第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测
1. 导入boston房价数据集
2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示。
3. 多元线性回归模型,建立13个变量与房价之间的预测模型,并检测模型好坏,并图形化显示检查结果。
4. 一元多项式回归模型,建立一个变量与房价之间的预测模型,并图形化显示。
代码:
#导入boston房价数据集
from sklearn.datasets import load_boston
import pandas as pd boston = load_boston()
df = pd.DataFrame(boston.data) #一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示。
from sklearn.linear_model import LinearRegression
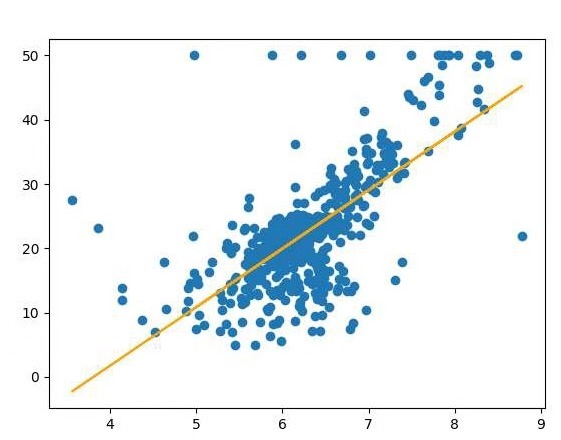
import matplotlib.pyplot as plt x =boston.data[:,5]
y = boston.target
LinR = LinearRegression()
LinR.fit(x.reshape(-1,1),y)
w=LinR.coef_
b=LinR.intercept_
print(w,b) plt.scatter(x,y)
plt.plot(x,w*x+b,'orange')
plt.show() #多元线性回归模型,建立13个变量与房价之间的预测模型,并检测模型好坏,并图形化显示检查结果。
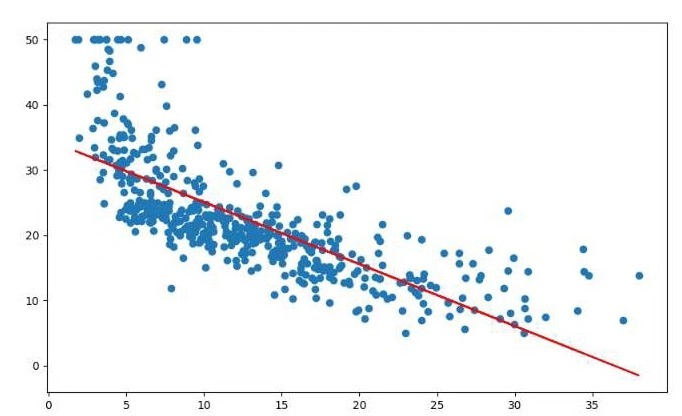
x = boston.data[:,12].reshape(-1,1)
y = boston.target
plt.figure(figsize=(10,6))
plt.scatter(x,y) lineR = LinearRegression()
lineR.fit(x,y)
y_pred = lineR.predict(x)
plt.plot(x,y_pred,'r')
print(lineR.coef_,lineR.intercept_)
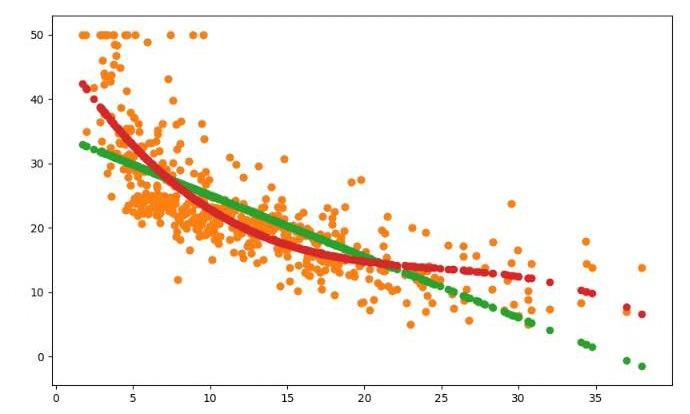
plt.show() #一元多项式回归模型,建立一个变量与房价之间的预测模型,并图形化显示。 from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=3)
x_poly = poly.fit_transform(x)
print(x_poly)
lrp = LinearRegression()
lrp.fit(x_poly,y)
y_poly_pred = lrp.predict(x_poly)
plt.scatter(x,y)
plt.scatter(x,y_pred)
plt.scatter(x,y_poly_pred)
plt.show()
运行结果:

第十一次作业——sklearn中朴素贝叶斯模型及其应用
1.使用朴素贝叶斯模型对iris数据集进行花分类
尝试使用3种不同类型的朴素贝叶斯:
高斯分布型
多项式型
伯努利型
2.使用sklearn.model_selection.cross_val_score(),对模型进行验证。
3. 垃圾邮件分类
数据准备:
- 用csv读取邮件数据,分解出邮件类别及邮件内容。
- 对邮件内容进行预处理:去掉长度小于3的词,去掉没有语义的词等
尝试使用nltk库:
pip install nltk
import nltk
nltk.download
不成功:就使用词频统计的处理方法
训练集和测试集数据划分
- from sklearn.model_selection import train_test_split
代码:
# 导入鸢尾花数据集
from sklearn.datasets import load_iris # 数据选取
iris_data = load_iris()['data']
iris_target = load_iris()['target'] # 用高斯模型进行预测并评估
from sklearn.naive_bayes import GaussianNB
mol = GaussianNB()
result = mol.fit(iris_data,iris_target)
# 对模型进行评估
from sklearn.model_selection import cross_val_score
scores = cross_val_score(mol,iris_data,iris_target,cv=10)
# 对预测结果的正确个数进行计算
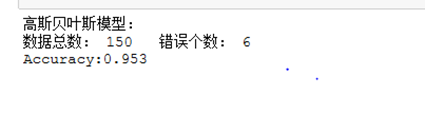
print("高斯模型:")
print("数据总数:",len(iris_data)," 错误个数:",(iris_target != predi).sum())
