【Elasticsearch 技术分享】—— 十张图带大家看懂 ES 原理 !明白为什么说:ES 是准实时的!
前言
说到 Elasticsearch ,其中最明显的一个特点就是 near real-time 准实时 —— 当文档存储在Elasticsearch中时,将在1秒内以几乎实时的方式对其进行索引和完全搜索。那为什么说 ES 是准实时的呢?
公众号:『 刘志航 』,记录工作学习中的技术、开发及源码笔记;时不时分享一些生活中的见闻感悟。欢迎大佬来指导!
Lucene 和 ES
Lucene
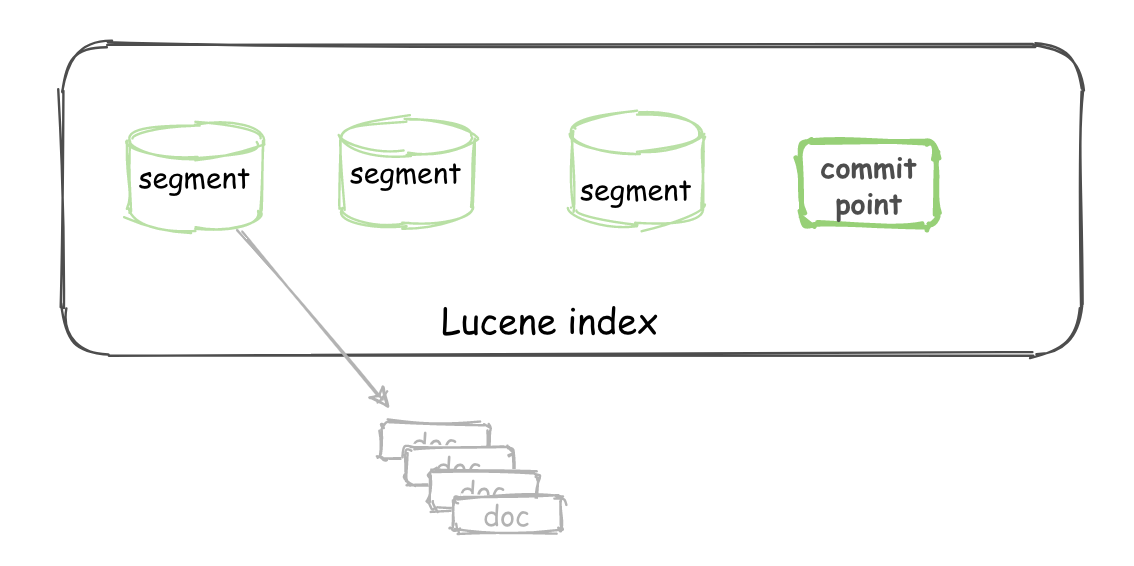
Lucene 是 Elasticsearch所基于的 Java 库,它引入了按段搜索的概念。
Segment: 也叫段,类似于倒排索引,相当于一个数据集。
Commit point:提交点,记录着所有已知的段。
Lucene index: “a collection of segments plus a commit point”。由一堆 Segment 的集合加上一个提交点组成。
对于一个 Lucene index 的组成,如下图所示。
Elasticsearch
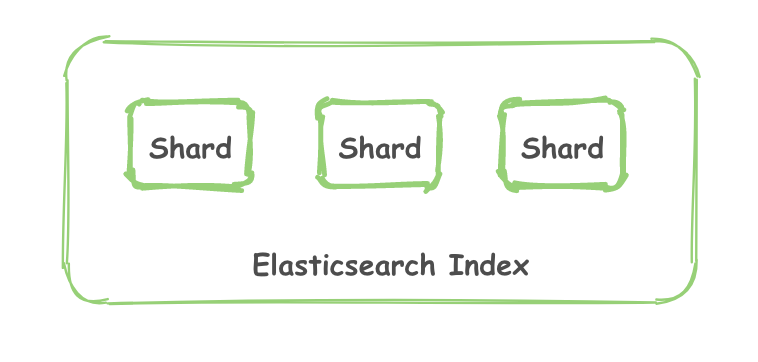
一个 Elasticsearch Index 由一个或者多个 shard (分片) 组成。
