SparkSQL学习进度9-SQL实战案例
Spark SQL 基本操作
将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json。
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
为 employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
(1) 查询所有数据;
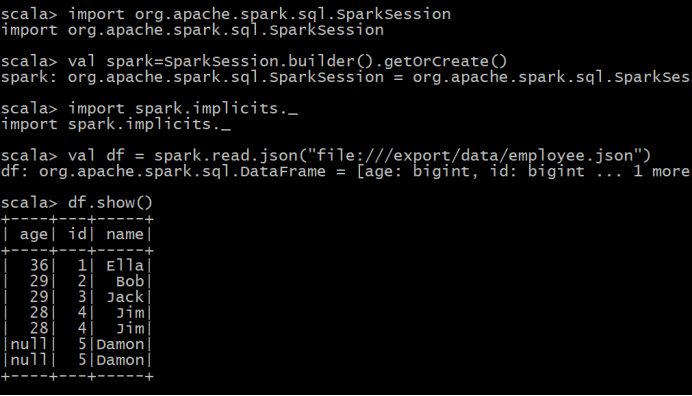
(2) 查询所有数据,并去除重复的数据;
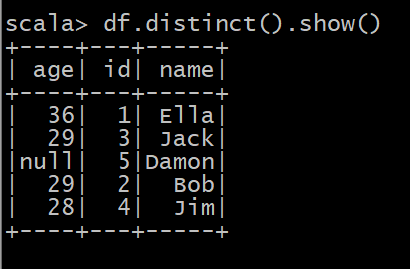
(3) 查询所有数据,打印时去除 id 字段;

(4) 筛选出 age>30 的记录;

(5) 将数据按 age 分组;

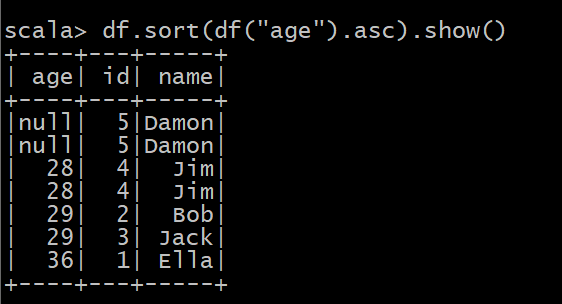
(6) 将数据按 name 升序排列;
(7) 取出前 3 行数据;

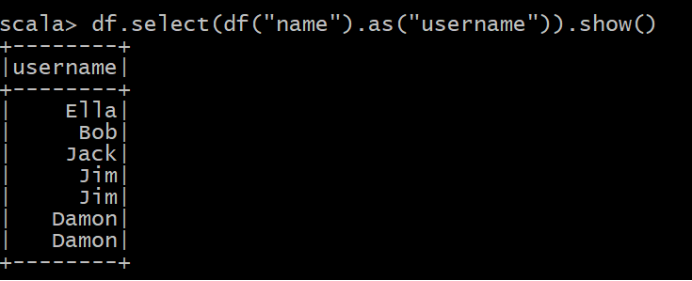
(8) 查询所有记录的 name 列,并为其取别名为 username;
(9) 查询年龄 age 的平均值;
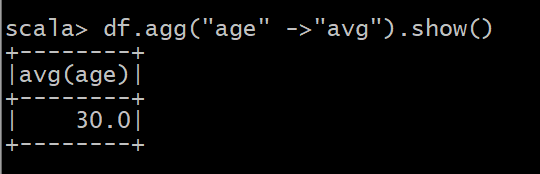
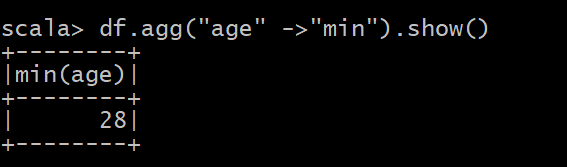
(10) 查询年龄 age 的最小值。
编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代码。
package cn.itcast.spark.mook import org.apache.spark.sql.SparkSession
import org.junit.Test class RDDtoDataFrame { @Test
def test(): Unit ={
val spark=SparkSession.builder()
.appName("datafreame1")
.master("local[6]")
.getOrCreate() import spark.implicits._
val df=spark.sparkContext.textFile("dataset/employee.txt").map(_.split(","))
.map(item => Employee(item(0).trim.toInt,item(1),item(2).trim.toInt))
.toDF()
df.createOrReplaceTempView("employee")
val dfRDD=spark.sql("select * from employee")
dfRDD.map(it => "id:"+it(0) +",name:"+it(1)+",age:"+it(2) )
.show()
}
}
case class Employee(id:Int,name:String,age:Long)

编程实现利用 DataFrame 读写 MySQL 的数据
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的两行数据。
表 6-2 employee 表原有数据
id name gender Age
1 Alice F 22
2 John M 25

