【Elasticsearch 技术分享】—— 十张图带大家看懂 ES 原理 !明白为什么说:ES 是准实时的!
前言
说到 Elasticsearch ,其中最明显的一个特点就是 near real-time 准实时 —— 当文档存储在Elasticsearch中时,将在1秒内以几乎实时的方式对其进行索引和完全搜索。那为什么说 ES 是准实时的呢?
公众号:『 刘志航 』,记录工作学习中的技术、开发及源码笔记;时不时分享一些生活中的见闻感悟。欢迎大佬来指导!
Lucene 和 ES
Lucene
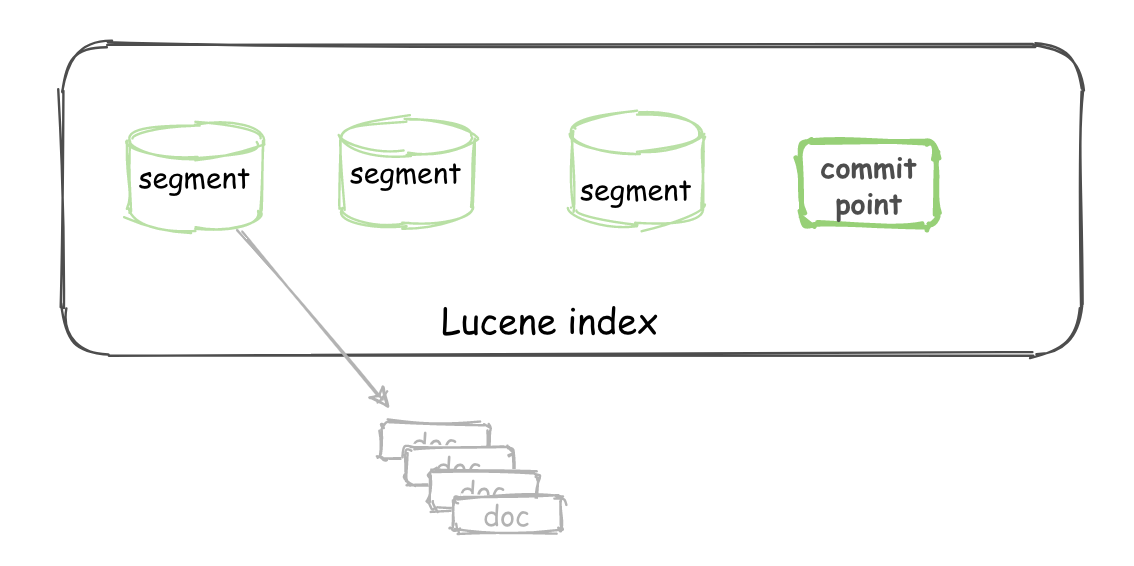
Lucene 是 Elasticsearch所基于的 Java 库,它引入了按段搜索的概念。
Segment: 也叫段,类似于倒排索引,相当于一个数据集。
Commit point:提交点,记录着所有已知的段。
Lucene index: “a collection of segments plus a commit point”。由一堆 Segment 的集合加上一个提交点组成。
对于一个 Lucene index 的组成,如下图所示。
Elasticsearch
一个 Elasticsearch Index 由一个或者多个 shard (分片) 组成。
