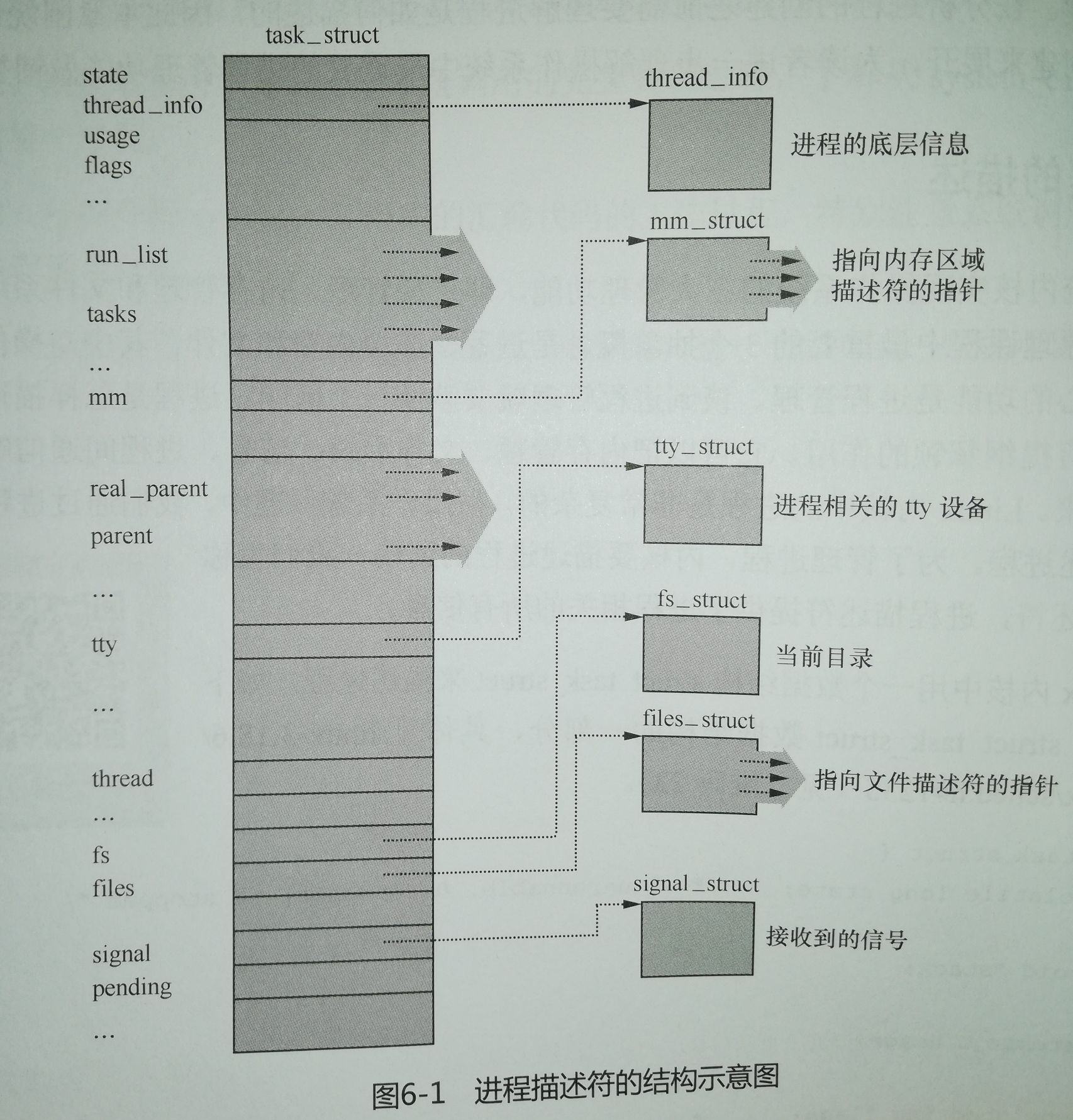
- 进程控制块PCB——task_struct,为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped 进程状态,-1表示不可执行,0表示可执行,大于1表示停止*/
void *stack; //内核堆栈
atomic_t usage;
unsigned int flags; /* per process flags, defined below 进程标识符 * /
unsigned int ptrace;如下图:

进程的创建
- start_ kernel,rest_init,kernel_ init kthreadd;
start_ kernel创建了rest_init,也就是0号进程。而0号进程又创建了两个线程,一个是kernel_ init,也就是1号进程,这个进程最终启动了用户态;
另一个是kthreadd内核线程是所有内核线程的祖先,负责管理所有内核线程。
0号进程是固定的代码,1号进程是通过复制0号进程PCB之后在此基础上做修改得到的。
创建进程的三个函数
- fork,创建子进程。
- vfork,与fork类似,但是父子进程共享地址空间,而且子进程先于父进程运行。
- clone,主要用于创建线程。
Linux通过复制父进程来创建一个新进程,通过调用do_ fork来实现。然后对子进程做一些特殊的处理。而Linux中的线程,又是一种特殊的进程。根
据代码的分析,do_ fork中,copy_ process管子进程运行的准备,wake_ up_ new_ task作为子进程forking的完成。
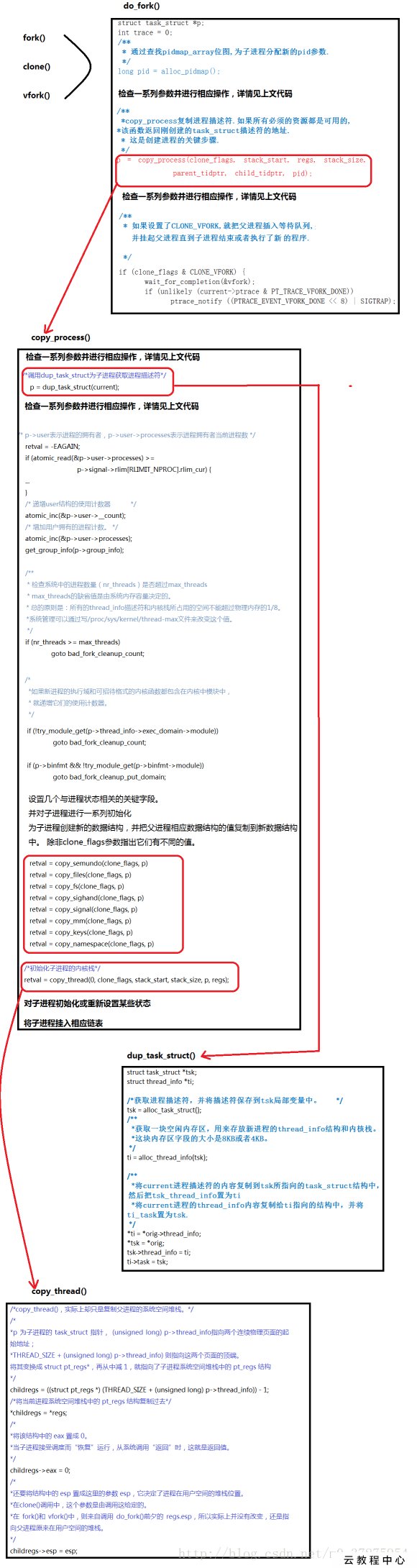
进程创建过程中的四个函数
- do_fork():创建进程;
- copy_process():创建进程内容(调用dup_task_struct、信息检查、初始化、更改进程状态、复制其他进程资源、调用copy_thread初始化子进
程内核栈、设置子进程pid等); - dup_task_struct():复制当前进程(父进程)描述符task_struct,分配子进程内核栈;
- copy_thread():内核栈关键信息初始化;
解析do_fork()
fork、vfork和clone这三个函数最终都是通过do_fork函数实现的。
do_fork的步骤:
- 调用copy_process,将当期进程复制一份出来为子进程,并且为子进程设置相应地上下文信息。
- 初始化vfork的完成处理信息(如果是vfork调用)
- 调用wake_up_new_task,将子进程放入调度器的队列中,此时的子进程就可以被调度进程选中,得以运行。
- 如果是vfork调用,需要阻塞父进程,知道子进程执行exec。
do_fork的代码:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
// ...
// 复制进程描述符,返回创建的task_struct的指针
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
// 取出task结构体内的pid
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
// 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
// 将子进程添加到调度器的队列,使得子进程有机会获得CPU
wake_up_new_task(p);
// ...
