HBase原理分析
宏观架构
HBase从宏观上看只有HMaster、RegionServer和zookeeper三个组件。
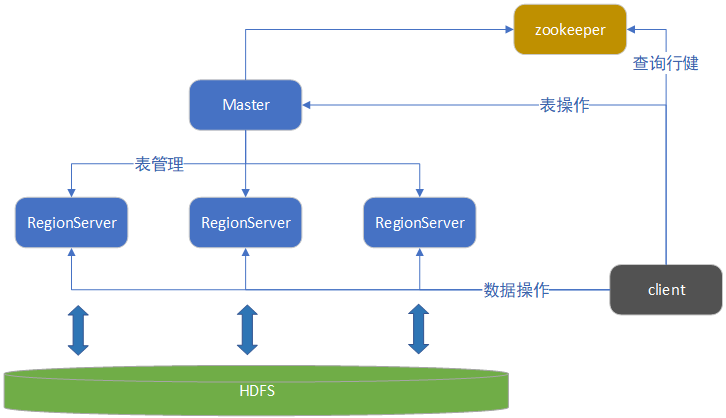
Master: 负责启动的时候分配Region到具体的RegionServer,执行各种管理操作,比如Region的分割合并。HBase的Master是不负责数据的读写的,所以它挂了集群照样可以运行并读写数据,但是无法新建删除表。
RegionServer:RegionServer上有一个或者多个Region。读写的数据就存储在Region上。
Region:表的一部分数据,HBase是个会自动分片的数据库。一个Region就相当于关系型数据库中的一个分区表中的分区。
zookeeper:HBase没有Master可以运行,但是没有zookeeper是无法运行的,在JavaAPI在读写HBase时,配置的就是zookeeper的地址,而不是HBase本身的地址。因为读取数据所需要的元数据表就存储在zookeeper上。
微观架构
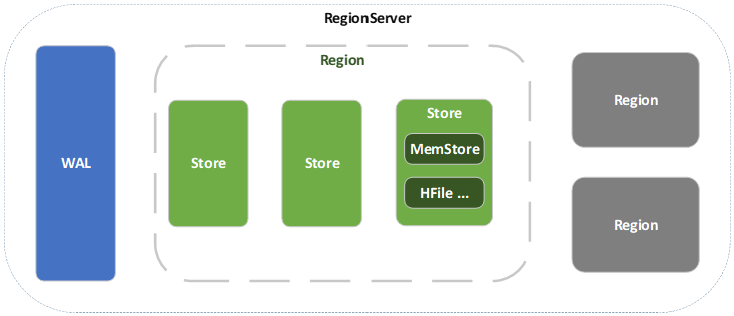
WAL 预写日志
WAL,预写日志,WAL是Write-Ahead Log的缩写。当操作到达Region的时候,HBase会直接把操作写到WAL中,然后会将数据放到基于内存实现的Memstore,等数据到达一定量时才flush到HFile中,如果这个过程中服务宕机或者断电,那么数据就丢失了。WAL是一个保险机制,数据在写到Memstore之前就会写到WAL,这样WAL中的日志就是数据恢复的依据。WAL默认是开启的。一个好的软件的设计真的是连服务器的宕机都考虑进去了。
Memstore
Memstore,为了让HBase中的读取效率提高,设计了Memstore,数据写入HDFS之前会先写入这里,然后数据量达到一个阀值就flush到HFile中。HBase是采用LSM树来保存数据,所以在Memstore中会先将数据整理为LSM树,然后再刷写到磁盘。
LSM树,即日志结构合并树(Log-Structured Merge-Tree)。其实它并不属于一个具体的数据结构,它更多是一种数据结构的设计思想。将数据分别放到内存和磁盘中,每次有数据更新不是必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到阀值后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾,因为所有待排序的树都是经过排序的,可以通过合并排序的方式快速合并到一起。
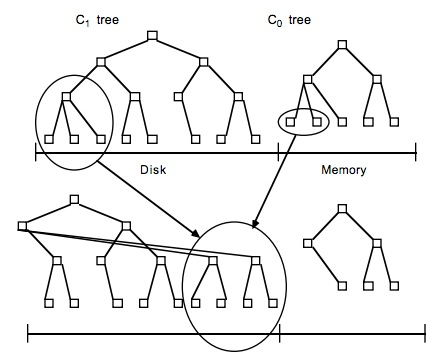
虽然新写入的数据会暂存Memstore中,但并不是读取数据的时候也是先读Memstore,再去读磁盘。
HFile
HFile , 是HBase数据真正的载体,创建所有的表、列等数据都放到HFile中。HFile也是StoreFile,有的地方也叫StoreFile。
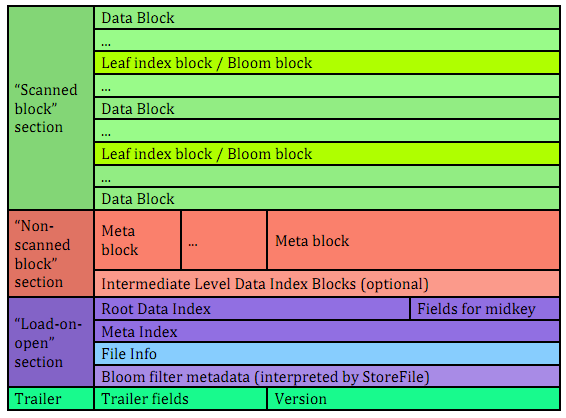
文件主要分为四个部分:Scanned block section,Non-scanned block section,Opening-time data section和Trailer。
Scanned block section:顾名思义,表示顺序扫描HFile时所有的数据块将会被读取,包括Leaf Index Block和Bloom Block以及DataBlock。(DataBlock是HBase中数据存储的最小单元。DataBlock中主要存储用户的KeyValue数据(KeyValue后面一般会跟一个timestamp)
Non-scanned block section:表示在HFile顺序扫描的时候数据不会被读取,主要包括Meta Block和Intermediate Level Data Index Blocks两部分。
Load-on-open-section:这部分数据在HBase的region server启动时,需要加载到内存中。包括FileInfo、Bloom filter block、data block index和meta block index。
Trailer:这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
HFile会被切分为多个大小相等的block块,每个block的大小可以在创建表列簇的时候通过参数blocksize 进行指定,默认为64k,大号的Block有利于顺序Scan,小号Block利于随机查询,因而需要权衡。并且所有block块都拥有相同的数据结构。
未完,待补充...