print("Accuracy:%.3f"%scores.mean()) # 用贝努里模型进行预测和评估
from sklearn.naive_bayes import BernoulliNB
bnb = BernoulliNB()
result2 = bnb.fit(iris_data,iris_target)
pred2 = bnb.predict(iris_data)
# 计算错误个数
print("贝努里模型:")
print("数据总数:",len(iris_data)," 错误个数:",(iris_target != pred2).sum())
#模型评分
scores2 = cross_val_score(bnb,iris_data,iris_target)
print("Accuracy:%.3f"%scores2.mean()) # 用多项式建立模型进行预测和评估
from sklearn.naive_bayes import MultinomialNB
mnb = MultinomialNB()
result3 = mnb.fit(iris_data,iris_target)
# 预测
pred3 = result3.predict(iris_data)
# 计算错误个数
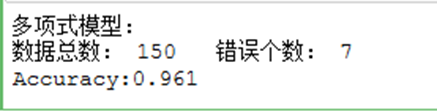
print("多项式模型:")
print("数据总数:",iris_data.shape[0]," 错误个数:",(iris_target != pred3).sum())
# 模型评分
scores3 = cross_val_score(mnb,iris_data,iris_target)
print("Accuracy:%.3f"%scores3.mean())
运行结果:

第七次作业——numpy统计分布显示
用np.random.normal()产生一个正态分布的随机数组,并显示出来。
np.random.randn()产生一个正态分布的随机数组,并显示出来。
显示鸢尾花花瓣长度的正态分布图,曲线图,散点图。
代码:
import numpy as np # 导入鸢尾花数据
from sklearn.datasets import load_iris
data = load_iris()
pental_len = data.data[:,2] # 计算鸢尾花花瓣长度最大值,平均值,中值,均方差
print("最大值:",np.max(pental_len))
print("平均值:",np.mean(pental_len))
print("中值:",np.median(pental_len))
print("均方差:",np.std(pental_len)) # 用np.random.normal()产生一个正态分布的随机数组,并显示出来
print(np.random.normal(1,4,50))
print('============================================================================') # np.random.randn()产生一个正态分布的随机数组,并显示出来
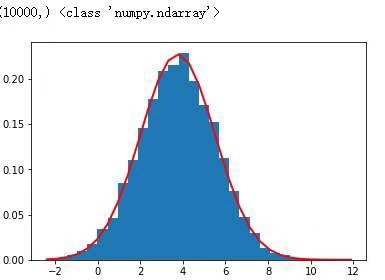
print(np.random.randn(50)) # 显示鸢尾花花瓣长度的正态分布图
import matplotlib.pyplot as plt
mu = np.mean(pental_len)
sigma = np.std(pental_len)
num = 10000
rand_data=np.random.normal(mu,sigma,num)
count,bins,ignored=plt.hist(rand_data,30,normed=True)
plt.plot(bins,1/(sigma*np.sqrt(2*np.pi))*np.exp(-(bins-mu)**2/(2*sigma**2)),linewidth=2,color="r")
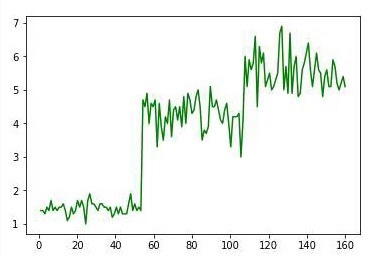
plt.show() # 显示鸢尾花花瓣长度曲线图
plt.plot(np.linspace(1,160,num=150),pental_len,'g')
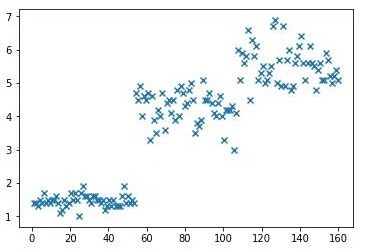
plt.show() # 显示鸢尾花花瓣长度散点图
plt.scatter(np.linspace(1,160,num=150),pental_len,alpha=1,marker='x')
plt.show()
运行结果:


第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示的更多相关文章
- 一步步教你轻松学朴素贝叶斯模型算法Sklearn深度篇3
一步步教你轻松学朴素贝叶斯深度篇3(白宁超 2018年9月4日14:18:14) 导读:朴素贝叶斯模型是机器学习常用的模型算法之一,其在文本分类方面简单易行,且取得不错的分类效果.所以很受欢迎,对 ...