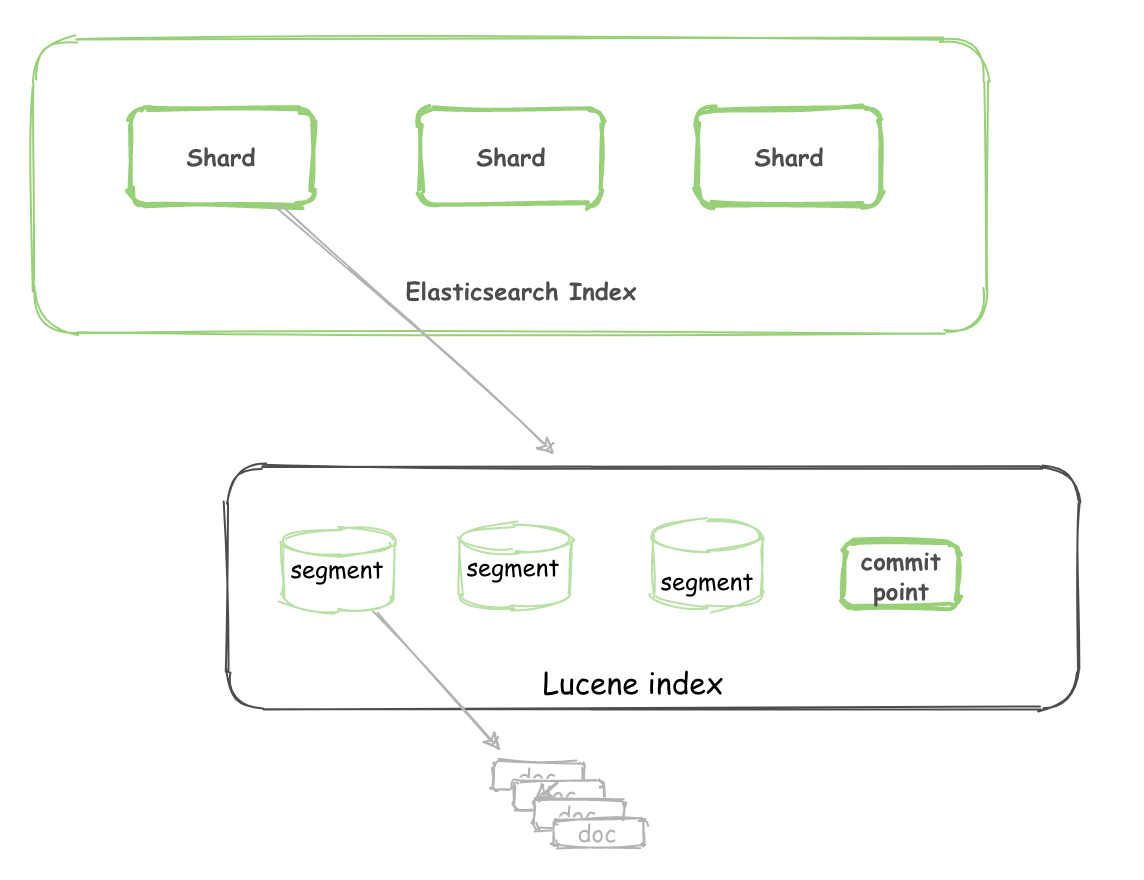
而 Lucene 中的 Lucene index 相当于 ES 的一个 shard。
写入过程
写入过程 1.0 (不完善)
- 不断将 Document 写入到 In-memory buffer (内存缓冲区)。
- 当满足一定条件后内存缓冲区中的 Documents 刷新到磁盘。
- 生成新的 segment 以及一个 Commit point 提交点。
- 这个 segment 就可以像其他 segment 一样被读取了。
画图如下:
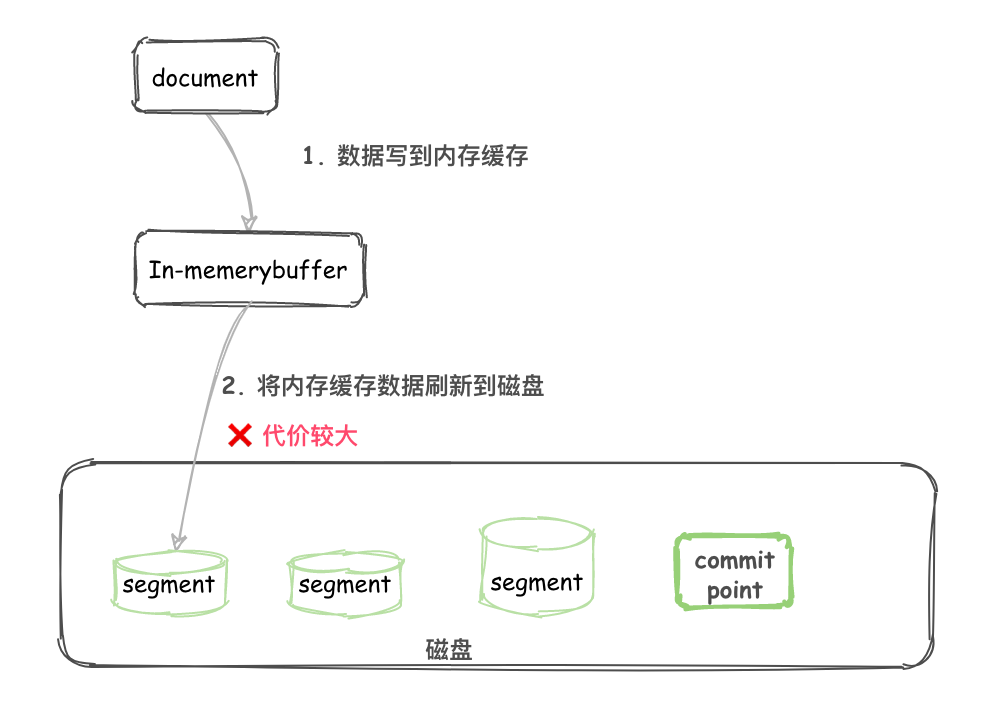
将文件刷新到磁盘是非常耗费资源的,而且在内存缓冲区和磁盘中间存在一个高速缓存(cache),一旦文件进入到 cache 就可以像磁盘上的 segment 一样被读取了。
写入过程 2.0
- 不断将 Document 写入到 In-memory buffer (内存缓冲区)。
- 当满足一定条件后内存缓冲区中的 Documents 刷新到 高速缓存(cache)。
- 生成新的 segment ,这个 segment 还在 cache 中。
- 这时候还没有 commit ,但是已经可以被读取了。
画图如下:
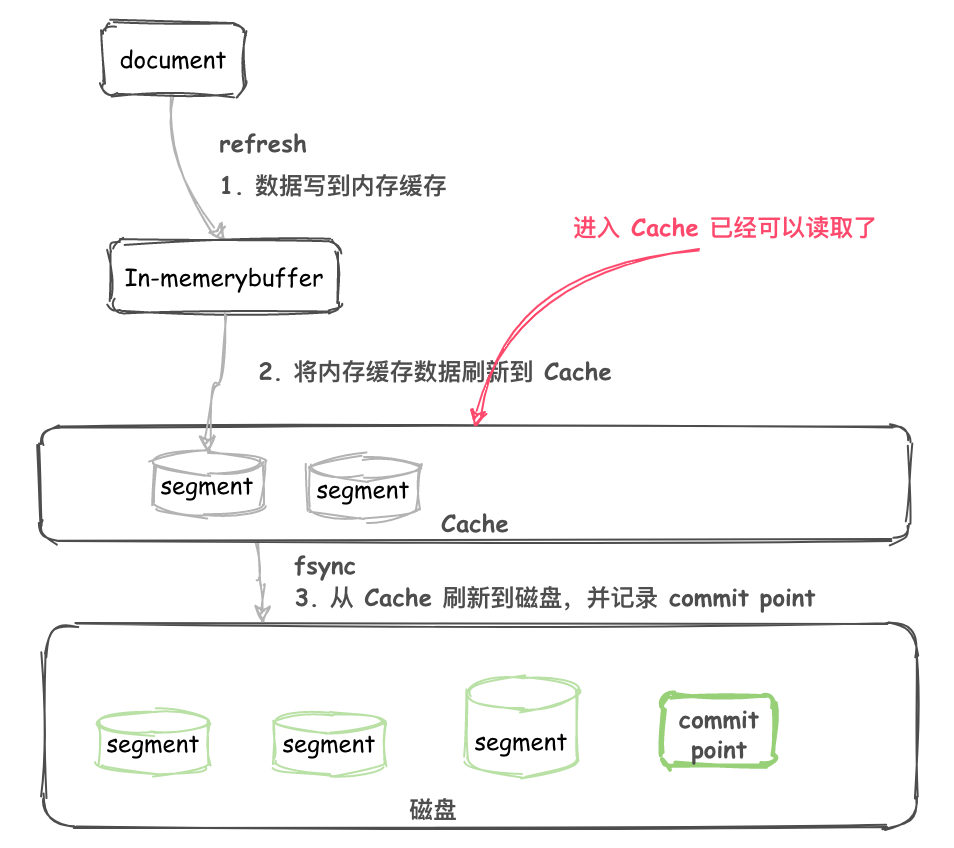