// 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间
// 保证子进程优先于父进程运行
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
关于copy_process函数
- 创建进程描述符以及子进程所需要的其他所有数据结构,为子进程准备运行环境。
- 调用dup_task_struct复制一份task_struct结构体,作为子进程的进程描述符。
- 复制所有的进程信息。
- 调用copy_thread,设置子进程的堆栈信息,为子进程分配一个pid。
关于dup_task_struct
- 先调用alloc_task_struct_node分配一个task_struct结构体。
- 调用alloc_thread_info_node,分配了一个union。这里分配了一个thread_info结构体,还分配了一个stack数组。
返回值为ti,实际上就是栈底。 - tsk->stack = ti将栈底的地址赋给task的stack变量。
- 最后为子进程分配了内核栈空间。
- 执行完dup_task_struct之后,子进程和父进程的task结构体,除了stack指针之外,完全相同。
关于copy_thread函数
- 获取子进程寄存器信息的存放位置
- 对子进程的thread.sp赋值,将来子进程运行,这就是子进程的esp寄存器的值。
- 如果是创建内核线程,那么它的运行位置是ret_from_kernel_thread, - 将这段代码的地址赋给thread.ip,之后准备其他寄存器信息,退出
- 将父进程的寄存器信息复制给子进程。
- 将子进程的eax寄存器值设置为0,所以fork调用在子进程中的返回值为0.
- 子进程从ret_from_fork开始执行,所以它的地址赋给thread.ip,也就是将来的eip寄存器。
新的进程从ret_from_fork处开始执行
- dup_task_struct中为其分配了新的堆栈。
- copy_process中调用了sched_fork,将其置为TASK_RUNNING。
- copy_thread中将父进程的寄存器上下文复制给子进程,这是非常关键的一步,这里保证了父子进程的堆栈信息是一致的。
- 将ret_from_fork的地址设置为eip寄存器的值,这是子进程的第一条指令。
整个详细过程:
二、实验部分【跟踪分析进程创建的过程】
(1)给操作系统MenuOS添加命令(fork功能)
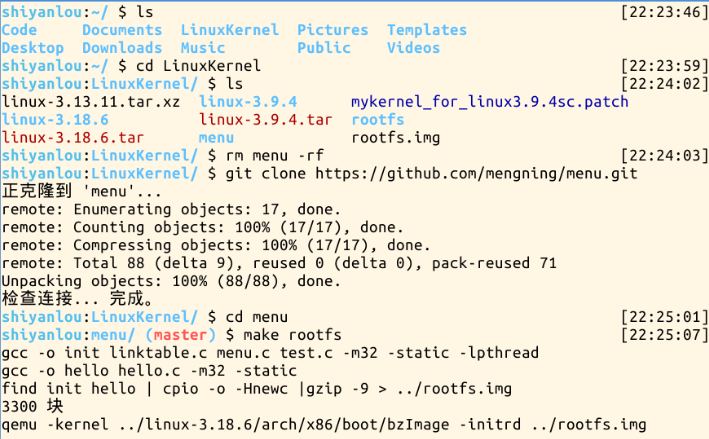
