【Spark篇】---Spark初始
一、前述
Spark是基于内存的计算框架,性能要优于Mapreduce,可以实现hadoop生态圈中的多个组件,是一个非常优秀的大数据框架,是Apache的顶级项目。One stack rule them all 霸气。
但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法
二、具体细节
1、Spark与MapReduce的区别
都是分布式计算框架,Spark基于内存,MR基于HDFS。Spark处理数据的能力一般是MR的十倍以上,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序。
2、Spark运行模式
- Local
多用于本地测试,如在eclipse,idea中写程序测试等。
- Standalone
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
- Yarn
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
- Mesos
资源调度框架。
注意:要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以基于Yarn。
3、SparkCore
概念
RDD(Resilient Distributed Dateset),弹性分布式数据集。
RDD的五大特性:(比较重要)
- RDD是由一系列的partition组成的。
- 函数是作用在每一个partition(split)上的。
- RDD之间有一系列的依赖关系。
- 分区器是作用在K,V格式的RDD上。
- RDD提供一系列最佳的计算位置。Partiotion对外提供数据处理的本地化,计算移动,数据不移动。
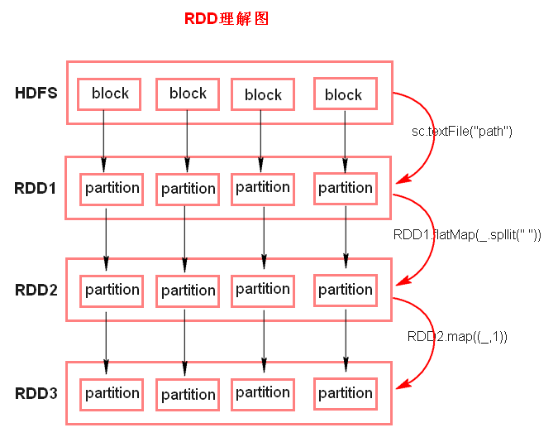
备注:
1、textFile方法底层封装的是读取MR读取文件的方式,读取文件之前先split,默认split大小是一个block大小。每个split对应一个partition。
2、RDD实际上不存储数据,存储的是计算逻辑,这里方便理解,暂时理解为存储数据。
3、什么是K,V格式的RDD?
- 如果RDD里面存储的数据都是二元组对象,那么这个RDD我们就叫做K,V格式的RDD。
4、 哪里体现RDD的弹性(容错)?
- partition数量,大小没有限制,体现了RDD的弹性。Partiotion个数可以控制。可以提高并行度。
- RDD之间依赖关系,可以基于上一个RDD重新计算出RDD。
5、哪里体现RDD的分布式?
- RDD是由Partition组成,partition是分布在不同节点上的。 RDD提供计算最佳位置,体现了数据本地化。体现了大数据中“计算移动数据不移动”的理念。
4、Spark任务执行原理
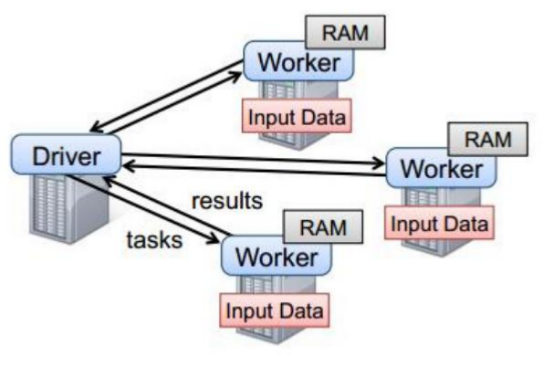
以上图中有四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中的进程。
- Driver与集群节点之间有频繁的通信。
- Driver负责任务(tasks)的分发和结果的回收。任务的调度。如果task的计算结果非常大就不要回收了。会造成oom。
- Worker是Standalone资源调度框架里面资源管理的从节点。也是JVM进程。
- Master是Standalone资源调度框架里面资源管理的主节点。也是JVM进程。
5、Spark代码流程
1、创建SparkConf对象
SparkConf conf = new SparkConf().setMaster("local").setAppName("xxx")
- 1.设置运行模式
- 2.设置application name
- 3.设置spark运行参数
2、创建SparkContext对象
集群的唯一入口
3、基于Spark的上下文创建一个RDD,对RDD进行处理。
由SparkContext创建RDD
4、应用程序中要有Action类算子来触发Transformation类算子执行。
5、关闭Spark上下文对象SparkContext。
【Spark篇】---Spark初始的更多相关文章
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- Spark性能优化指南-高级篇(spark shuffle)
Spark性能优化指南-高级篇(spark shuffle) 非常好的讲解
- 【转帖】HBase读写的几种方式(二)spark篇
HBase读写的几种方式(二)spark篇 https://www.cnblogs.com/swordfall/p/10517177.html 分类: HBase undefined 1. HBase ...