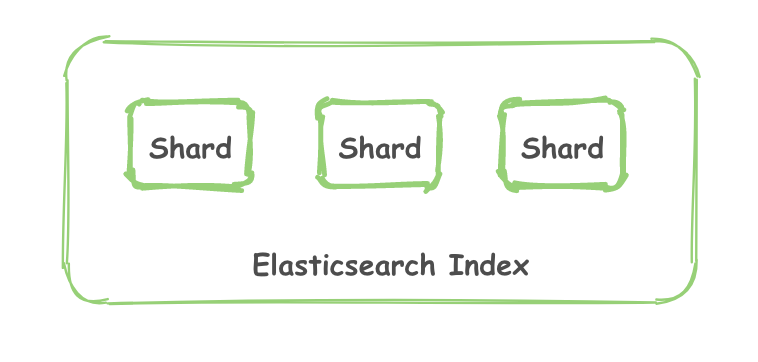
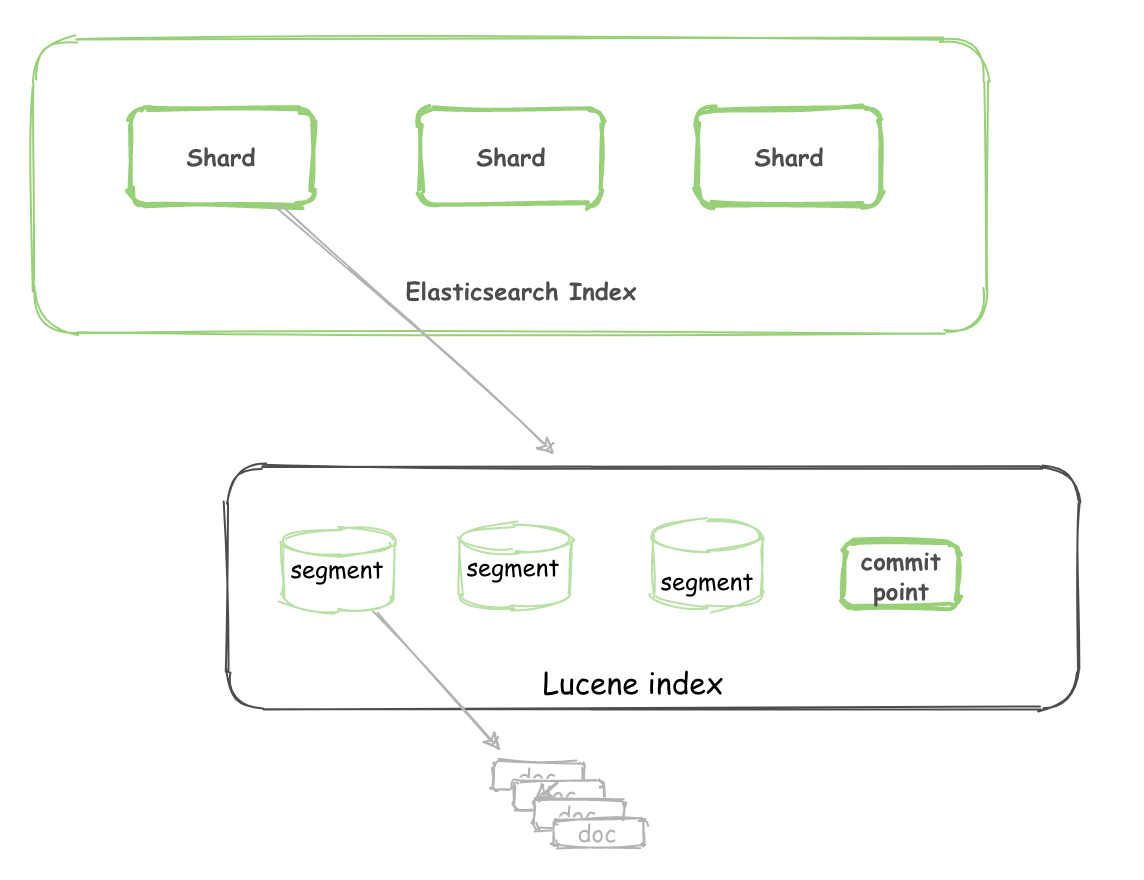
而 Lucene 中的 Lucene index 相当于 ES 的一个 shard。
写入过程
写入过程 1.0 (不完善)
- 不断将 Document 写入到 In-memory buffer (内存缓冲区)。
- 当满足一定条件后内存缓冲区中的 Documents 刷新到磁盘。
- 生成新的 segment 以及一个 Commit point 提交点。
- 这个 segment 就可以像其他 segment 一样被读取了。
画图如下:
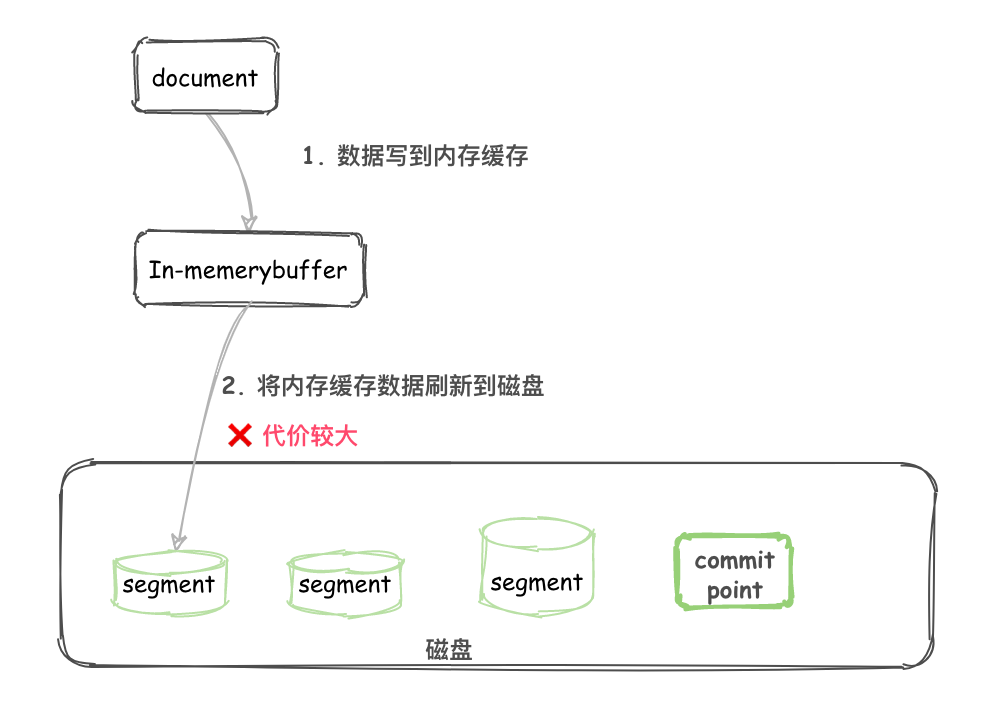
将文件刷新到磁盘是非常耗费资源的,而且在内存缓冲区和磁盘中间存在一个高速缓存(cache),一旦文件进入到 cache 就可以像磁盘上的 segment 一样被读取了。
写入过程 2.0
- 不断将 Document 写入到 In-memory buffer (内存缓冲区)。
- 当满足一定条件后内存缓冲区中的 Documents 刷新到 高速缓存(cache)。
- 生成新的 segment ,这个 segment 还在 cache 中。
- 这时候还没有 commit ,但是已经可以被读取了。
画图如下:
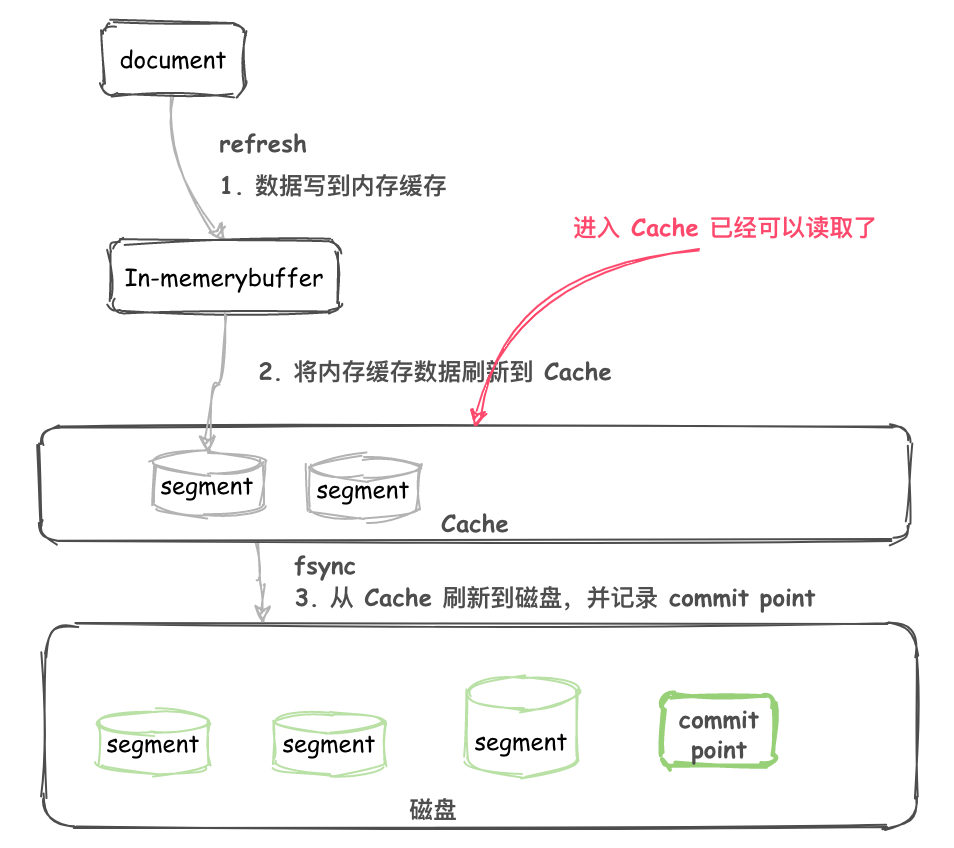
数据从 buffer 到 cache 的过程是定期每秒刷新一次。所以新写入的 Document 最慢 1 秒就可以在 cache 中被搜索到。
而 Document 从 buffer 到 cache 的过程叫做 ?refresh 。一般是 1 秒刷新一次,不需要进行额外修改。当然,如果有修改的需要,可以参考文末的相关资料。这也就是为什么说 Elasticsearch 是准实时的。
使文档立即可见:
PUT /test/_doc/1?refresh
{"test": "test"}
// 或者
PUT /test/_doc/2?refresh=true
{"test": "test"}
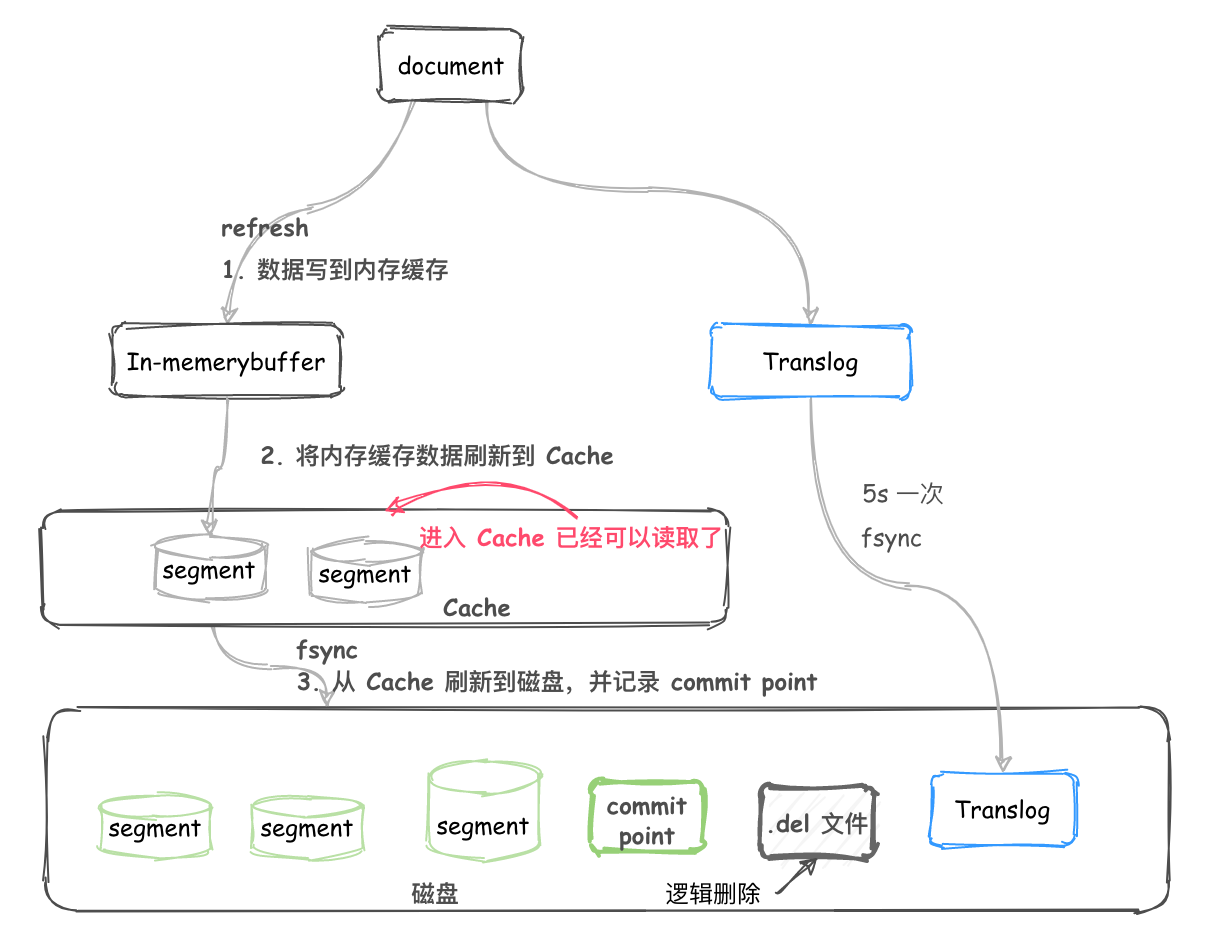
Translog 事务日志
此处可以联想 Mysql 的 binlog, ES 中也存在一个 translog 用来失败恢复。
- Document 不断写入到 In-memory buffer,此时也会追加 translog。
- 当 buffer 中的数据每秒 refresh 到 cache 中时,translog 并没有进入到刷新到磁盘,是持续追加的。
- translog 每隔 5s 会 fsync 到磁盘。
