【Spark篇】---Spark中Shuffle机制,SparkShuffle和SortShuffle
一、前述
Spark中Shuffle的机制可以分为HashShuffle,SortShuffle。
SparkShuffle概念
reduceByKey会将上一个RDD中的每一个key对应的所有value聚合成一个value,然后生成一个新的RDD,元素类型是<key,value>对的形式,这样每一个key对应一个聚合起来的value。
问题:聚合之前,每一个key对应的value不一定都是在一个partition中,也不太可能在同一个节点上,因为RDD是分布式的弹性的数据集,RDD的partition极有可能分布在各个节点上。
如何聚合?
– Shuffle Write:上一个stage的每个map task就必须保证将自己处理的当前分区的数据相同的key写入一个分区文件中,可能会写入多个不同的分区文件中。
– Shuffle Read:reduce task就会从上一个stage的所有task所在的机器上寻找属于己的那些分区文件,这样就可以保证每一个key所对应的value都会汇聚到同一个节点上去处理和聚合。
Spark中有两种Shuffle类型,HashShuffle和SortShuffle,Spark1.2之前是HashShuffle默认的分区器是HashPartitioner,Spark1.2引入SortShuffle默认的分区器是RangePartitioner。
二、具体
1、HashShuffle
1) 普通机制
- 普通机制示意图
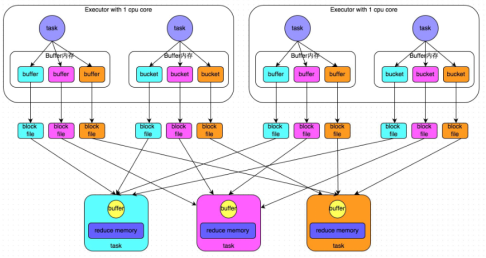
- 执行流程
a) 每一个map task将不同结果写到不同的buffer中,每个buffer的大小为32K。buffer起到数据缓存的作用。新写的磁盘小文件会追加内容。
b) 每个buffer文件最后对应一个磁盘小文件。
c) reduce task来拉取对应的磁盘小文件。
- 总结
a) maptask的计算结果会根据分区器(默认是hashPartitioner)来决定写入到哪一个磁盘小文件中去。ReduceTask会去Map端拉取相应的磁盘小文件。
b)产生的磁盘小文件的个数:M(map task的个数)*R(reduce task的个数)
- 存在的问题
产生的磁盘小文件过多,会导致以下问题:
a) 在Shuffle Write过程中会产生很多写磁盘小文件的对象。
b) 在Shuffle Read过程中会产生很多读取磁盘小文件的对象。
c) 在JVM堆内存中对象过多会造成频繁的gc,gc还无法解决运行所需要的内存 的话,就会OOM。gc工作的时候是不提供工作的。
d) 在数据传输过程中会有频繁的网络通信,频繁的网络通信出现通信故障的可能性大大增加,一旦网络通信出现了故障会导致shuffle file cannot find 由于这个错误导致的task失败,TaskScheduler不负责重试,由DAGScheduler负责重试Stage。变相的延长执行时间
1) 合并机制
- 合并机制示意图
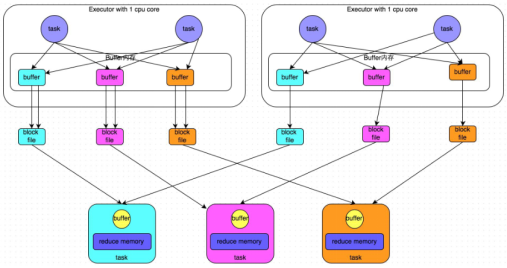
一个core 一般运行一个task,图中即便一个executor有两个task,也是串行执行的!!!!
- 总结
产生磁盘小文件的个数:C(core的个数)*R(reduce的个数)
2、SortShuffle
1) 普通机制
- 普通机制示意图
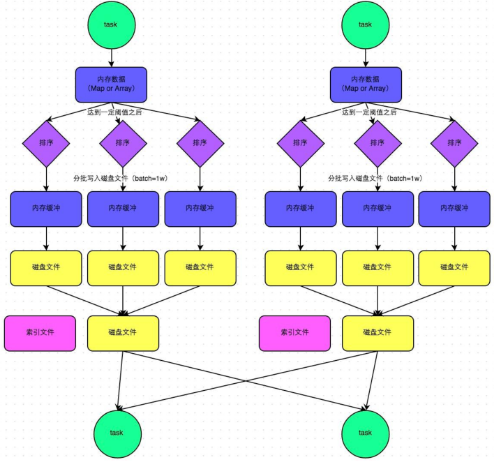
- 执行流程
a) map task 的计算结果会写入到一个内存数据结构里面,内存数据结构默认是5M
b) 在shuffle的时候会有一个定时器,不定期的去估算这个内存结构的大小,当内存结构中的数据超过5M时,比如现在内存结构中的数据为5.01M,那么他会申请5.01*2-5=5.02M内存给内存数据结构。
c) 如果申请成功不会进行溢写,如果申请不成功,这时候会发生溢写磁盘。
d) 在溢写之前内存结构中的数据会进行排序分区
e) 然后开始溢写磁盘,写磁盘是以batch的形式去写,一个batch是1万条数据,
f) map task执行完成后,会将这些磁盘小文件合并成一个大的磁盘文件(有序),同时生成一个索引文件。
g) reduce task去map端拉取数据的时候,首先解析索引文件,根据索引文件再去拉取对应的数据。
- 总结
产生磁盘小文件的个数: 2*M(map task的个数)索引文件-和磁盘文件
2) bypass机制(比如wordcount)不需要排序时使用
- bypass机制示意图
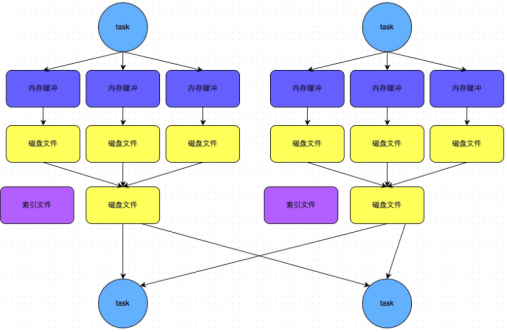
- 总结
a) bypass运行机制的触发条件如下:
shuffle reduce task的数量小于spark.shuffle.sort.bypassMergeThreshold的参数值。这个值默认是200。
b)产生的磁盘小文件为:2*M(map task的个数)