HBase原理分析的更多相关文章
- 1、Hbase原理分析
一.Hbase介绍 1.1.对Hbase的认识 HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现. HBase参考 Google 的 Bigtable ...
- flink-----实时项目---day07-----1.Flink的checkpoint原理分析 2. 自定义两阶段提交sink(MySQL) 3 将数据写入Hbase(使用幂等性结合at least Once实现精确一次性语义) 4 ProtoBuf
1.Flink中exactly once实现原理分析 生产者从kafka拉取数据以及消费者往kafka写数据都需要保证exactly once.目前flink中支持exactly once的sourc ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
- HBase源代码分析之MemStore的flush发起时机、推断条件等详情(二)
在<HBase源代码分析之MemStore的flush发起时机.推断条件等详情>一文中,我们具体介绍了MemStore flush的发起时机.推断条件等详情.主要是两类操作.一是会引起Me ...
- Hadoop数据管理介绍及原理分析
Hadoop数据管理介绍及原理分析 最近2014大数据会议正如火如荼的进行着,Hadoop之父Doug Cutting也被邀参加,我有幸听了他的演讲并获得亲笔签名书一本,发现他竟然是左手写字,当然这个 ...
- HBase原理 – 分布式系统中snapshot是怎么玩的?(转载)
snapshot(快照)基础原理 snapshot是很多存储系统和数据库系统都支持的功能.一个snapshot是一个全部文件系统.或者某个目录在某一时刻的镜像.实现数据文件镜像最简单粗暴的方式是加锁拷 ...
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Handler系列之原理分析
上一节我们讲解了Handler的基本使用方法,也是平时大家用到的最多的使用方式.那么本节让我们来学习一下Handler的工作原理吧!!! 我们知道Android中我们只能在ui线程(主线程)更新ui信 ...
- Java NIO使用及原理分析(1-4)(转)
转载的原文章也找不到!从以下博客中找到http://blog.csdn.net/wuxianglong/article/details/6604817 转载自:李会军•宁静致远 最近由于工作关系要做一 ...
随机推荐
- leetcode — candy
/** * Source : https://oj.leetcode.com/problems/candy/ * * There are N children standing in a line. ...
- groupcache源码解析-概览
接下来讲什么 今天开始讲groupcache! Memcached大家应该都不陌生,官网的介绍是: Free & open source, high-performance, distribu ...
- python常用脚本以及问题跟踪
1.时间操作//获取当前时间 格式是%Y-%m-%d %H:%M:%ScurrTime = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time. ...
- Spring Boot 2.x(五):整合Mybatis-Plus
简介 Mybatis-Plus是在Mybatis的基础上,国人开发的一款持久层框架. 并且荣获了2018年度开源中国最受欢迎的中国软件TOP5 同样以简化开发为宗旨的Spring Boot与Mybat ...
- Python3+Selenium2完整的自动化测试实现之旅(五):自动化测试框架、Python面向对象以及POM设计模型简介
前言 之前的系列博客,陆续学习整理了自动化测试环境的搭建.IE和Chrome浏览器驱动的配置.selenium-webdriver模块封装的元素定位以及控制浏览器.处理警示框.鼠标键盘等方法的使用,这 ...
- demo_2
业务层 package com.demo.service; import com.demo.pojo.User; public interface IUserService { /** * 用户登录 ...
- C# Word文档中插入、提取图片,文字替换图片
Download Files:ImageOperationsInWord.zip 简介 在这篇文章中我们可以学到在C#程序中使用一个Word文档对图像的各种操作.图像会比阅读文字更有吸引力,而且图像是 ...
- Java开发笔记(六十五)集合:HashSet和TreeSet
对于相同类型的一组数据,虽然Java已经提供了数组加以表达,但是数组的结构实在太简单了,第一它无法直接添加新元素,第二它只能按照线性排列,故而数组用于基本的操作倒还凑合,若要用于复杂的处理就无法胜任了 ...
- Windows系统 应用或游戏 打开出现0xc000007b错误 解决方法
1.使用directX修复工具(推荐) 标准版 增强版 标准版备用地址 增强版备用地址 2. 重新安装DirectX 9.0 安装包(安装包体积大) 微软官方离线安装包 摘录CSDN博客 运行游戏时出 ...
- Activiti(二) springBoot2集成activiti,集成activiti在线设计器
摘要 本篇随笔主要记录springBoot2集成activiti流程引擎,并且嵌入activiti的在线设计器,可以通过浏览器直接编辑出我们需要的流程,不需要通过eclipse或者IDEA的actiB ...