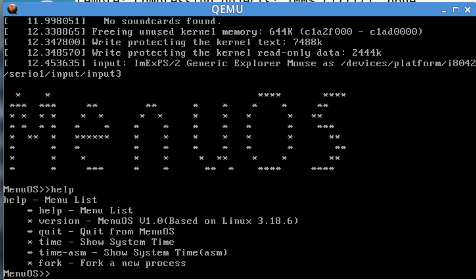
(2)使用gdb调试跟踪
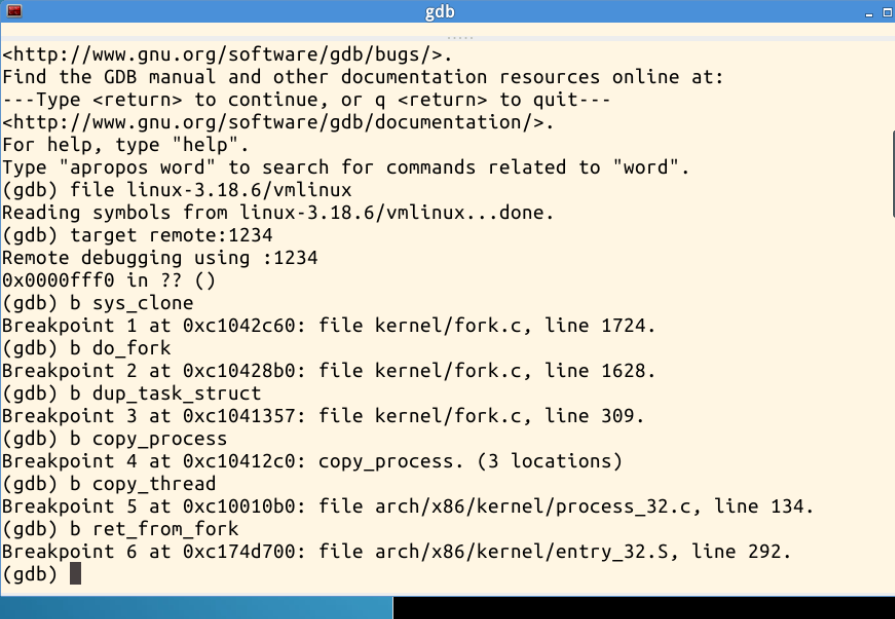
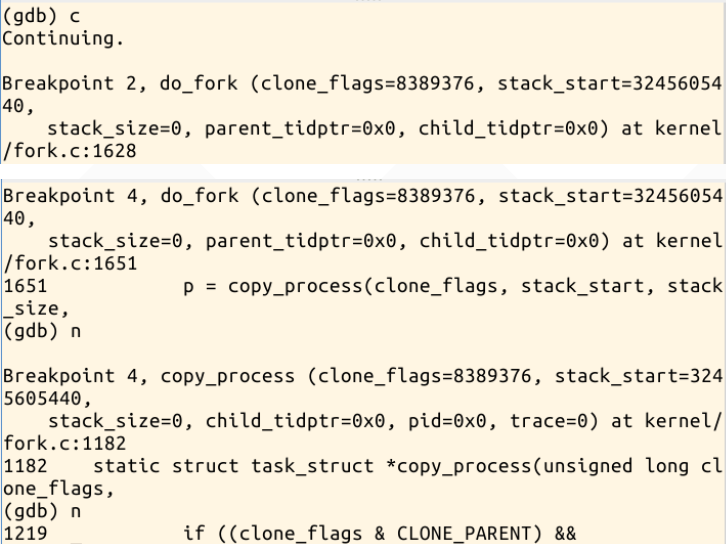
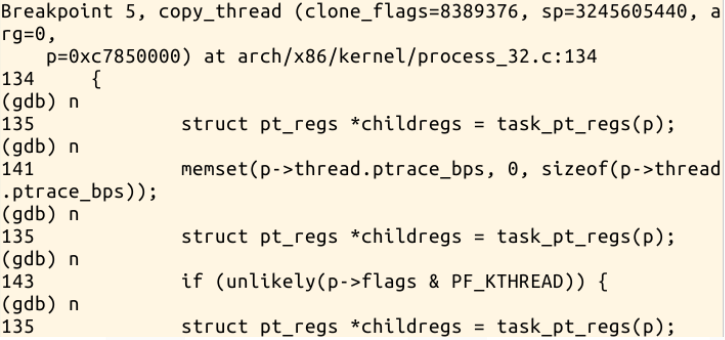
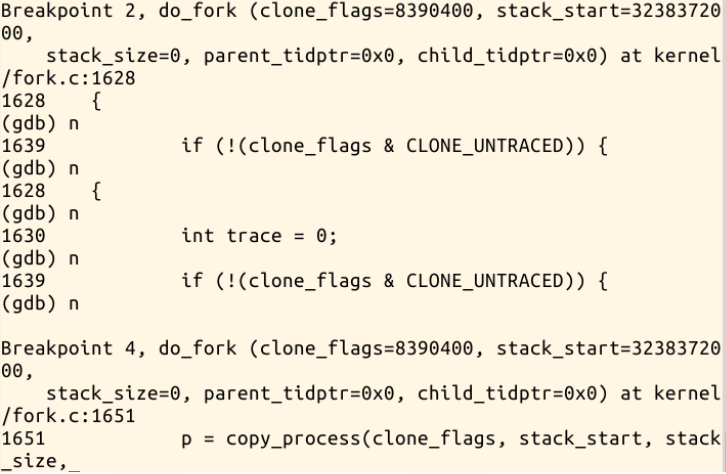
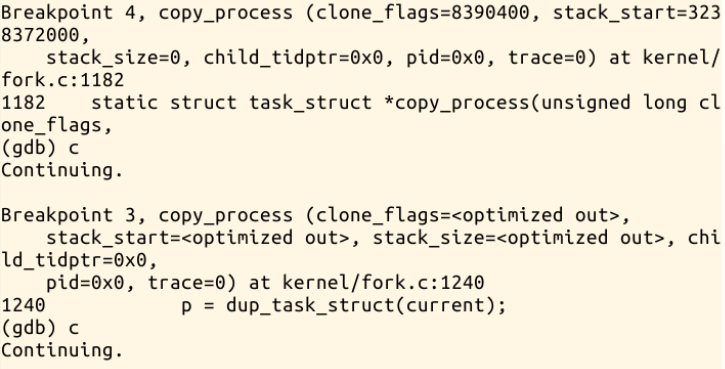
回到LinuxKernel目录下,fork指令实际上执行的就是sys_clone,我们可以在sys_clone、do_fork、dup_task_struct、copy_process、
copy_thread、ret_from_fork处设置断点,如下图所示:
*********************************************
*********************************************
*********************************************
*********************************************
最后通过函数syscall_exit退出;
三、实验收获
1. 小总结1
fork,vfork,clone都是linux的系统调用,这三个函数分别调用了sys_fork、sys_vfork、sys_clone,最终都调用了do_fork函数,差别在于参数
的传递和一些基本的准备工作不同,主要用来linux创建新的子进程或线程(vfork创造出来的是线程)。
fork()函数调用成功:返回两个值; 父进程:返回子进程的PID;子进程:返回0;失败:返回-1;
fork 创造的子进程复制了父亲进程的资源(写时复制技术),包括内存的内容task_struct内容(2个进程的pid不同)。
这里是资源的复制不是指针的复制。vfork也是创建一个子进程,但是子进程共享父进程的空间。在vfork创建子进程之后,父进程阻塞,直到子进程执行了exec()或者exit()。
故vfork创建出来的不是真正意义上的进程,而是一个线程,因为它缺少独立的内存资源。- int clone(int (fn)(void ), void child_stack, int flags, void arg)
- clone和fork的区别:
- clone和fork的调用方式很不相同,clone调用需要传入一个函数,该函数在子进程中执行。
- clone和fork最大不同在于clone不再复制父进程的栈空间,而是自己创建一个新的。 (void *child_stack,)也就是第二个参数,需要分配栈指针
的空间大小,所以它不再是继承或者复制,而是全新的创造。
- clone和fork的区别:
2. 小总结2
进程在创建时具有父子关系,通过调用fork()来创建一个新进程。创建的新进程是从return_from_fork开始执行的,复制内核堆栈只复制了一部分,int
指令和save_all压到内核栈的内容。参数,系统调用号等都进行压栈。fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork
来实现进程的创建。
2018-2019-1 20189201 《LInux内核原理与分析》第七周作业的更多相关文章
- 2019-2020-1 20199329《Linux内核原理与分析》第九周作业
<Linux内核原理与分析>第九周作业 一.本周内容概述: 阐释linux操作系统的整体构架 理解linux系统的一般执行过程和进程调度的时机 理解linux系统的中断和进程上下文切换 二 ...
- 2019-2020-1 20199329《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 一.上周问题总结: 未能及时整理笔记 Linux还需要多用 markdown格式不熟练 发布博客时间超过规定期限 二.本周学习内容: <庖丁解 ...
- 20169212《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 这一周学习了MOOCLinux内核分析的第一讲,计算机是如何工作的?由于本科对相关知识的不熟悉,所以感觉有的知识理解起来了有一定的难度,不过多查查资 ...
- 20169210《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 本周作业分为两部分:第一部分为观看学习视频并完成实验楼实验一:第二部分为看<Linux内核设计与实现>1.2.18章并安装配置内核. 第 ...
- 2018-2019-1 20189221 《Linux内核原理与分析》第九周作业
2018-2019-1 20189221 <Linux内核原理与分析>第九周作业 实验八 理理解进程调度时机跟踪分析进程调度与进程切换的过程 进程调度 进度调度时机: 1.中断处理过程(包 ...
