Azkaban学习之路 (三)Azkaban的使用
界面介绍
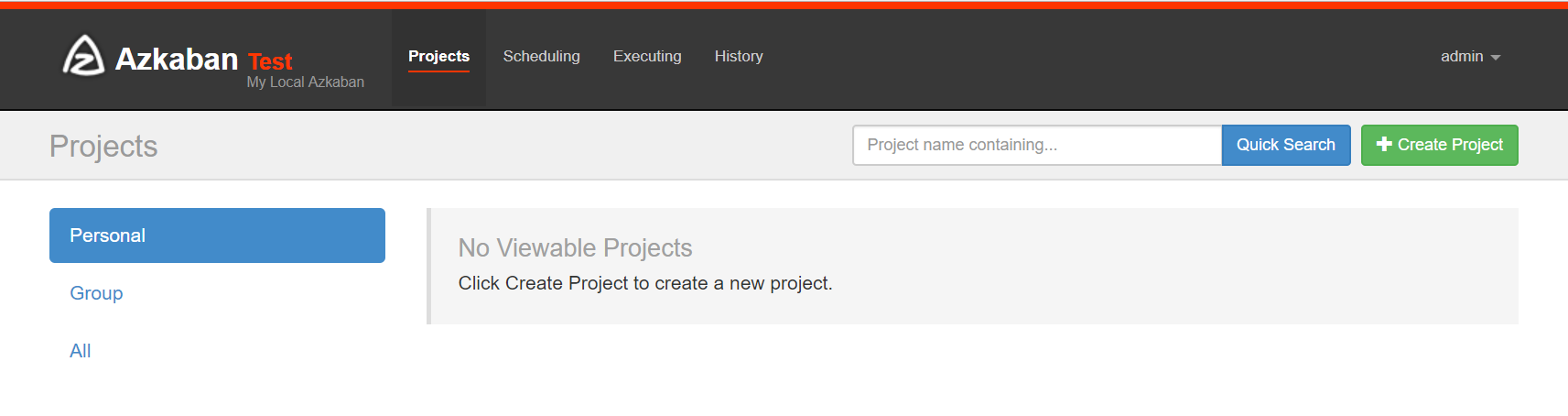
首页有四个菜单
- projects:最重要的部分,创建一个工程,所有flows将在工程中运行。
- scheduling:显示定时任务
- executing:显示当前运行的任务
- history:显示历史运行任务
介绍projects部分
概念介绍
创建工程:创建之前我们先了解下之间的关系,一个工程包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是简单的linux命令,可是java程序,也可以是复杂的shell脚本,当然,如果你安装相关插件,也可以运行插件。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。
1、Command 类型单一 job 示例
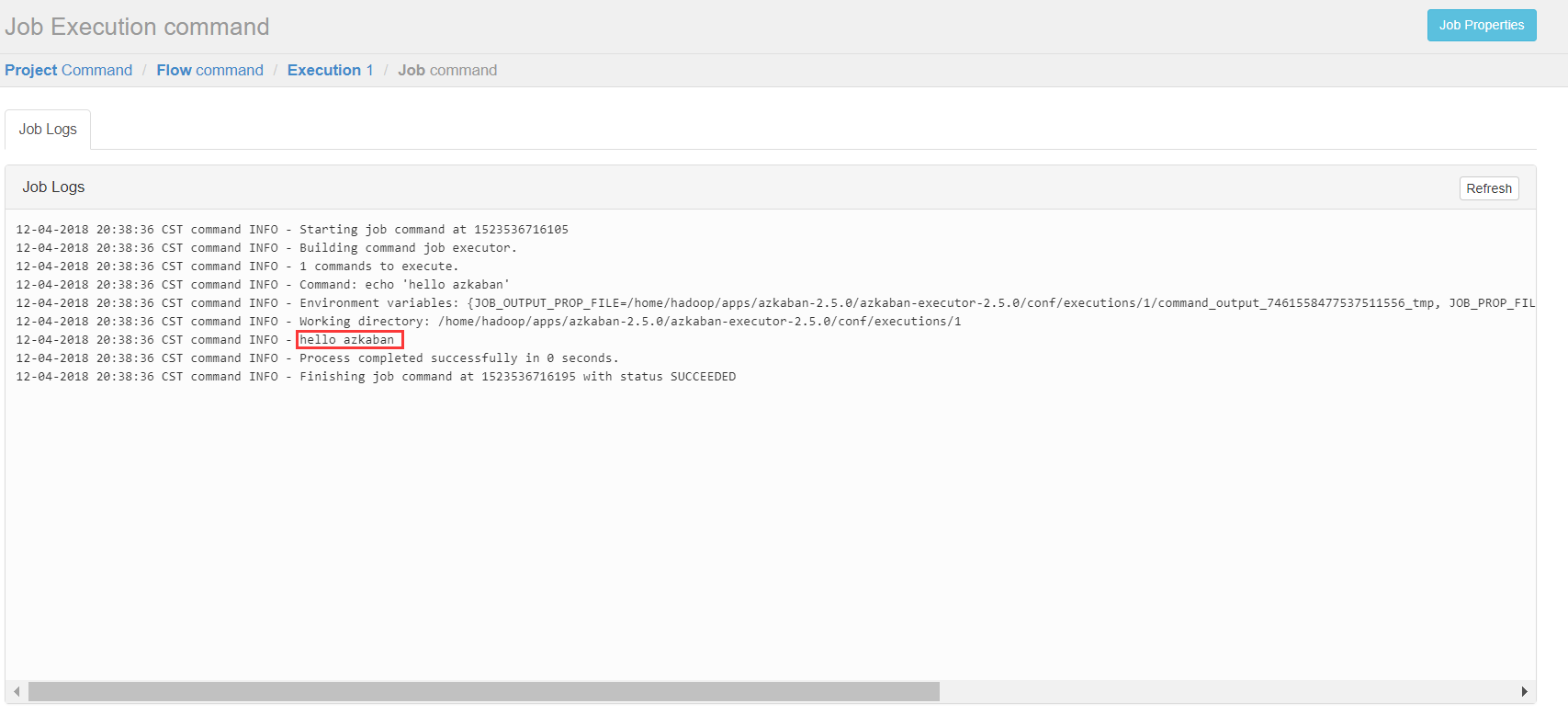
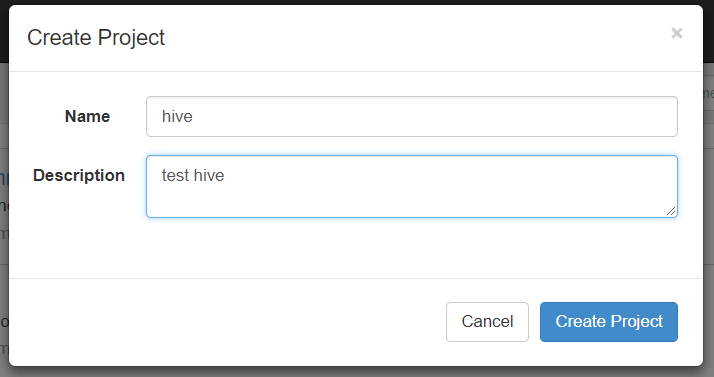
(1)首先创建一个工程,填写名称和描述
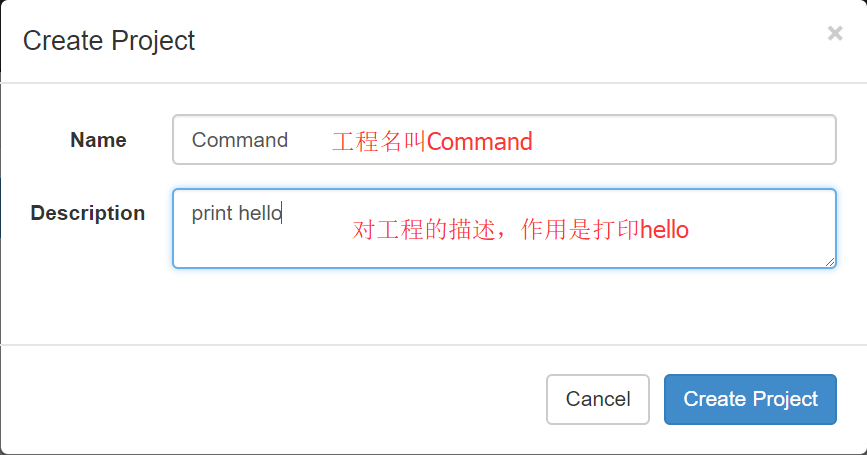
(2)点击创建之后
