scrapy递归解析和post请求
递归解析
递归爬取解析多页页面数据
每一个页面对应一个url,则scrapy工程需要对每一个页码对应的url依次发起请求,然后通过对应的解析方法进行作者和段子内容的解析。
实现方案:
1.将每一个页码对应的url存放到爬虫文件的起始url列表(start_urls)中。(不推荐)
2.使用Request方法手动发起请求。(推荐)
import scrapy
from choutiPro.items import ChoutiproItem class ChoutiSpider(scrapy.Spider):
name = 'chouti'
# allowed_domains = ['www.xxx.com']
# 通用url的封装
url = 'https://dig.chouti.com/r/scoff/hot/%d'
pageNum = start_urls = ['https://dig.chouti.com/r/scoff/hot/1'] def parse(self, response):
div_list = response.xpath('//div[@id="content-list"]/div')
for div in div_list:
title = div.xpath('./div[3]/div[1]/a/text()').extract_first()
author = div.xpath('./div[3]/div[2]/a[4]/b/text()').extract_first() # item = ChoutiproItem()
item['title'] = title
item['author'] = author yield item if self.pageNum < : # 页码的一个范围
# 封装集成了一个新的页码的url
self.pageNum +=
new_url = format(self.url % self.pageNum)
# 手动的请求发送:callback表示的指定的解析方法
yield scrapy.Request(url=new_url, callback=self.parse) # 在scrapy框架中yield的使用场景:
# .yield item:向管道提交item
# .yield scrapy.Request():进行手动请求发送
items
import scrapy class ChoutiproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
pipelines
class ChoutiproPipeline(object):
def process_item(self, item, spider):
print(f"{item['title']}:{item['author']}")
# 持久化储存,测试没写
return item
settings
BOT_NAME = 'choutiPro'
# 使用UA
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
SPIDER_MODULES = ['choutiPro.spiders']
NEWSPIDER_MODULE = 'choutiPro.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
# 关闭root协议
ROBOTSTXT_OBEY = False # 开启管道
ITEM_PIPELINES = {
'choutiPro.pipelines.ChoutiproPipeline': ,
}
Request和Response参数

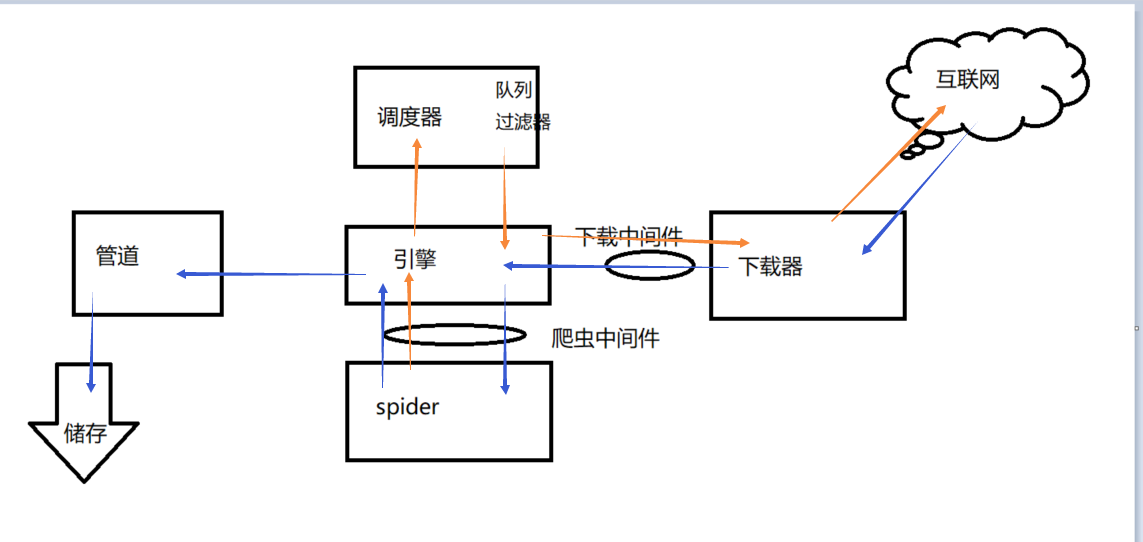
五大核心组件工作流程

- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下图是一个请求再返回来的流程
红色是发送请求
蓝色是返回的流程
post请求
其实是因为爬虫文件中的爬虫类继承到了Spider父类中的start_requests(self)这个方法,该方法就可以对start_urls列表中的url发起请求:
# 原始作用:将起始url料表中url进行GET请求
# def start_requests(self): # 模拟get请求的简化流程
# for url in self.start_urls:
# yield scrapy.Request(url=url,callback=self.parse)
实现post请求其实就是重写父类的start_requests
# 重写 父类的 start_requests,让其进行POST请求
def start_requests(self):
data = {
'kw': 'dog'
}
for url in self.start_urls:
# scrapy.FormRequest:指 POST 请求
# callback=self.parse 指回调函数
# formdata=data 指post请求发送的数据
yield scrapy.FormRequest(url=url, callback=self.parse, formdata=data)
列如百度翻译我就可以这样发送post请求
# -*- coding: utf- -*-
import scrapy class PostSpider(scrapy.Spider):
name = 'post'
allowed_domains = ['www.xxx.com']
start_urls = ['https://fanyi.baidu.com/sug'] # 原始作用:将起始url料表中url进行GET请求
# def start_requests(self): # 模拟get请求的简化流程
# for url in self.start_urls:
# yield scrapy.Request(url=url,callback=self.parse) # 重写 父类的 start_requests,让其进行POST请求
def start_requests(self):
data = {
'kw': 'dog'
}
for url in self.start_urls:
# scrapy.FormRequest:指 POST 请求
# callback=self.parse 指回调函数
# formdata=data 指post请求发送的数据
yield scrapy.FormRequest(url=url, callback=self.parse, formdata=data) def parse(self, response):
# print(response.bady)
print(response.text)
baidu—post
访问人人个人首页
# -*- coding: utf- -*-
import scrapy class LoginSpider(scrapy.Spider):
name = 'login'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=201873958471'] def start_requests(self):
formdata = {
'email': '',
'icode': '',
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '',
'captcha_type': 'web_login',
'password': '7b456e6c3eb6615b2e122a2942ef3845da1f91e3de075179079a3b84952508e4',
'rkey': '44fd96c219c593f3c9612360c80310a3',
'f': 'https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Dm7m_NSUp5Ri_ZrK5eNIpn_dMs48UAcvT-N_kmysWgYW%26wd%3D%26eqid%3Dba95daf5000065ce000000035b120219',
}
for url in self.start_urls:
yield scrapy.FormRequest(url=url, formdata=formdata, callback=self.parse) def parse(self, response):
url = 'http://www.renren.com/960481378/profile' yield scrapy.Request(url=url, callback=self.personalPage) def personalPage(self, response):
page_text = response.text
print(response)
人人个人首页
scrapy递归解析和post请求的更多相关文章
- 12.scrapy框架之递归解析和post请求
今日概要 递归爬取解析多页页面数据 scrapy核心组件工作流程 scrapy的post请求发送 今日详情 1.递归爬取解析多页页面数据 - 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久 ...