- 2017-2018-1 20179215《Linux内核原理与分析》第二周作业
20179215<Linux内核原理与分析>第二周作业 这一周主要了解了计算机是如何工作的,包括现在存储程序计算机的工作模型.X86汇编指令包括几种内存地址的寻址方式和push.pop.c ...
- 2019-2020-1 20209313《Linux内核原理与分析》第二周作业
2019-2020-1 20209313<Linux内核原理与分析>第二周作业 零.总结 阐明自己对"计算机是如何工作的"理解. 一.myod 步骤 复习c文件处理内容 ...
- 2018-2019-1 20189221《Linux内核原理与分析》第一周作业
Linux内核原理与分析 - 第一周作业 实验1 Linux系统简介 Linux历史 1991 年 10 月,Linus Torvalds想在自己的电脑上运行UNIX,可是 UNIX 的商业版本非常昂 ...
- 《Linux内核原理与分析》第一周作业 20189210
实验一 Linux系统简介 这一节主要学习了Linux的历史,Linux有关的重要人物以及学习Linux的方法,Linux和Windows的区别.其中学到了LInux中的应用程序大都为开源自由的软件, ...
- 2018-2019-1 20189221《Linux内核原理与分析》第二周作业
读书报告 <庖丁解牛Linux内核分析> 第 1 章 计算工作原理 1.1 存储程序计算机工作模型 1.2 x86-32汇编基础 1.3汇编一个简单的C语言程序并分析其汇编指令执行过程 因 ...
随机推荐
- 【并发编程】【JDK源码】J.U.C--线程池
原文:慕课网实战·高并发探索(十四):线程池 Executor new Thread的弊端 每次new Thread 新建对象,性能差. 线程缺乏统一管理,可能无限制的新建线程,相互竞争,可能占用过多 ...
- Codeforces 1082C Multi-Subject Competition(前缀+思维)
题目链接:Multi-Subject Competition 题意:给定n名选手,每名选手都有唯一选择的科目si和对应的能力水平.并且给定科目数量为m.求选定若干个科目,并且每个科目参与选手数量相同的 ...
- Eclipse 添加 Source 源代码、Javadoc 文档
源代码 Source 按住 Ctrl 键,鼠标放到对应的类.方法上,出现 Open Declaration,Open Implementation ,可查看对应的实现.声明源代码. 也可以在[Proj ...
- 【Linux网络编程】TCP网络编程中connect()、listen()和accept()三者之间的关系
[Linux网络编程]TCP网络编程中connect().listen()和accept()三者之间的关系 基于 TCP 的网络编程开发分为服务器端和客户端两部分,常见的核心步骤和流程如下: conn ...
- angular的小实例
主要是使用了angular的指令. 学习地址:http://www.runoob.com/angularjs/angularjs-tutorial.html 1. 效果: 输入数据剩余字数会相应减少, ...
- dubbo本地服务化实现(dubbo三)
一.dubbo服务化架构包含的内容 对于传统工程而言,分层的依据是按照包来区分.由于在相同的工程中,所以服务的提供和调用可以方便的实现. 但是对于分布式架构而言,服务的提供者负责服务具体的实现和接口规 ...
- css长度单位学习(em,rem,px,vw,vh)
绝对长度单位 绝对长度单位代表一个物理测量 [像素px(pixels)] 像素,为影像显示的基本单位,译自英文"pixel",pix是英语单词picture的常用简写,加上英语单词 ...
- Javaweb学习笔记——(二十三)——————AJAX、XStream、JSON
AJAX概述 1.什么是AJAX ajax(Asynchronous JavaScript and xml) 翻译成中文就是"异步JavaScript和xml&quo ...
- dense prediction问题
dense prediction 理解:标注出图像中每个像素点的对象类别,要求不但给出具体目标的位置,还要描绘物体的边界,如图像分割.语义分割.边缘检测等等. 基于深度学习主要的做法有两种: 基于图 ...
- JSON 之 SuperObject(11): TSuperTableString、TSuperAvlEntry
JSON 之 SuperObject(11): TSuperTableString.TSuperAvlEntry - 万一 - 博客园http://www.cnblogs.com/del/archiv ...