数据从 buffer 到 cache 的过程是定期每秒刷新一次。所以新写入的 Document 最慢 1 秒就可以在 cache 中被搜索到。
而 Document 从 buffer 到 cache 的过程叫做 ?refresh 。一般是 1 秒刷新一次,不需要进行额外修改。当然,如果有修改的需要,可以参考文末的相关资料。这也就是为什么说 Elasticsearch 是准实时的。
使文档立即可见:
PUT /test/_doc/1?refresh
{"test": "test"}
// 或者
PUT /test/_doc/2?refresh=true
{"test": "test"}
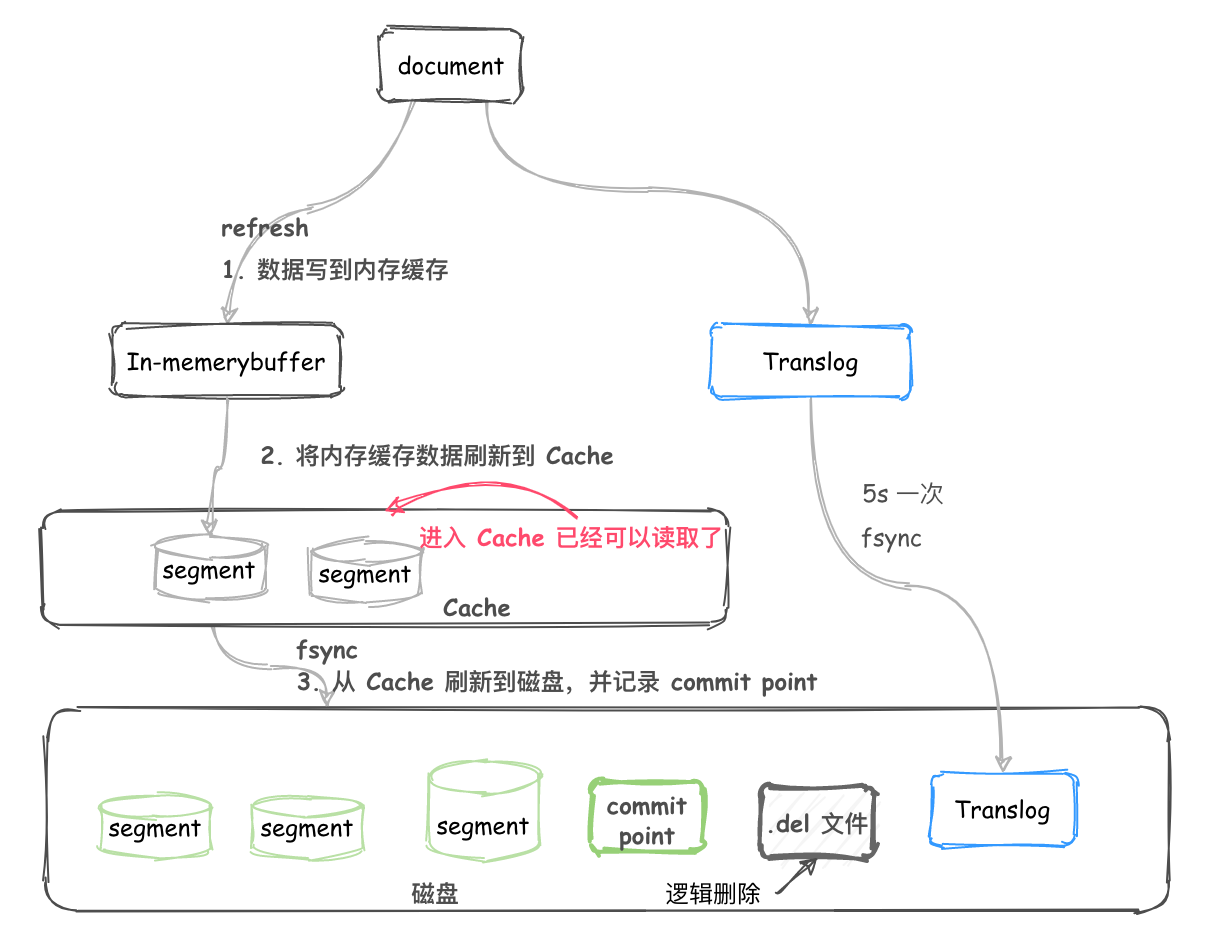
Translog 事务日志
此处可以联想 Mysql 的 binlog, ES 中也存在一个 translog 用来失败恢复。
- Document 不断写入到 In-memory buffer,此时也会追加 translog。
- 当 buffer 中的数据每秒 refresh 到 cache 中时,translog 并没有进入到刷新到磁盘,是持续追加的。
- translog 每隔 5s 会 fsync 到磁盘。
- translog 会继续累加变得越来越大,当 translog 大到一定程度或者每隔一段时间,会执行 flush。