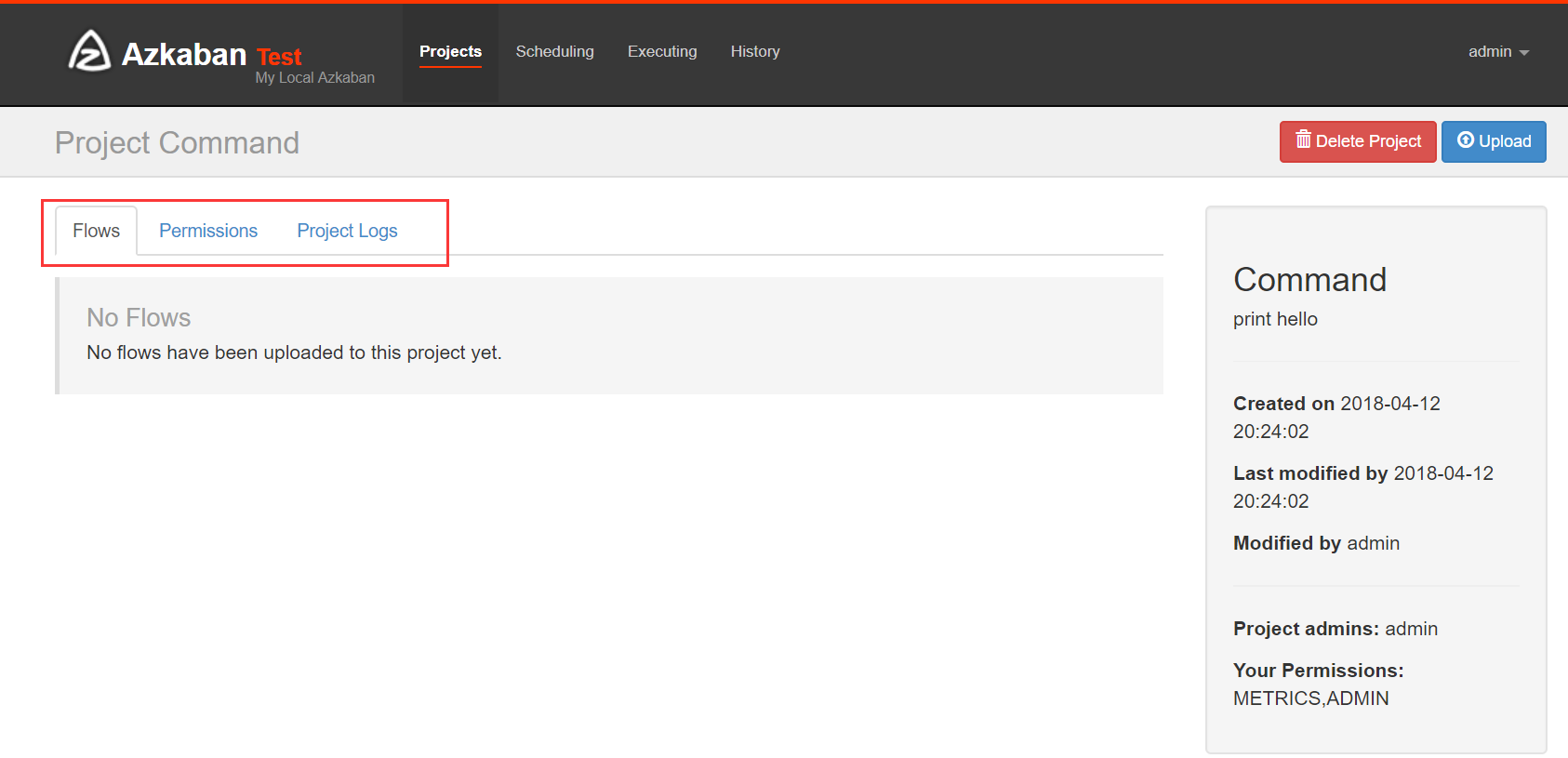
Flows:工作流程,有多个job组成
Permissions:权限管理
Project Logs:工程日志
(3)job的创建
创建job很简单,只要创建一个以.job结尾的文本文件就行了,例如我们创建一个工作,用来打印hello,名字叫做command.job
#command.job
type=command
command=echo 'hello'
一个工程不可能只有一个job,我们现在创建多个依赖job,这也是采用azkaban的首要目的。
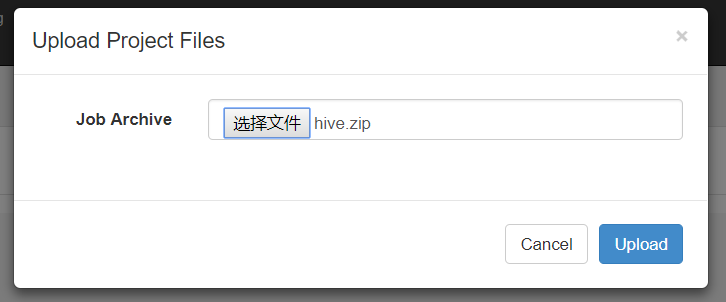
(4)将 job 资源文件打包
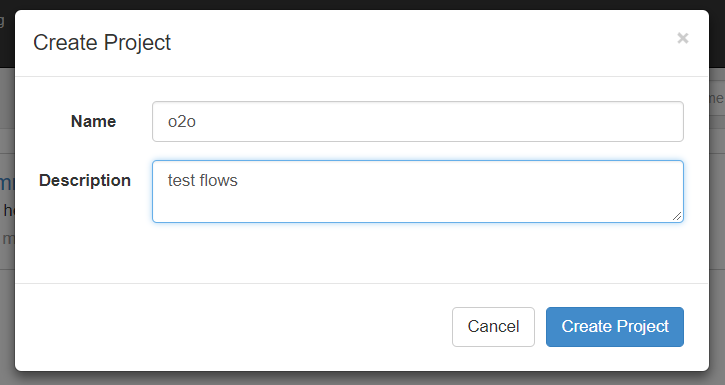
注意:只能是zip格式
(5)通过 azkaban web 管理平台创建 project 并上传压缩包
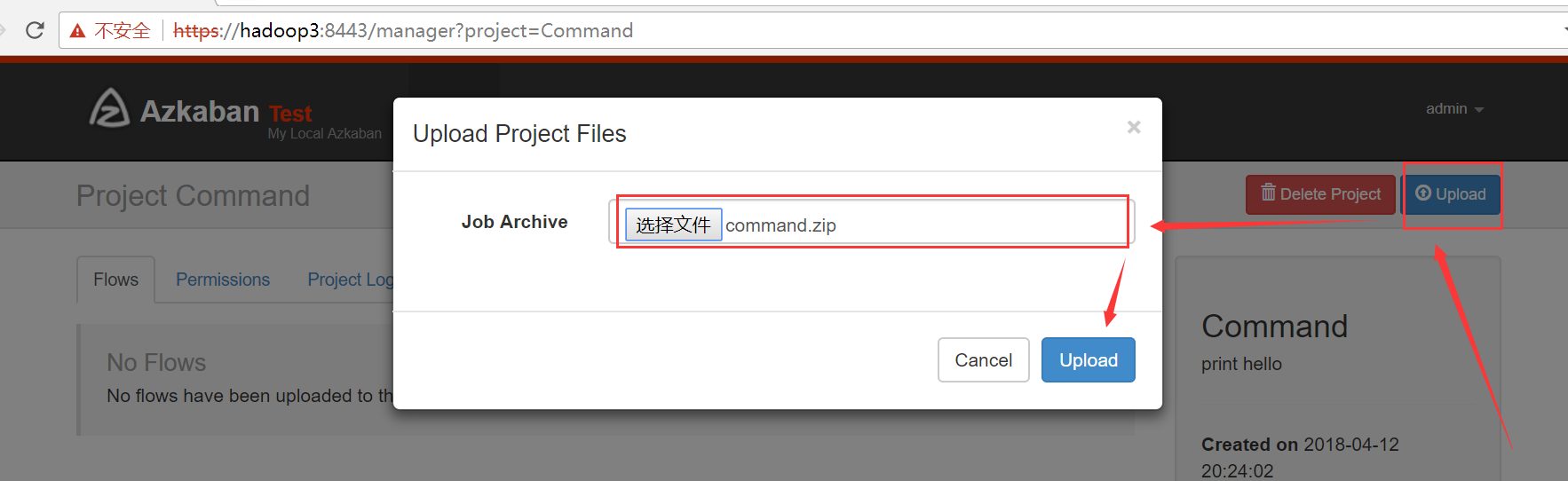
2、Command 类型多 job 工作流 flow
(1)创建项目
我们说过多个jobs和它们的依赖组成flow。怎么创建依赖,只要指定dependencies参数就行了。比如导入hive前,需要进行数据清洗,数据清洗前需要上传,上传之前需要从ftp获取日志。
定义5个job:
1、o2o_2_hive.job:将清洗完的数据入hive库
2、o2o_clean_data.job:调用mr清洗hdfs数据
3、o2o_up_2_hdfs.job:将文件上传至hdfs
4、o2o_get_file_ftp1.job:从ftp1获取日志
5、o2o_get_file_fip2.job:从ftp2获取日志
依赖关系:
3依赖4和5,2依赖3,1依赖2,4和5没有依赖关系。
o2o_2_hive.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
command=sh /job/o2o_2_hive.sh
dependencies=o2o_clean_data
o2o_clean_data.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
command=sh /job/o2o_clean_data.sh
dependencies=o2o_up_2_hdfs
o2o_up_2_hdfs.job
type=command
#需要配置好hadoop命令,建议编写到shell中,可以后期维护
command=hadoop fs -put /data/*
#多个依赖用逗号隔开
dependencies=o2o_get_file_ftp1,o2o_get_file_ftp2
o2o_get_file_ftp1.job
type=command
command=wget "ftp://file1" -O /data/file1
o2o_get_file_ftp2.job
type=command
command=wget "ftp:file2" -O /data/file2
可以运行unix命令,也可以运行python脚本(强烈推荐)。将上述job打成zip包。
ps:为了测试流程,我将上述command都改为echo +相应命令





(2)上传
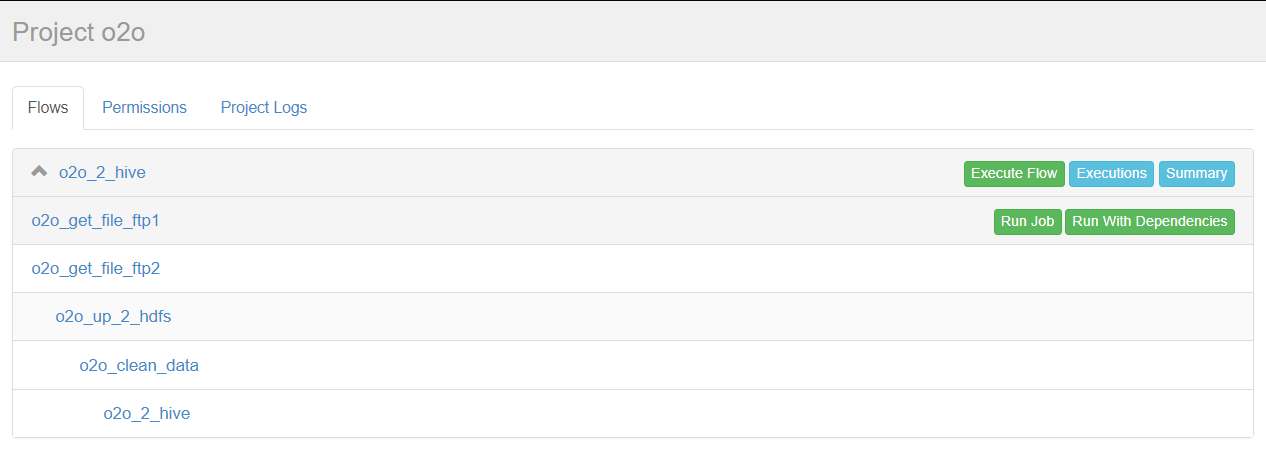
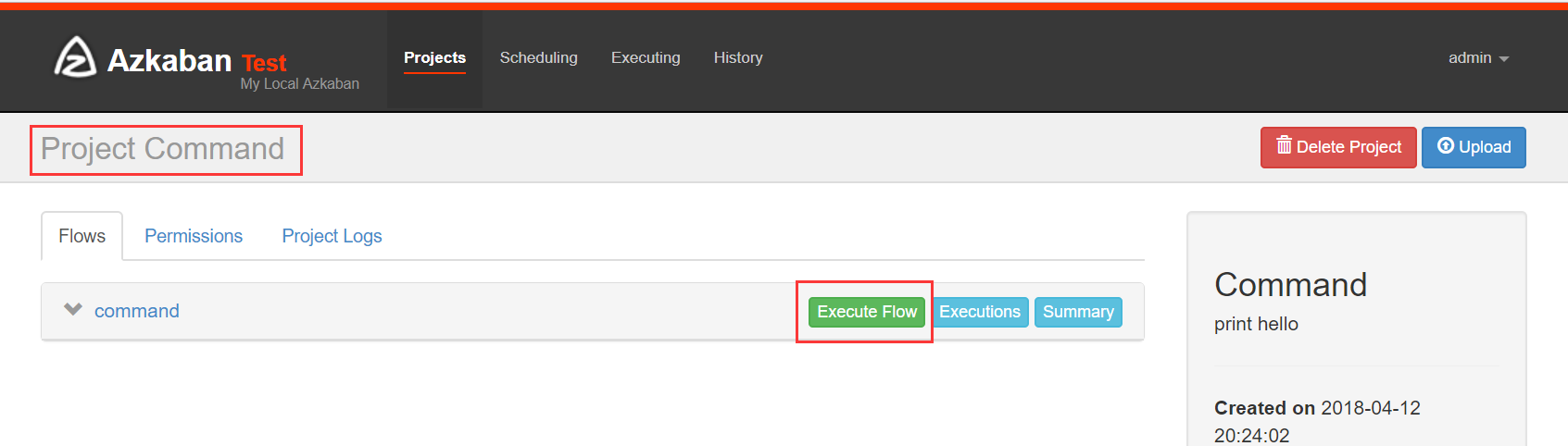
点击o2o_2_hive进入流程,azkaban流程名称以最后一个没有依赖的job定义的。

右上方是配置执行当前流程或者执行定时流程。
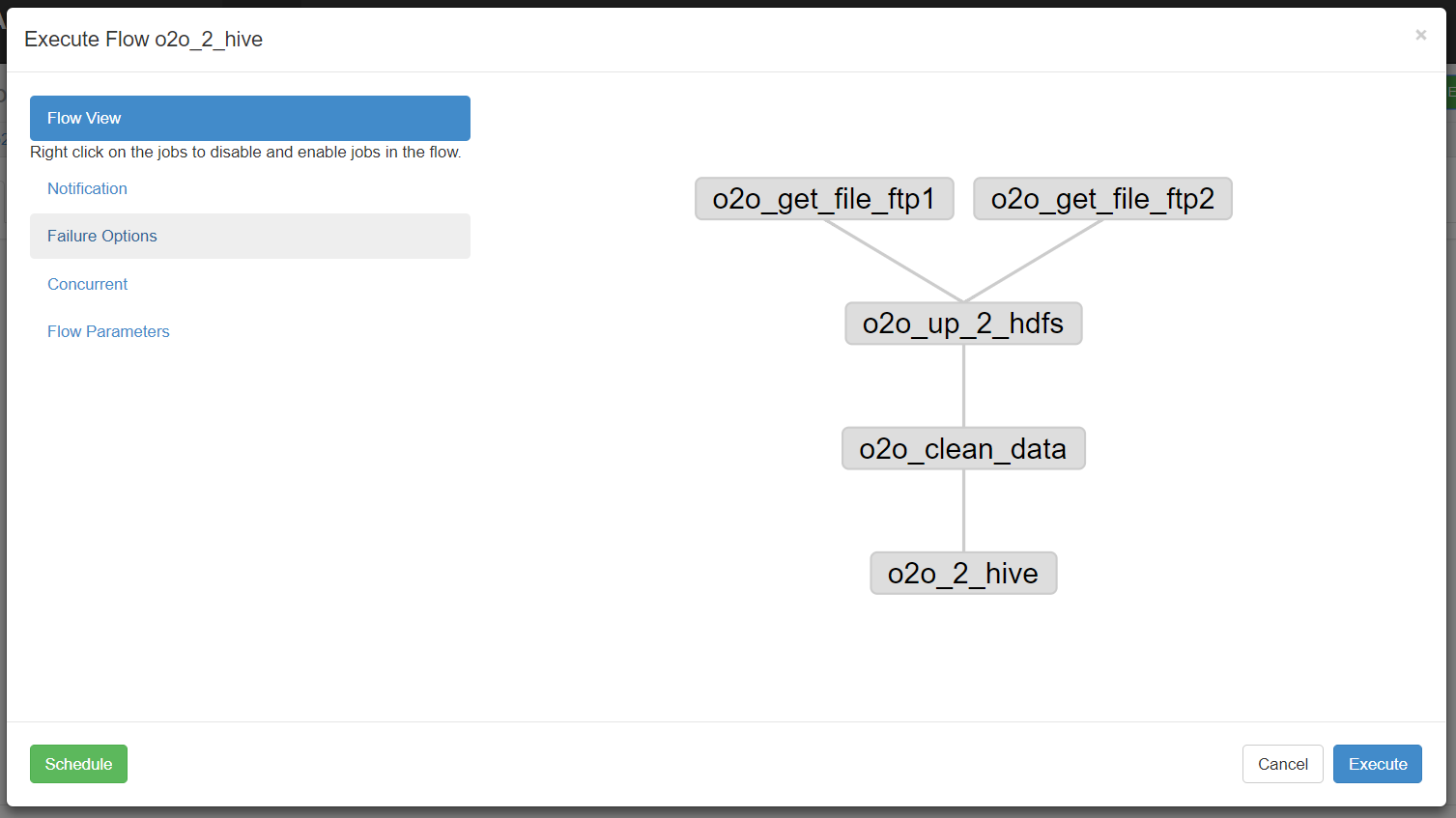
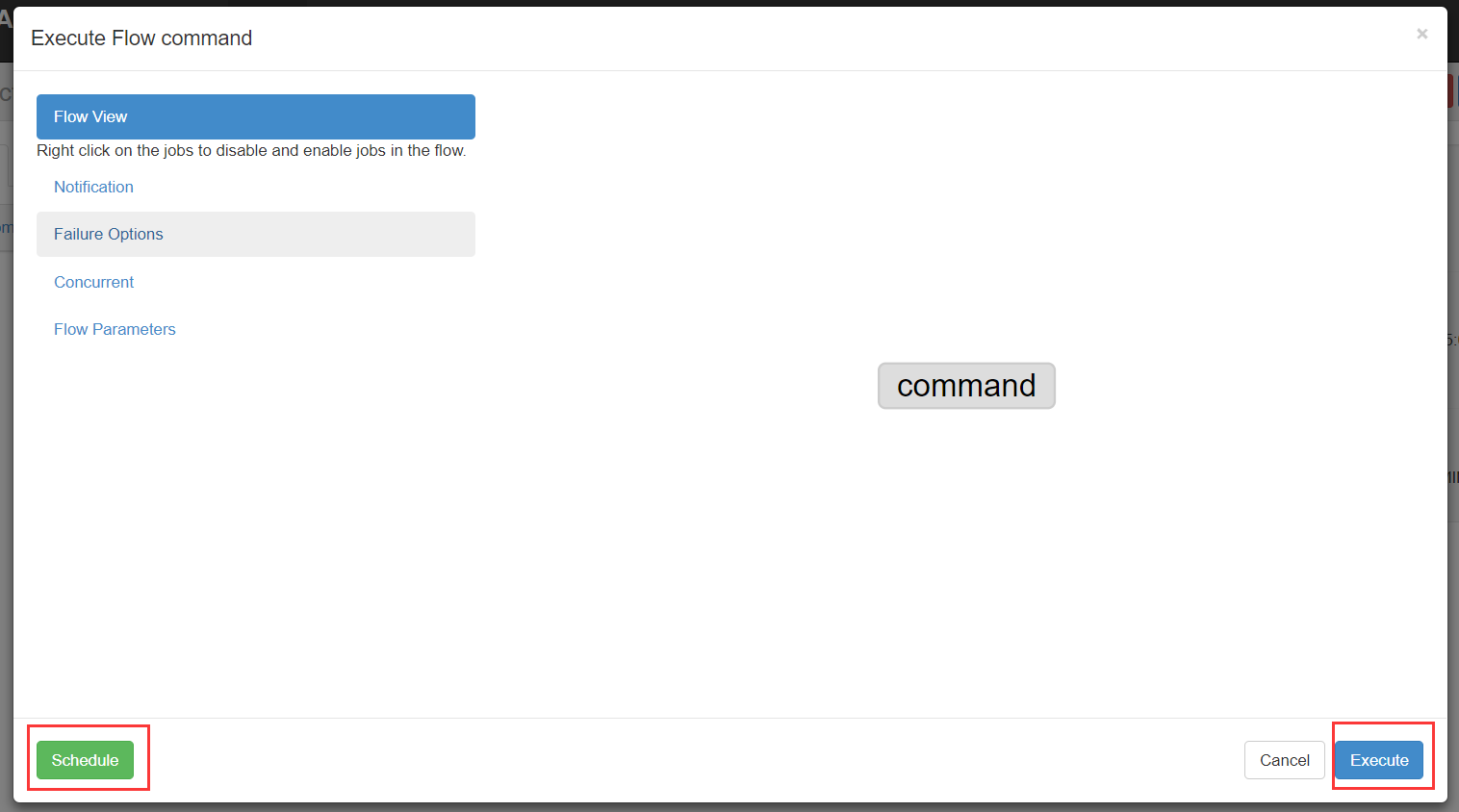
说明
Flow view:流程视图。可以禁用,启用某些job
Notification:定义任务成功或者失败是否发送邮件
Failure Options:定义一个job失败,剩下的job怎么执行