(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
表 6-3 employee 表新增数据
id name gender age
3 Mary F 26
4 Tom M 23
package cn.itcast.spark.mook
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.spark.sql.types.{FloatType, IntegerType, StringType, StructField, StructType}
object MysqlOp {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("mysql example")
.master("local[6]")
.getOrCreate()
val schema = StructType(
List(
StructField("id", IntegerType),
StructField("name", StringType),
StructField("gender", StringType),
StructField("age", IntegerType)
)
)
val studentDF = spark.read
//分隔符:制表符
.option("delimiter", ",")
.schema(schema)
.csv("dataset/stu")
studentDF.write
.format("jdbc")
.mode(SaveMode.Append)
.option("url", "jdbc:mysql://hadoop101:3306/spark02")
.option("dbtable", "employee")
.option("user", "spark")
.option("password", "fengge666")
.save()
spark.read
.format("jdbc")
.option("url", "jdbc:mysql://hadoop101:3306/spark02")
.option("dbtable","(select max(age),SUM(age) from employee) as emp")
.option("user", "spark")
.option("password", "fengge666")
.load()
.show()
}
}
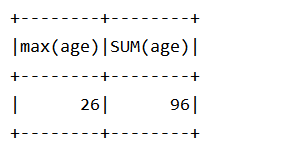
SparkSQL学习进度9-SQL实战案例的更多相关文章
- Salesforce学习之路-developer篇(五)一文读懂Aura原理及实战案例分析
1. 什么是Lightning Component框架? Lightning Component框架是一个UI框架,用于为移动和台式设备开发Web应用程序.这是一个单页面Web应用框架,用于为Ligh ...
- 大数据学习day20-----spark03-----RDD编程实战案例(1 计算订单分类成交金额,2 将订单信息关联分类信息,并将这些数据存入Hbase中,3 使用Spark读取日志文件,根据Ip地址,查询地址对应的位置信息
1 RDD编程实战案例一 数据样例 字段说明: 其中cid中1代表手机,2代表家具,3代表服装 1.1 计算订单分类成交金额 需求:在给定的订单数据,根据订单的分类ID进行聚合,然后管理订单分类名称, ...
- 【大数据】SparkSql学习笔记
第1章 Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和 DataSet,并且作为分布式 ...
- 基于SpringCloud的Microservices架构实战案例-架构拆解
自第一篇< 基于SpringCloud的Microservices架构实战案例-序篇>发表出来后,差不多有半年时间了,一直也没有接着拆分完,有如读本书一样,也是需要契机的,还是要把未完成的 ...
- 【Redis3.0.x】实战案例
Redis3.0.x 实战案例 简介 <Redis实战>的学习笔记和总结. 书籍链接 初识 Redis Redis 简介 Redis 是一个速度非常快的键值对存储数据库,它可以存储键和五种 ...
- Shell高级编程视频教程-跟着老男孩一步步学习Shell高级编程实战视频教程
Shell高级编程视频教程-跟着老男孩一步步学习Shell高级编程实战视频教程 教程简介: 本教程共71节,主要介绍了shell的相关知识教程,如shell编程需要的基础知识储备.shell脚本概念介 ...
- 跟着老男孩一步步学习Shell高级编程实战
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://oldboy.blog.51cto.com/2561410/1264627 本sh ...
- SQL反模式学习笔记21 SQL注入
目标:编写SQL动态查询,防止SQL注入 通常所说的“SQL动态查询”是指将程序中的变量和基本SQL语句拼接成一个完整的查询语句. 反模式:将未经验证的输入作为代码执行 当向SQL查询的字符串中插入别 ...
- SQL注入(SQL Injection)案例和防御方案
sql注入(SQL Injection):就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令. SQL注入攻击的主要危害包括:非法读取.篡 ...
随机推荐
- 3、tensorflow变量运算,数学运算
import tensorflow as tf import numpy as np a = tf.range(1,7) a = tf.reshape(a,[2,3]) b = tf.constant ...
- Panda Global 要点聚焦,区块链在数字医疗的落地应
据Panda Global,随着区块链技术影响力的不断扩大,其应用性已涉及更加广泛的领域,不断更新着人们的认知.在区块链技术未介入之前,关于医疗行业和数字经济结合早已不是什么新鲜话题,相关研究不少 但 ...
- Codeforces Edu Round 56 A-D
A. Dice Rolling 把\(x\)分解为\(a * 6 + b\),其中\(a\)是满6数,\(b\)满足\(1 <= b < 6\),即可... #include <io ...
- 一、Nginx笔记--linux下载安装部署Nginx
Nginx 到底是什么? Nginx 是⼀个⾼性能的HTTP和反向代理web服务器,核⼼特点是占有内存少,并发能⼒强 Nginx ⼜能做什么事情(应⽤场景) Http服务器(Web服务器) 性能⾮常 ...
- STL——容器(List)List 的数据元素插入和删除操作
push_back(elem); //在容器尾部加入一个元素 1 #include <iostream> 2 #include <list> 3 4 using namespa ...
- STL—— 容器(vector)元素的删除
1. clear() 将整个 vector 都删除 使用 vectorname.clear() 可以将整个vector 中的元素全部删除,但是内存不会释放,如下代码: 1 #include <i ...
- oracle ADG启动顺序
一.oracle ADG启动顺序 1.启动主备库监听 [oracle@dgdb1 ~]$ lsnrctl start [oracle@dgdb2 ~]$ lsnrctl start 2.启动备库 ...
- 多任务-python实现-继承Thread类,单独编写一个类(2.1.2)
@ 目录 1.thread类 1.thread类 threding代码实现 import threading import time class MyThread(threading.Thread): ...
- TP学习—第一天:框架的简单学习;创建应用;
一.框架目录文件的介绍 common 核心函数库目录 conf 框架的核心配置文件 lang 语言包目录 library 核心资源库目录 tpl 不用管,就是几个模板 Thin ...
- sqli-labs Less-1~~~Less-23
Less-1 payload:'+and+1=2+union+select+1,username,password+from+security.users+limit 0,1--+ 第一关正规的字符型 ...