![]()
flush 操作会分为以下几步执行:
- buffer 被清空。
- 记录 commit point。
- cache 内的 segment 被 fsync 刷新到磁盘。
- translog 被删除。
![]()
值得注意的是:
- translog 每 5s 刷新一次磁盘,所以故障重启,可能会丢失 5s 的数据。
- translog 执行 flush 操作,默认 30 分钟一次,或者 translog 太大 也会执行。
手动执行flush:
POST /my-index-000001/_flush
删除和更新
segment 不可改变,所以 docment 并不能从之前的 segment 中移除或更新。
所以每次 commit, 生成 commit point 时,会有一个 .del 文件,里面会列出被删除的 document(逻辑删除)。
而查询时,获取到的结果在返回前会经过 .del 过滤。
更新时,也会标记旧的 docment 被删除,写入到 .del 文件,同时会写入一个新的文件。此时查询会查询到两个版本的数据,但在返回前会被移除掉一个。
segment 合并
每 1s 执行一次 refresh 都会将内存中的数据创建一个 segment。
segment 数目太多会带来较大的麻烦。 每一个 segment 都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个 segment ;所以 segment 越多,搜索也就越慢。
在 ES 后台会有一个线程进行 segment 合并。
- refresh操作会创建新的 segment 并打开以供搜索使用。
- 合并进程选择一小部分大小相似的 segment,并且在后台将它们合并到更大的 segment 中。这并不会中断索引和搜索。
- 当合并结束,老的 segment 被删除 说明合并完成时的活动:
- 新的 segment 被刷新(flush)到了磁盘。 写入一个包含新 segment 且排除旧的和较小的 segment的新 commit point。
- 新的 segment 被打开用来搜索。
- 老的 segment 被删除。
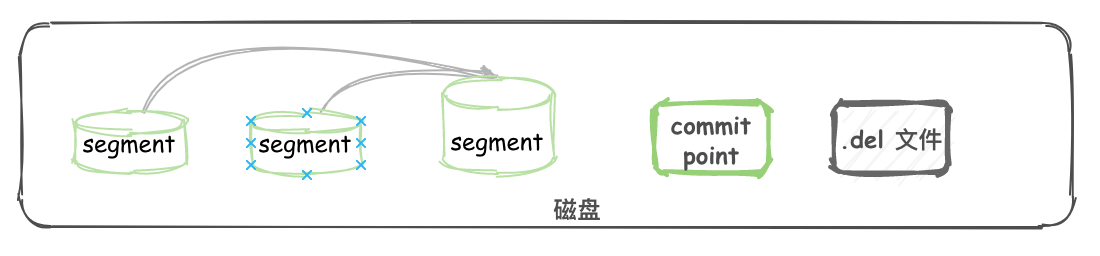
物理删除:
在 segment merge 这块,那些被逻辑删除的 document 才会被真正的物理删除。
总结
主要介绍了内部写入和删除的过程,需要了解 refresh、fsync、flush、.del、segment merge 等名词的具体含义。
完整画图如下:
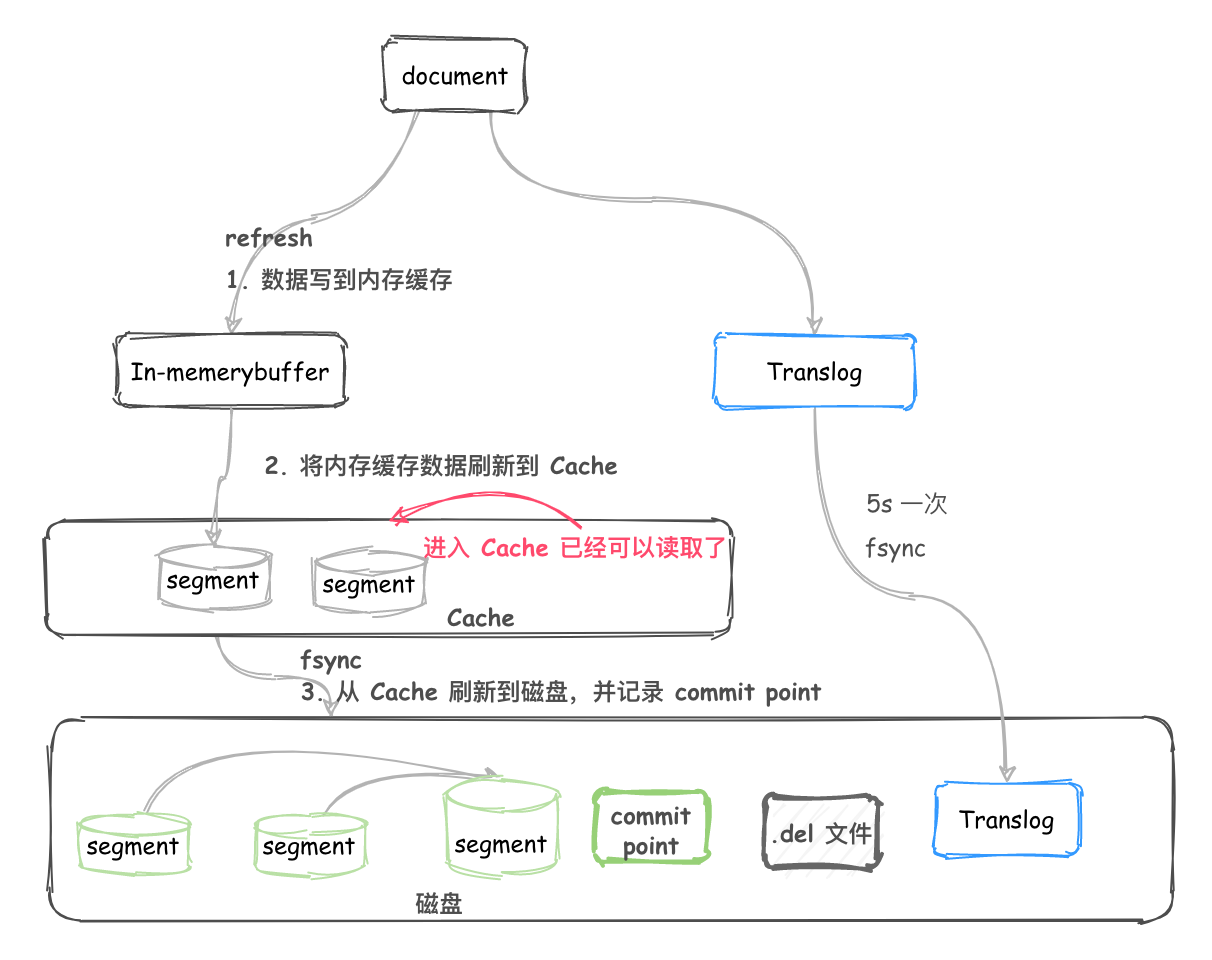
以上就是个人分享的 ES 相关的内容,主要目的是组内技术分享,进行扫盲。不对之处,希望大家留言指正。
相关资料
- 准实时搜索: https://www.elastic.co/guide/en/elasticsearch/reference/7.9/near-real-time.html
- Refresh API:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/indices-refresh.html
- Flush API:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/indices-flush.html
【Elasticsearch 技术分享】—— 十张图带大家看懂 ES 原理 !明白为什么说:ES 是准实时的!的更多相关文章
- SDWebImage实现原理--两张图带你看懂
SDWebImage底层实现有沙盒缓存机制,主要由三块组成:1.内存图片缓存,2.内存操作缓存,3.磁盘沙盒缓存 SDWebImage GitHub地址 版本4.0.0 一.SDWebImage时序图 ...
- 一张图带你看懂SpriteKit中Update Loop究竟做了神马!
1首先Scene中只有开始一点时间用来回调其中的update方法 ;] 2然后是Scene中所有动作的模拟 3接下来是上一步完成之后,给你一个机会执行一些代码 4然后是Scene模拟其中的物理世界 5 ...