Concurrent:并行任务执行设置
Flow Parametters:参数设置。
(3)执行一次
设置好上述参数,点击execute。
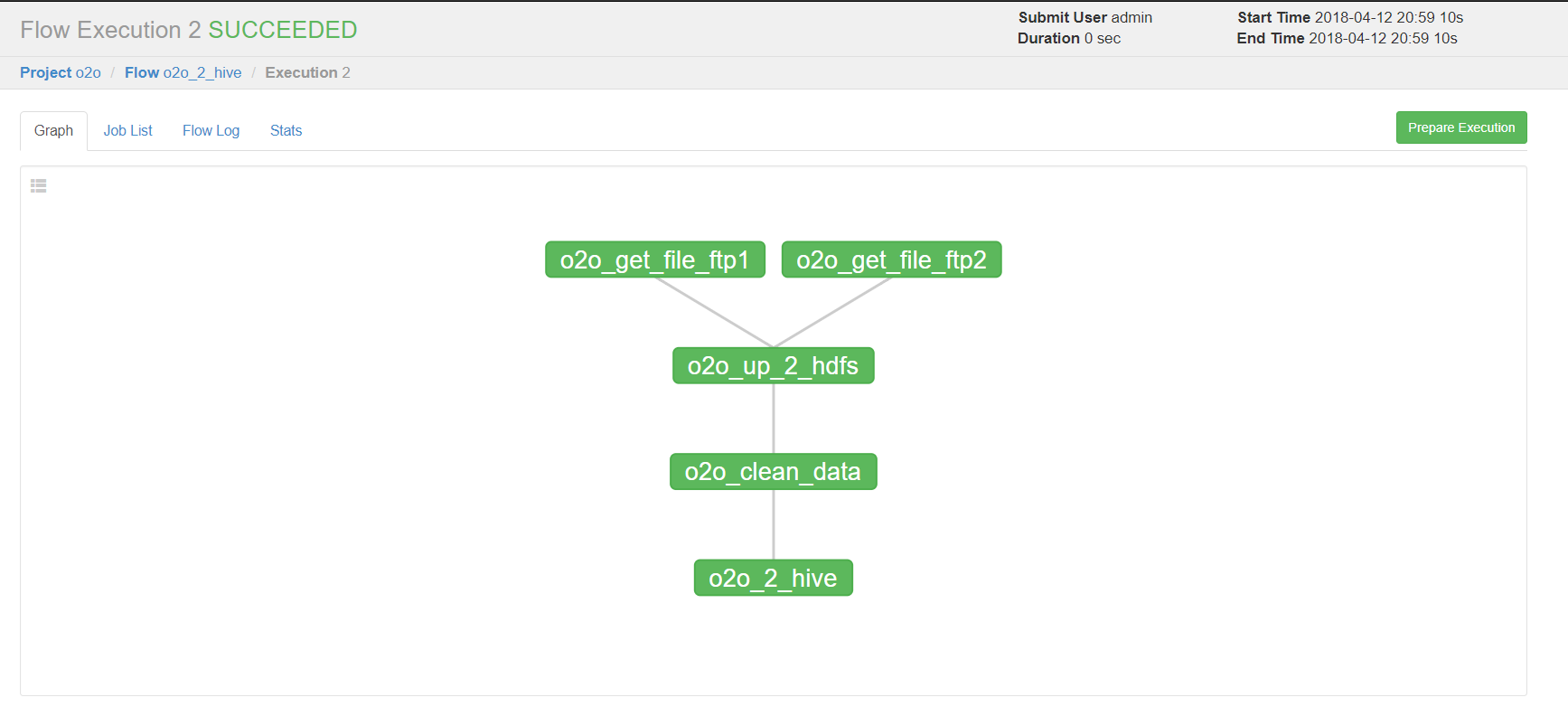
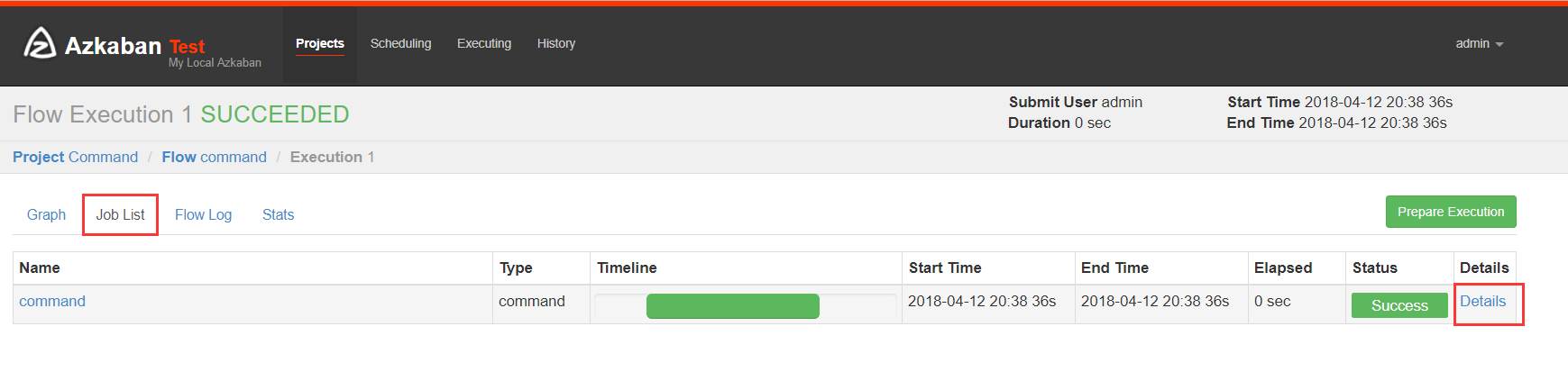
绿色代表成功,蓝色是运行,红色是失败。可以查看job运行时间,依赖和日志,点击details可以查看各个job运行情况。
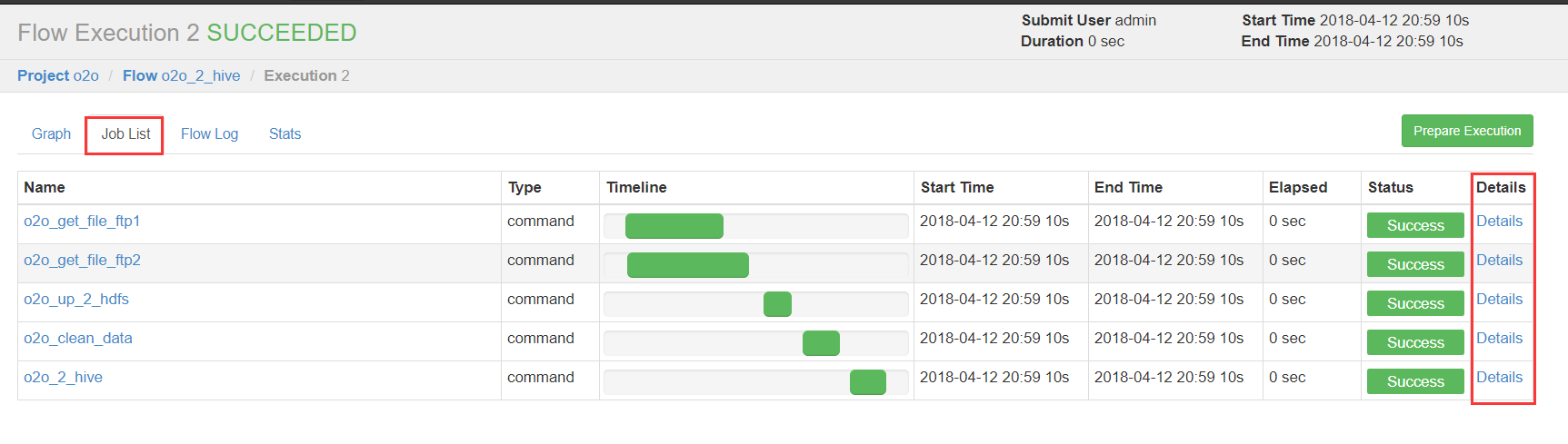
(4)执行定时任务
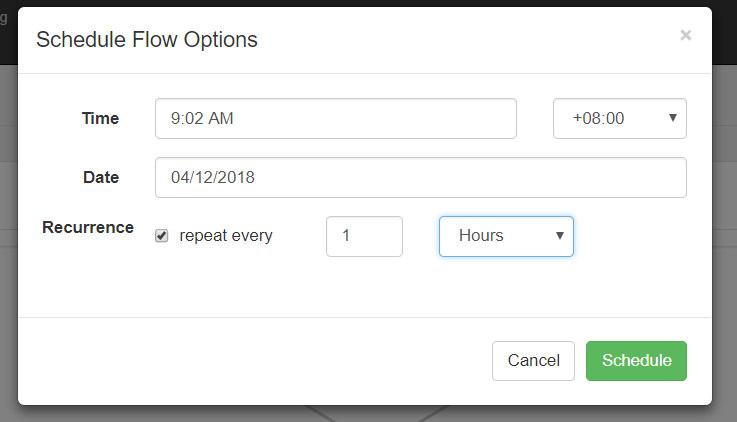
这时候注意到cst了吧,之前需要将配置中时区改为Asia/shanghai。
可以选择"天/时/分/月/周"等执行频率。

可以查看下次执行时间。
3、操作 MapReduce 任务
(1)创建 job 描述文件
mapreduce_wordcount.job
# mapreduce_wordcount.job
type=command
dependencies=mapreduce_pi