- 机器学习Matlab打击垃圾邮件的分类————朴素贝叶斯模型
该系列来自于我<人工智能>课程回顾总结,以及实验的一部分进行了总结学习机 垃圾分类是有监督的学习分类最经典的案例,本文首先回顾了概率论的基本知识.则以及朴素贝叶斯模型的思想.最后给出了垃圾 ...
- PGM:贝叶斯网表示之朴素贝叶斯模型naive Bayes
http://blog.csdn.net/pipisorry/article/details/52469064 独立性质的利用 条件参数化和条件独立性假设被结合在一起,目的是对高维概率分布产生非常紧凑 ...
- 11.sklearn中的朴素贝叶斯模型及其应用
#1.使用朴素贝叶斯模型对iris数据集进行花分类 #尝试使用3种不同类型的朴素贝叶斯: #高斯分布型,多项式型,伯努利型 from sklearn import datasets iris=data ...
- 统计学习1:朴素贝叶斯模型(Numpy实现)
模型 生成模型介绍 我们定义样本空间为\(\mathcal{X} \subseteq \mathbb{R}^n\),输出空间为\(\mathcal{Y} = \{c_1, c_2, ..., c_K\ ...
- Python实现 利用朴素贝叶斯模型(NBC)进行问句意图分类
目录 朴素贝叶斯分类(NBC) 程序简介 分类流程 字典(dict)构造:用于jieba分词和槽值替换 数据集构建 代码分析 另外:点击右下角魔法阵上的[显示目录],可以导航~~ 朴素贝叶斯分类(NB ...
- sklearn中的朴素贝叶斯模型及其应用
1.(1)多项式 from sklearn.datasets import load_iris iris = load_iris() from sklearn.naive_bayes import G ...
- R 基于朴素贝叶斯模型实现手机垃圾短信过滤
# 读取数数据, 查看数据结构 df_raw <- read.csv("sms_spam.csv", stringsAsFactors=F) str(df_raw) leng ...
- 后端程序员之路 18、朴素贝叶斯模型(Naive Bayesian Model,NBM)
贝叶斯推断及其互联网应用(一):定理简介 - 阮一峰的网络日志http://www.ruanyifeng.com/blog/2011/08/bayesian_inference_part_one.ht ...
随机推荐
- Java对象、引用、实例
https://blog.csdn.net/zmx729618/article/details/54093075
- C# Finalize和Dispose的区别
一:总结 1.Finalize方法(C#中是析构函数,以下称析构函数)是用于释放非托管资源的,而托管资源会由GC自动回收.所以,我们也可以这样来区分 托管和非托管资源.所有会由GC自动回收的资源,就是 ...
- php list()函数
说明: (PHP 4, PHP 5, PHP 7) list — 把数组中的值赋给一组变量 像 array() 一样,这不是真正的函数,而是语言结构. list() 可以在单次操作内就为一组变量赋值. ...
- RsaUtils
参考来源:https://www.cnblogs.com/pcheng/p/9629621.html 里面的这段话,非常好 RSA加密对明文的长度有所限制,规定需加密的明文最大长度=密钥长度-11(单 ...
- 搭建openstack环境时出现的问题
penstack环境搭建程度(安装完keystone) 然后运行 openstack domain create --description "An Example Domain" ...
- 虚拟现实外包—动点飞扬软件专门承接VR/AR场景、游戏、项目外包
VR外包AR外包公司(虚拟现实外包公司)承接虚拟现实项目开发(企业.教育.游戏.企业大数据展示等) 有VR/AR.Unity3D项目.游戏外包业务欢迎 联系我们 QQ:372900288 TEL:13 ...
- react初探(一)之JSX、状态(state)管理、条件渲染、事件处理
前言: 最近收到组长通知我们项目组后面新开的项目准备统一技术栈为react,目前我的情况是三大框架只会angular和Vue.在实际项目中只使用过一次angular5,其余项目都是使用Vue写的.写篇 ...
- 请为CMyString类型编写构造函数、copy构造函数、析构函数和赋值运算符函数。
如下为类型CMyString的声明,请为该类型编写构造函数.copy构造函数.析构函数和赋值运算符函数. class CMyString { public: CMyString(const char* ...
- Docker镜像加速器配置
一.为什么要配置Docker镜像加速器 因为我们默认pull的docker镜像是从Docker Hub来下载,由于其服务器在国外,速度会比较慢.因此我们可以配置成国内的镜像仓库,这样可以加速镜像的上传 ...
- 微信小程序笔记
1.文件的作用 js,wxml,wxss,json 所有页面中要用到的变量,都放在可了pages目录下 wxml:类似于html文件 wxss:类似于css文件(类, id, 标签,子代,后代,bef ...