- 一张图带你看懂原始dao与SQL动态代理开发的区别-Mybatis
//转载请注明出处:https://www.cnblogs.com/nreg/p/11156167.html 1.项目结构区别: 2.开发区别: 注:其中原始dao开发的实现类UserDaoImpl ...
- RocketMQ入门到入土(一)新手也能看懂的原理和实战!
学任何技术都是两步骤: 搭建环境 helloworld 我也不例外,直接搞起来. 一.RocketMQ的安装 1.文档 官方网站 http://rocketmq.apache.org GitHub h ...
- 教你看懂Code128条形码
首 页 条码控件 条码技术 条码新闻 合作伙伴 联系我们 常见问题 电话:010-84827961 当前位置:条形码控件网 > 条形码控件技术文章 > >正文 教你看懂C ...
- 腾讯技术分享:微信小程序音视频与WebRTC互通的技术思路和实践
1.概述 本文来自腾讯视频云终端技术总监rexchang(常青)技术分享,内容分别介绍了微信小程序视音视频和WebRTC的技术特征.差异等,并针对两者的技术差异分享和总结了微信小程序视音视频和WebR ...
- 腾讯技术分享:微信小程序音视频技术背后的故事
1.引言 微信小程序自2017年1月9日正式对外公布以来,越来越受到关注和重视,小程序上的各种技术体验也越来越丰富.而音视频作为高速移动网络时代下增长最快的应用形式之一,在微信小程序中也当然不能错过. ...
- FUNMVP:几张图看懂区块链技术到底是什么?(转载)
几张图看懂区块链技术到底是什么? 本文转载自:http://www.cnblogs.com/behindman/p/8873191.html “区块链”的概念可以说是异常火爆,好像互联网金融峰会上没人 ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
随机推荐
- 大话Python类语义
类 物以类聚,人以群分,就是相同特征的人和事物会自动聚集在一起,核心驱动点就是具有相同特征或相类似的特征,我们把具有相同特征或相似特征的事物放在一起,被称为分类,把分类依据的特征称为类属性 计算机中分 ...
- Open CV leaning
刚接触Open CV 几个比较好的介绍: OpenCV学习笔记:https://blog.csdn.net/yang_xian521/column/info/opencv-manual/3 OpenC ...
- 上海hande
HZero UI 一个服务于企业级产品的设计体系,基于『确定』和『自然』的设计价值观和模块化的解决方案,让设计者专注于更好的用户体验. Choerodon UI of React Choerodon ...
- Java安全之Commons Collections1分析前置知识
Java安全之Commons Collections1分析前置知识 0x00 前言 Commons Collections的利用链也被称为cc链,在学习反序列化漏洞必不可少的一个部分.Apache C ...
- Nuxt/Vue自定义导航栏Topbar+标签栏Tabbar组件
基于Vue.js实现自定义Topbar+Tabbar组件|仿咸鱼底部凸起导航 最近一直在倒腾Nuxt项目,由于Nuxt.js是基于Vue.js的服务端渲染框架,只要是会vue,基本能很快上手了. 一般 ...
- 一文看懂YOLO v3
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf论文:YOLOv3: An Incremental Improvement YOLO系列的 ...
- 多测师讲解自动化测试_rf测试报告_高级讲肖sir
(一)运行失败 1.1 1.2 用例失败log 2.3Repor 1.4Output (二)运行成功 (三)分析报告 3.1 log: 3.2Report (测试报告) 3.3 Output
- MeteoInfoLab脚本示例:读取远程文件
利用Unidata netCDF Java库对远程文件的读取能力(OpenDAP, ADDE, THREDDS等),可以读取远程文件并绘图.脚本程序: fn = 'http://monsoondata ...
- .net c#后台请求接口
我们在请求接口的时候,有时因为跨域的问题,总是请求接口失败,亦或是请求接口时,页面还存在跳转的问题,这个时候,我们通过前台ajax请求自己的一般处理程序,用一般处理程序请求客户提供的接口 //获取to ...
- 深入理解RabbitMQ中的prefetch_count参数
前提 在某一次用户标签服务中大量用到异步流程,使用了RabbitMQ进行解耦.其中,为了提高消费者的处理效率针对了不同节点任务的消费者线程数和prefetch_count参数都做了调整和测试,得到一个 ...