【Spark篇】---Spark中Shuffle机制,SparkShuffle和SortShuffle的更多相关文章
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- 【Spark篇】---Spark中Shuffle文件的寻址
一.前述 Spark中Shuffle文件的寻址是一个文件底层的管理机制,所以还是有必要了解一下的. 二.架构图 三.基本概念: 1) MapOutputTracker MapOutputTracker ...
- 【Spark篇】---Spark调优之代码调优,数据本地化调优,内存调优,SparkShuffle调优,Executor的堆外内存调优
一.前述 Spark中调优大致分为以下几种 ,代码调优,数据本地化,内存调优,SparkShuffle调优,调节Executor的堆外内存. 二.具体 1.代码调优 1.避免创建重复的RDD,尽 ...
- Spark中shuffle的触发和调度
Spark中的shuffle是在干嘛? Shuffle在Spark中即是把父RDD中的KV对按照Key重新分区,从而得到一个新的RDD.也就是说原本同属于父RDD同一个分区的数据需要进入到子RDD的不 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
- Spark Shuffle机制详细源码解析
Shuffle过程主要分为Shuffle write和Shuffle read两个阶段,2.0版本之后hash shuffle被删除,只保留sort shuffle,下面结合代码分析: 1.Shuff ...
- Spark性能优化指南-高级篇(spark shuffle)
Spark性能优化指南-高级篇(spark shuffle) 非常好的讲解
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- Spark记录-Spark性能优化(开发、资源、数据、shuffle)
开发调优篇 原则一:避免创建重复的RDD 通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD:接着对这个RDD执行某个算子操作,然后得到 ...
随机推荐
- JMeter调试参数是否取值正确,调试正则提取的结果(log.info|log.error|print)
JMeter调试参数是否取值正确,调试正则提取的结果(log.info | log.error | print) Jmeter的log输出控制(jmeter.log) 1 2 log_level.jm ...
- 第二次作业-熟悉git
GIT地址 https://github.com/gentlemanzq/yunsuanhomework GIT用户名 gentlemanzq 学号后五位 62320 博客地址 https://w ...
- java做图片点击文字验证码
https://blog.csdn.net/qq_27721169/article/details/82769093
- 【ABP.Net】2.多数据库支持&&初始化数据库
abp默认连接的数据库是MSSQL,但是在开发过程中往往很多开发者不满足于mssql. 所以这里演示一下把mssql改成postgresql,来进行接下来的系统开发. abp的orm是用EF的.那么我 ...
- 使用ACR122U NFC读卡器对M1卡进行读写操作(可以读写中文)
因为项目需要,第一次接触到了ACR122U NFC读卡器(非接触式)和M1卡,首先介绍一下想要读写应该知道的基本知识. 我就根据我的理解先叙述一下: ACR122U 是一款连机非接触式智能卡读写器,可 ...
- WinCC OA基本概念
WinCC OA 是一个模块化软件架构的系统.所需的功能由不同任务创建的特定单元处理.在WinCC OA中,这些单元称为管理器 - 管理器是软件自身的一些独立的处理过程. 图:WinCC OA系统由功 ...
- 自己编译Android(小米5)内核并刷入(一键自动编译打包)
之前自己编译过Android系统,刷入手机.编译很简单,但坑比较大,主要是GFW埋的坑.. 编译android系统太大了,今天记下自己编译及刷入android内核的方法. 主要是看到第三方内核可以超频 ...
- c# Exchange 收件箱获取。
public List<Email> GetInbox() { try { List<Email> lstEmails = new List<Email>(); F ...
- [微信跳转链接]之WAP跳转微信内指定页面
由于微信覆盖太全面了,几乎所有人都使用微信APP,但是对于做产品的公司来说,所有的产品几乎都离不开微信的推广,然而微信属于封闭式的一个社交应用,大部分只能在今日头条,百度,等等...如果你在推广页面上 ...
- msxfs.dll函数加载代码
msxfs.dll函数加载代码 #include "stdafx.h" #include "WSXFSLoader.h" NS_AWP_DEVICE_WOSA_ ...