scrapy递归解析和post请求
递归解析
递归爬取解析多页页面数据
每一个页面对应一个url,则scrapy工程需要对每一个页码对应的url依次发起请求,然后通过对应的解析方法进行作者和段子内容的解析。
实现方案:
1.将每一个页码对应的url存放到爬虫文件的起始url列表(start_urls)中。(不推荐)
2.使用Request方法手动发起请求。(推荐)
import scrapy
from choutiPro.items import ChoutiproItem class ChoutiSpider(scrapy.Spider):
name = 'chouti'
# allowed_domains = ['www.xxx.com']
# 通用url的封装
url = 'https://dig.chouti.com/r/scoff/hot/%d'
pageNum = start_urls = ['https://dig.chouti.com/r/scoff/hot/1'] def parse(self, response):
div_list = response.xpath('//div[@id="content-list"]/div')
for div in div_list:
title = div.xpath('./div[3]/div[1]/a/text()').extract_first()
author = div.xpath('./div[3]/div[2]/a[4]/b/text()').extract_first() # item = ChoutiproItem()
item['title'] = title
item['author'] = author yield item if self.pageNum < : # 页码的一个范围
# 封装集成了一个新的页码的url
self.pageNum +=
new_url = format(self.url % self.pageNum)
# 手动的请求发送:callback表示的指定的解析方法
yield scrapy.Request(url=new_url, callback=self.parse) # 在scrapy框架中yield的使用场景:
# .yield item:向管道提交item
# .yield scrapy.Request():进行手动请求发送
items
import scrapy class ChoutiproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
pipelines
class ChoutiproPipeline(object):
def process_item(self, item, spider):
print(f"{item['title']}:{item['author']}")
# 持久化储存,测试没写
return item
settings
BOT_NAME = 'choutiPro'
# 使用UA
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
SPIDER_MODULES = ['choutiPro.spiders']
NEWSPIDER_MODULE = 'choutiPro.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
# 关闭root协议
ROBOTSTXT_OBEY = False # 开启管道
ITEM_PIPELINES = {
'choutiPro.pipelines.ChoutiproPipeline': ,
}
Request和Response参数

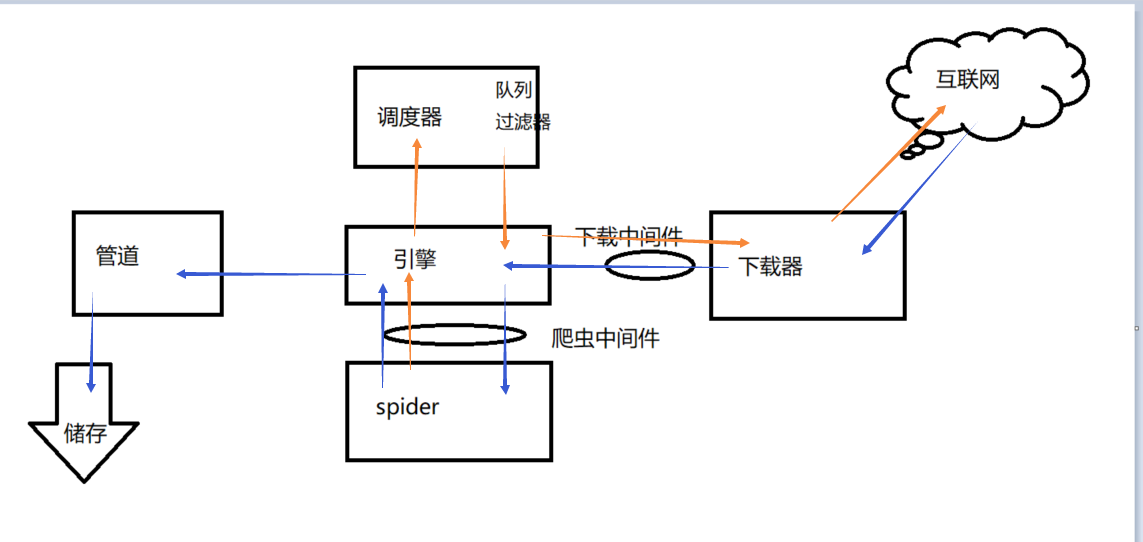
五大核心组件工作流程

- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下图是一个请求再返回来的流程
红色是发送请求
蓝色是返回的流程
post请求
其实是因为爬虫文件中的爬虫类继承到了Spider父类中的start_requests(self)这个方法,该方法就可以对start_urls列表中的url发起请求:
# 原始作用:将起始url料表中url进行GET请求
# def start_requests(self): # 模拟get请求的简化流程
# for url in self.start_urls:
# yield scrapy.Request(url=url,callback=self.parse)
实现post请求其实就是重写父类的start_requests
# 重写 父类的 start_requests,让其进行POST请求
def start_requests(self):
data = {
'kw': 'dog'
}
for url in self.start_urls:
# scrapy.FormRequest:指 POST 请求
# callback=self.parse 指回调函数
# formdata=data 指post请求发送的数据
yield scrapy.FormRequest(url=url, callback=self.parse, formdata=data)
列如百度翻译我就可以这样发送post请求
# -*- coding: utf- -*-
import scrapy class PostSpider(scrapy.Spider):
name = 'post'
allowed_domains = ['www.xxx.com']
start_urls = ['https://fanyi.baidu.com/sug'] # 原始作用:将起始url料表中url进行GET请求
# def start_requests(self): # 模拟get请求的简化流程
# for url in self.start_urls:
# yield scrapy.Request(url=url,callback=self.parse) # 重写 父类的 start_requests,让其进行POST请求
def start_requests(self):
data = {
'kw': 'dog'
}
for url in self.start_urls:
# scrapy.FormRequest:指 POST 请求
# callback=self.parse 指回调函数
# formdata=data 指post请求发送的数据
yield scrapy.FormRequest(url=url, callback=self.parse, formdata=data) def parse(self, response):
# print(response.bady)
print(response.text)
baidu—post
访问人人个人首页
# -*- coding: utf- -*-
import scrapy class LoginSpider(scrapy.Spider):
name = 'login'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=201873958471'] def start_requests(self):
formdata = {
'email': '',
'icode': '',
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '',
'captcha_type': 'web_login',
'password': '7b456e6c3eb6615b2e122a2942ef3845da1f91e3de075179079a3b84952508e4',
'rkey': '44fd96c219c593f3c9612360c80310a3',
'f': 'https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Dm7m_NSUp5Ri_ZrK5eNIpn_dMs48UAcvT-N_kmysWgYW%26wd%3D%26eqid%3Dba95daf5000065ce000000035b120219',
}
for url in self.start_urls:
yield scrapy.FormRequest(url=url, formdata=formdata, callback=self.parse) def parse(self, response):
url = 'http://www.renren.com/960481378/profile' yield scrapy.Request(url=url, callback=self.personalPage) def personalPage(self, response):
page_text = response.text
print(response)
人人个人首页
scrapy递归解析和post请求的更多相关文章
- 12.scrapy框架之递归解析和post请求
今日概要 递归爬取解析多页页面数据 scrapy核心组件工作流程 scrapy的post请求发送 今日详情 1.递归爬取解析多页页面数据 - 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久 ...