- scrapy框架之递归解析和post请求
递归爬取解析多页页面数据 scrapy核心组件工作流程 scrapy的post请求发送 1.递归爬取解析多页页面数据 - 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久化存储 - 需求分析 ...
- 爬虫开发9.scrapy框架之递归解析和post请求
今日概要 递归爬取解析多页页面数据 scrapy核心组件工作流程 scrapy的post请求发送 今日详情 1.递归爬取解析多页页面数据 - 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久 ...
- 11 Scrapy框架之递归解析和post请求
一.递归爬取解析多页页面数据 - 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久化存储 - 需求分析:每一个页面对应一个url,则scrapy工程需要对每一个页码对应的url依次发起请求, ...
- 11-scrapy(递归解析,post请求,日志等级,请求传参)
一.递归解析: 需求:将投诉_阳光热线问政平台中的投诉标题和状态网友以及时间爬取下来永久储存在数据库中 url:http://wz.sun0769.com/index.php/question/que ...
- DNS(一)之禁用权威域名服务器递归解析
DNS dns是互联网中最核心的带层级的分布式系统,负责把域名解析成ip,把IP解析出域名,以及宣告邮件路由信息等等,使得使用域名访问网站,收发邮件成了可能. bind(berkeley Intern ...
- DNS递归解析和迭代解析
DNS解析流程分为递归查询和迭代查询,递归查询是以本地名称服务器为中心查询, 递归查询是默认方式,迭代查询是以DNS客户端,也就是客户机器为中心查询.其实DNS客户端和本地名称服务器是递归,而本地名称 ...
- Nginx重要结构request_t解析之http请求的获取
请在文章页面明显位置给出原文连接,否则保留追究法律责任的权利. 本文主要参考为<深入理解nginx模块开发与架构解析>一书,处理用户请求部分,是一篇包含作者理解的读书笔记.欢迎指正,讨论. ...
- Xml学习笔记(3)利用递归解析Xml文档添加到TreeView中
利用递归解析Xml文档添加到TreeView中 private void Form1_Load(object sender, EventArgs e) { XmlDocument doc = new ...
随机推荐
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- java常见题目总结
编写多线程程序的几种方法:java5以前可以通过继承Thread类或者实现Runnable接口,重写run方法来定义线程行为:java5以后出现了另一种方式,实现Callable接口,该接口的call ...
- 关于接口(Interface)
接口,其实是指类之间约定的协议,可以包含方法.属性.事件和索引: 接口成员不允许使用访问修饰符号(public.private.protected.internal),所有的接口成员都是公共的. 接口 ...
- python整数与IP地址转换
python整数与IP地址转换 [转] 我们有时会将一个整数与IP地址进行互换,用python代码实现很简单将一个整数如2000000,变为一个IP地址的方式 >>> import ...
- 【尚学堂·Hadoop学习】MapReduce案例1--天气
案例描述 找出每个月气温最高的2天 数据集 -- :: 34c -- :: 38c -- :: 36c -- :: 32c -- :: 37c -- :: 23c -- :: 41c -- :: 27 ...
- vue.js学习系列-第一篇
VUE系列一 简介 vue是一个兴起的前端js库,是一个精简的MVVM.从技术角度讲,Vue.js专注于 MVVM 模型的 ViewModel 层.它通过双向数据绑定把 View 层和 Mode ...
- centos7 搭建jenkins服务器
具体可参考:https://blog.csdn.net/it_lihongmin/article/details/80814384 注意: 1. 修改主目录:默认是/var/lib/jenkins, ...
- Python简单基础小程序
1 九九乘法表 for i in range(9):#从0循环到8 i += 1#等价于 i = i+1 for j in range(i):#从0循环到i j += 1 print(j,'*',i, ...
- Beta答辩总结
组员名单 短学号 姓名 备注 409 后敬甲 组长 301 蔡文斌 315 黄靖茹 423 刘浩 317 黄泽 328 卢泽明 617 葛亮 344 张杰 348 朱跃安 链接汇总 组长博客:后敬甲 ...
- expect 批量自动部署ssh 免密登陆 之 三
#!/bin/expect -- ########################################## zhichao.hu #Push the id.pas.pub public k ...