command=/home/hadoop/apps/hadoop-2.7.5/bin/hadoop jar /home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /wordcount/input /wordcount/output_azkaban
mapreduce_pi.job
# mapreduce_pi.job
type=command
command=/home/hadoop/apps/hadoop-2.7.5/bin/hadoop jar /home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar pi 5 5
(2)创建 project 并上传 zip 包

(3)启动执行

4、Hive 脚本任务
(1) 创建 job 描述文件和 hive 脚本
Hive 脚本如下
test.sql
create database if not exists azkaban;
use azkaban;
drop table if exists student;
create table student(id int,name string,sex string,age int,deparment string) row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/student.txt' into table student;
create table student_copy as select * from student;
insert overwrite directory '/aztest/hiveoutput' select count(1) from student_copy;
!hdfs dfs -cat /aztest/hiveoutput/000000_0;
drop database azkaban cascade;
Job 描述文件:
hivef.job
# hivef.job
type=command
command=/home/hadoop/apps/apache-hive-2.3.3-bin/bin/hive -f 'test.sql'
(2)将所有 job 资源文件打到一个 zip 包中
(3)在 azkaban 的 web 管理界面创建工程并上传 zip 包
5、启动 job
Azkaban学习之路 (三)Azkaban的使用的更多相关文章
- 学习之路三十九:新手学习 - Windows API
来到了新公司,一开始就要做个程序去获取另外一个程序里的数据,哇,挑战性很大. 经过两周的学习,终于搞定,主要还是对Windows API有了更多的了解. 文中所有的消息常量,API,结构体都整理出来了 ...