- scrapy框架之递归解析和post请求
递归爬取解析多页页面数据 scrapy核心组件工作流程 scrapy的post请求发送 1.递归爬取解析多页页面数据 - 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久化存储 - 需求分析 ...
- 爬虫开发9.scrapy框架之递归解析和post请求
今日概要 递归爬取解析多页页面数据 scrapy核心组件工作流程 scrapy的post请求发送 今日详情 1.递归爬取解析多页页面数据 - 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久 ...
- 11 Scrapy框架之递归解析和post请求
一.递归爬取解析多页页面数据 - 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久化存储 - 需求分析:每一个页面对应一个url,则scrapy工程需要对每一个页码对应的url依次发起请求, ...
- 11-scrapy(递归解析,post请求,日志等级,请求传参)
一.递归解析: 需求:将投诉_阳光热线问政平台中的投诉标题和状态网友以及时间爬取下来永久储存在数据库中 url:http://wz.sun0769.com/index.php/question/que ...
- DNS(一)之禁用权威域名服务器递归解析
DNS dns是互联网中最核心的带层级的分布式系统,负责把域名解析成ip,把IP解析出域名,以及宣告邮件路由信息等等,使得使用域名访问网站,收发邮件成了可能. bind(berkeley Intern ...
- DNS递归解析和迭代解析
DNS解析流程分为递归查询和迭代查询,递归查询是以本地名称服务器为中心查询, 递归查询是默认方式,迭代查询是以DNS客户端,也就是客户机器为中心查询.其实DNS客户端和本地名称服务器是递归,而本地名称 ...
- Nginx重要结构request_t解析之http请求的获取
请在文章页面明显位置给出原文连接,否则保留追究法律责任的权利. 本文主要参考为<深入理解nginx模块开发与架构解析>一书,处理用户请求部分,是一篇包含作者理解的读书笔记.欢迎指正,讨论. ...
- Xml学习笔记(3)利用递归解析Xml文档添加到TreeView中
利用递归解析Xml文档添加到TreeView中 private void Form1_Load(object sender, EventArgs e) { XmlDocument doc = new ...
随机推荐
- matplotlib库的简单应用
matplotlib库 import matplotlib.pyplot as plt import matplotlib matplotlib.rcParams['font.family']='Si ...
- SQL Server TVPs 批量插入数据
在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Insert不仅效率低,而且会导致SQL一系统性能问题.下面介绍SQL Server支持的两种批量 ...
- 毕业设计——Django邮件发送功能实现及问题记录
django发送邮件:send_mail()&send_mass_mail() 自强学堂 刘江的博客 HTTPS,TLS和SSL django发送邮件及其相关问题 步骤 : 0. 登录作为发送 ...
- Ubuntu通过ADB连接手机
参考 ubuntu14.04 下android studio连接手机 安装 adb $sudo apt install adb $sudo lsusb 得到ID为 Bus Device : ID 12 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- POI操作excle
将根目录下的poi-3.6-20091214.jar和Lib目录下三个通用包 commons-logging-1.1.jar junit-3.8.1.jar log4j-1.2.13.jar拷贝到项目 ...
- 第十四节,OpenCV学习(三)图像的阈值分割
图像的阈值处理 图像的阈值分割:图像的二值化(Binarization) 阈值分割法的特点是:适用于目标与背景灰度有较强对比的情况,重要的是背景或物体的灰度比较单一,而且总可以得到封闭且连通区域的边界 ...
- CentOS搭建GIT服务器
安装git # 请确保您切换到了root账户 $ su root $ yum install -y git # 验证是否安装成功 $ git --version # 输出如下内容表示成功: git v ...
- ICMP shell
场景 反向shell的场景下使用 原理 ICMP作为获取反向shell的通道 实践 运行 run.sh报错,可能是因为用的Parrot.改一下就可以了 ifconfig | grep 'inet '| ...
- bently addin 二次开发学习
元素结构: 一些基本元素的添加与绘制: class CreateElement { public static void LineAndLineString() { Application app = ...