DeepCTR专题:Neural Factorization Machines 论文学习和实现及感悟
papers地址:https://arxiv.org/pdf/1708.05027.pdf
借用论文开头,目前很多的算法任务都是需要使用category feature,而一般对于category feature处理的方式是经过one hot编码,然后我们有些情况下,category feature 对应取值较多时,如:ID等,one hot 编码后,数据会变得非常的稀疏,不仅给算法带来空间上的复杂度,算法收敛也存在一定的挑战。
为了能解决one hot 编码带来的数据稀疏性的问题,我们往往能想到的是不是通过其他的编码Embeding方式。恰好深度学习的爆发,我们可以通过深度学习构架神经网络对category feature进行embeding。为了介绍该篇论文,主要围绕该篇论文进行介绍一下。论文主要分为四个部分:
第一部分:介绍背景
第二部分:介绍Factorization Machines和DNN
第三部分:介绍NFM网络结构及其原理(本文的重点)
第四部分:实验部分
最后谈谈个人的理解和想法。
1、介绍背景
如上面所述,背景部分主要内容说的现阶段的问题和痛点:
(1)category feature在传统机器学习中处理的方法——one hot编码,而这种编码方式会带来数据的维度暴增和数据的稀疏性。这个会给传统机器学习带来空间复杂度和算法收敛较为困难。
(2)FM的二阶交叉项仅仅是两两之间的交叉特征,对于三阶或者高阶的特征并不能很好的表达。
2、介绍Factorization Machines和DNN
(1)Factorization Machines 因式分解机
因式分解机是在LR的基础之上,增加一个二阶交叉特征。其表达式如下所示:

其中,vi和vj是通过矩阵分解的方式得到。
(2)DNN
DNN实际上就会一个全连接的深度神经网络,该网络的特点主要是具有一定的层数,层与层之间是全连接的。
3、NFM网络及其原理
(1)NFM的原理和表达式:

从表达我们可以看出,其基本形式与FM是一致的,区别在于最后一项,NFM使用的是一个f(x)来表示,实际上该f(x)是一个统称,他表示的一个网络的输出。该网络如下所示:
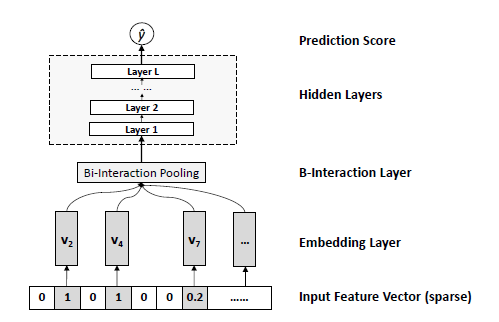
从f(x)的网络结构我们同样可以看出,其主要解决的问题就是二阶交叉项的问题。其结构是:
1)第一层是输入层/,即输入category feature
2)第二层Embeding,对category feature进行编码
3)第三层是二阶交叉项层,该层论文中主要是通过网络得到二阶交叉特征,计算方式:(a+b)^2-a*b 得到二阶交叉项
4)DNN层,该层是通过DNN提取高阶特征
以上就是NFM的基本原理和网络结构。
4、实验部分
实验部分主要用了两个数据集,分别如下:

实验结构如下所示:

5、感悟
从该论文内容来看,基本上还是围绕着怎么解决(1)category feature 编码的问题和(2)获取高阶特征,通过神经网络来优化FM,提出了一个NFM的网络结构。论文主要创新点是:
1、Embeding
2、将二阶交叉特征通过DNN提取高阶特征
DeepCTR专题:Neural Factorization Machines 论文学习和实现及感悟的更多相关文章
- DeepCTR专题:DeepFM论文学习和实现及感悟
论文地址:https://arxiv.org/pdf/1703.04247.pdf CTR预估我们知道在比较多的应用场景下都有使用.如:搜索排序.推荐系统等都有广泛的应用.并且CTR具有极其重要的 地 ...
- Factorization Machines 学习笔记(三)回归和分类
近期学习了一种叫做 Factorization Machines(简称 FM)的算法,它可对随意的实值向量进行预測.其主要长处包含: 1) 可用于高度稀疏数据场景:2) 具有线性的计算复杂度.本文 ...
- Factorization Machines 学习笔记(四)学习算法
近期学习了一种叫做 Factorization Machines(简称 FM)的算法.它可对随意的实值向量进行预測.其主要长处包含: 1) 可用于高度稀疏数据场景:2) 具有线性的计算复杂度.本文 ...
- Factorization Machines 学习笔记(二)模型方程
近期学习了一种叫做 Factorization Machines(简称 FM)的算法,它可对随意的实值向量进行预測.其主要长处包含: 1) 可用于高度稀疏数据场景:2) 具有线性的计算复杂度.本文 ...
- Faster RCNN论文学习
Faster R-CNN在Fast R-CNN的基础上的改进就是不再使用选择性搜索方法来提取框,效率慢,而是使用RPN网络来取代选择性搜索方法,不仅提高了速度,精确度也更高了 Faster R-CNN ...
- 论文学习笔记 - 高光谱 和 LiDAR 融合分类合集
A³CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Se ...
- 分解机(Factorization Machines)推荐算法原理
对于分解机(Factorization Machines,FM)推荐算法原理,本来想自己单独写一篇的.但是看到peghoty写的FM不光简单易懂,而且排版也非常好,因此转载过来,自己就不再单独写FM了 ...
- 【论文学习】Is the deconvolution layer the same as a convolutional layer
结合上升采样upsample和卷积操作.Sub-piexl convolution. Efficient Sub-pixel-convolutional-layers. LR network,即低分辨 ...
- 《Explaining and harnessing adversarial examples》 论文学习报告
<Explaining and harnessing adversarial examples> 论文学习报告 组员:裴建新 赖妍菱 周子玉 2020-03-27 1 背景 Sz ...
随机推荐
- 关于li标签的value属性值的获取问题
在前几天的开发过程中,遇到了这样一个问题. 在li标签中嵌入了一个value属性,如这样滴: <li id="ts1" value="0001">& ...
- JS 作用域与变量提升---JS 学习笔记(三)
你知道下面的JavaScript代码执行时会输出什么吗? var foo = 1; function bar() { if (!foo) { var foo = 10; } console.log(f ...
- Qt551.主窗体Margin
1.直接拖控件的方式,Margin的设置 不是在 MainWindow中 而是在 MainWindow下面的centralwidget中,如下图: 2. 3. 4. 5.
- Axure文本框验证和外部url的调用
文本框的验证和外部url的调用: 场景: 当输入文本框中的内容是满足下面条件时:输入4-10的数字,页面会跳转到QQ注册(https://ssl.zc.qq.com/v3/index-chs.html ...
- 【转】 HDMI介绍与流程
转自:https://www.cnblogs.com/TaigaCon/p/3840653.html HDMI,全称为(High Definition Multimedia Interface)高清多 ...
- poj3162
这题卡常数了,nlogn链式前向星过了,用vector的O(n)没过. #include <iostream> #include <cstdio> #include <c ...
- Headless Service 和Service
定于spec:clusterIP: None 还记得Service的Cluster IP是做什么的吗?对,一个Service可能对应多个EndPoint(Pod),client访问的是Cluster ...
- 缓存之Memcache
Memcache Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度. ...
- W10激活
1.首先,我们先查看一下Win10正式专业版系统的激活状态: 点击桌面左下角的“Windows”按钮,从打开的扩展面板中依次点击“设置”-“更新和安全”,并切换到“激活”选项卡,在此就可以查看到当前系 ...
- Table 类(数据表基类)
只修改数据表某条记录的部分字段(究极进化): public class TableHelper { private Dictionary<string, object> temp; pub ...