- Azkaban学习之路 (二)Azkaban的安装
安装过程 1.软件介绍 Azkaban Web 服务器:azkaban-web-server-2.5.0.tar.gz Azkaban Excutor 执行服务器:azkaban-executor-s ...
- Redis——学习之路三(初识redis config配置)
我们先看看config 默认情况下系统是怎么配置的.在命令行中输入 config get *(如图) 默认情况下有61配置信息,每一个命令占两行,第一行为配置名称信息,第二行为配置的具体信息. ...
- Azkaban学习之路(三)—— Azkaban Flow 1.0 的使用
一.简介 Azkaban主要通过界面上传配置文件来进行任务的调度.它有两个重要的概念: Job: 你需要执行的调度任务: Flow:一个获取多个Job及它们之间的依赖关系所组成的图表叫做Flow. 目 ...
- Azkaban学习之路 (一)Azkaban的基础介绍
一.为什么需要工作流调度器 1.一个完整的数据分析系统通常都是由大量任务单元组成: shell 脚本程序,java 程序,mapreduce 程序.hive 脚本等 2.各任务单元之间存在时间先后及前 ...
- Azkaban学习之路(四)—— Azkaban Flow 2.0的使用
一.Flow 2.0 简介 1.1 Flow 2.0 的产生 Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用Flow 2.0,因为Flow 1.0会在将 ...
- Azkaban学习之路(二)—— Azkaban 3.x 编译及部署
一.Azkaban 源码编译 1.1 下载并解压 Azkaban 在3.0版本之后就不提供对应的安装包,需要自己下载源码进行编译. 下载所需版本的源码,Azkaban的源码托管在GitHub上,地址为 ...
- Azkaban学习之路(一)—— Azkaban 简介
一.Azkaban 介绍 1.1 背景 一个完整的大数据分析系统,必然由很多任务单元(如数据收集.数据清洗.数据存储.数据分析等)组成,所有的任务单元及其之间的依赖关系组成了复杂的工作流.复杂的工作流 ...
- zigbee学习之路(三):按键的控制
一.前言 通过前一次的实验,相信大家都已经对cc2530程序的编写有了一定的认识,这次我们来操作和实验的是cc2530上的按键模块. 二.原理分析 我们先来看一下按键的原理图: 根据原理图我们可以得出 ...
随机推荐
- CoreException: Could not get the value for parameter compilerId for plugin execution default-compile: PluginResolutionException: Plugin org.apache.maven.plugins:maven-compiler-plugin:3.1
今天遇到一个奇怪的问题, 之前写好的代码, 更换环境后, 重新搭建的nexus, maven私服总是报错, 各种clean/update都不管用 原来是没写版本号, 后来加上3.1版本, 还是报错, ...
- nodejs编译遇到的问题
src\node_contextify.cc:631: Assertion 'args[1]->IsString()' failed. node 10 版本会出现这个问题, 安装natives后 ...
- 使用COOKIE实现登录 VS 使用SESSION实现登录
注:本文使用的代码基于PHP,其他语言逻辑同理. 一:使用COOKIE实现登录验证 使用cookie实现登录的方式,主要通过一些单向的加密信息进行验证.比如admin用户登录了之后,服务端生成一个co ...
- Ubuntu ARM更改为国内源
关键词:ubuntu arm ubuntu-ports 国内源 镜像 阿里源 apt apt-get install update 0%working 速度慢 rk3399 开发板 ...
- 如何安装并且使用jmeter进行简单的性能测试
Jmeter 介绍 Jmeter 是一款使用Java开发的,开源免费的,测试工具, 主要用来做功能测试和性能测试(压力测试/负载测试). 而且用Jmeter 来测试 Restful API, 非常 ...
- CentOS 7 安装配置 OpenVPN 客户端
安装 epel yum 源: $ rpm -ivh http://mirrors.sohu.com/fedora-epel/6/x86_64/epel-release-6-8.noarch.rpm $ ...
- [Swift]LeetCode524. 通过删除字母匹配到字典里最长单词 | Longest Word in Dictionary through Deleting
Given a string and a string dictionary, find the longest string in the dictionary that can be formed ...
- [Swift]LeetCode851. 喧闹和富有 | Loud and Rich
In a group of N people (labelled 0, 1, 2, ..., N-1), each person has different amounts of money, and ...
- grep的正则表达式结合的几个典型应用
一 几个特殊的字符: ^ :只匹配行首 如^a 匹配以a开头的行abc,a2e,a12,aaa,...... example: grep "^a" //列出所有以a开头的行 $ ...
- 花点时间顺顺Git(下)
### 进入正文前插个楼,因为vim的操作下面会频繁用到 vim的操作 1.输入i进入插入模式,对上一条commit信息的内容进行修改 2.按下ESC键,退出编辑模式,切换到命令模式. 3.保存修改并 ...