- 转载:Spark中文指南(入门篇)-Spark编程模型(一)
原文:https://www.cnblogs.com/miqi1992/p/5621268.html 前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apac ...
- Oozie分布式任务的工作流——Spark篇
Spark是现在应用最广泛的分布式计算框架,oozie支持在它的调度中执行spark.在我的日常工作中,一部分工作就是基于oozie维护好每天的spark离线任务,合理的设计工作流并分配适合的参数对于 ...
- 【Spark篇】---SparkSQL on Hive的配置和使用
一.前述 Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行. 二.具体配置 1.在Spark客户端配置Hive On Spark 在Spark客户端安装包下sp ...
- 基于Hive进行数仓建设的资源元数据信息统计:Spark篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- 【转】科普Spark,Spark是什么,如何使用Spark
本博文是转自如下链接,为了方便自己查阅学习和他人交流.感谢原博主的提供! http://www.aboutyun.com/thread-6849-1-1.html http://www.aboutyu ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark记录-spark编程介绍
Spark核心编程 Spark 核心是整个项目的基础.它提供了分布式任务调度,调度和基本的 I/O 功能.Spark 使用一种称为RDD(弹性分布式数据集)一个专门的基础数据结构,是整个机器分区数据的 ...
随机推荐
- SparkSQL
Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet,并且作为分布式SQL查询引擎的作用. Hive SQL是转换成 ...
- PTA_输入符号及符号个数打印沙漏(C++)
思路:想将所有沙漏所需符号数遍历一遍,然后根据输入的数判断需要输出多少多少层的沙漏,然后分两部分输出沙漏. #include<iostream> #include<cstring ...
- HDU 2243考研路茫茫——单词情结 (AC自动机+矩阵快速幂)
背单词,始终是复习英语的重要环节.在荒废了3年大学生涯后,Lele也终于要开始背单词了. 一天,Lele在某本单词书上看到了一个根据词根来背单词的方法.比如"ab",放在单词前一般 ...
- 【Vue-Cli3.0】【2】渲染
哈哈哈,发工资啦,发工资啦,立刻就买了一个matebook D .开启了新的编程工作区了. 进入正题 Vue.js 的核心是一个允许采用简洁的模板语法来声明式地将数据渲染进 DOM 的系统.这句话来自 ...
- [Git]2018-10 解决git cmd中文乱码问题
2018年10月12日 莫名其妙出现cmd下git log中文乱码问题,显示一堆<E4><A8>之类的乱码.git bash却一切正常. 怀疑是Windows系统升级出现的不兼 ...
- oracle行转列、列转行、连续日期数字实现方式及mybatis下实现方式
转载请注明出处:https://www.cnblogs.com/funnyzpc/p/9977591.html 九月份复习,十月份考试,十月底一直没法收心,赶在十一初 由于不可抗拒的原因又不得不重新找 ...
- Spring Cloud微服务笔记(四)客户端负载均衡:Spring Cloud Ribbon
客户端负载均衡:Spring Cloud Ribbon 一.负载均衡概念 负载均衡在系统架构中是一个非常重要,并且是不得不去实施的内容.因为负载均衡对系统的高可用性. 网络压力的缓解和处理能力的扩容的 ...
- Flask消息验证与提示
一,消息提示基本语法. 1,先新建一个Flask工作空间. 2,新建后自动得到一个app.py文件,直接运行可以看到基本效果.然后引入 from flask import flash.使用这个flas ...
- OI中常犯的傻逼错误总结
OI中常犯的傻逼错误总结 问题 解决方案 文件名出错,包括文件夹,程序文件名,输入输出文件名 复制pdf的名字 没有去掉调试信息 调试时在后面加个显眼的标记 数组开小,超过定义大小,maxn/ ...
- 图解Raft之日志复制
日志复制可以说是Raft集群的核心之一,保证了Raft数据的一致性,下面通过几张图片介绍Raft集群中日志复制的逻辑与流程: 在一个Raft集群中只有Leader节点能够接受客户端的请求,由Leade ...