- translog 会继续累加变得越来越大,当 translog 大到一定程度或者每隔一段时间,会执行 flush。
![]()
flush 操作会分为以下几步执行:
- buffer 被清空。
- 记录 commit point。
- cache 内的 segment 被 fsync 刷新到磁盘。
- translog 被删除。
![]()
值得注意的是:
- translog 每 5s 刷新一次磁盘,所以故障重启,可能会丢失 5s 的数据。
- translog 执行 flush 操作,默认 30 分钟一次,或者 translog 太大 也会执行。
手动执行flush:
POST /my-index-000001/_flush
删除和更新
segment 不可改变,所以 docment 并不能从之前的 segment 中移除或更新。
所以每次 commit, 生成 commit point 时,会有一个 .del 文件,里面会列出被删除的 document(逻辑删除)。
而查询时,获取到的结果在返回前会经过 .del 过滤。
更新时,也会标记旧的 docment 被删除,写入到 .del 文件,同时会写入一个新的文件。此时查询会查询到两个版本的数据,但在返回前会被移除掉一个。
segment 合并
每 1s 执行一次 refresh 都会将内存中的数据创建一个 segment。
segment 数目太多会带来较大的麻烦。 每一个 segment 都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个 segment ;所以 segment 越多,搜索也就越慢。
在 ES 后台会有一个线程进行 segment 合并。
- refresh操作会创建新的 segment 并打开以供搜索使用。
- 合并进程选择一小部分大小相似的 segment,并且在后台将它们合并到更大的 segment 中。这并不会中断索引和搜索。
- 当合并结束,老的 segment 被删除 说明合并完成时的活动:
- 新的 segment 被刷新(flush)到了磁盘。 写入一个包含新 segment 且排除旧的和较小的 segment的新 commit point。
- 新的 segment 被打开用来搜索。
- 老的 segment 被删除。
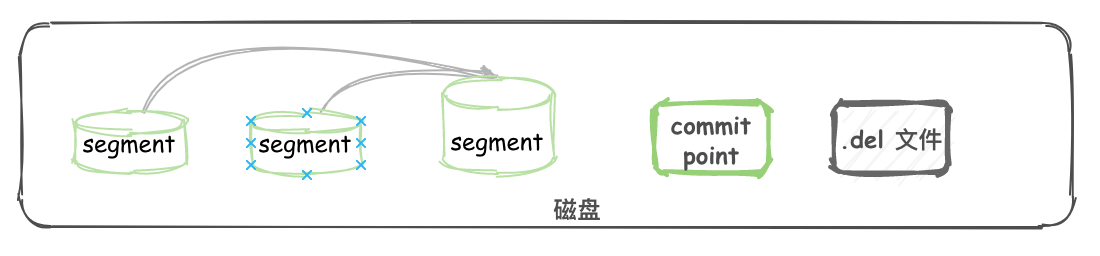
物理删除:
在 segment merge 这块,那些被逻辑删除的 document 才会被真正的物理删除。
总结
主要介绍了内部写入和删除的过程,需要了解 refresh、fsync、flush、.del、segment merge 等名词的具体含义。
完整画图如下:
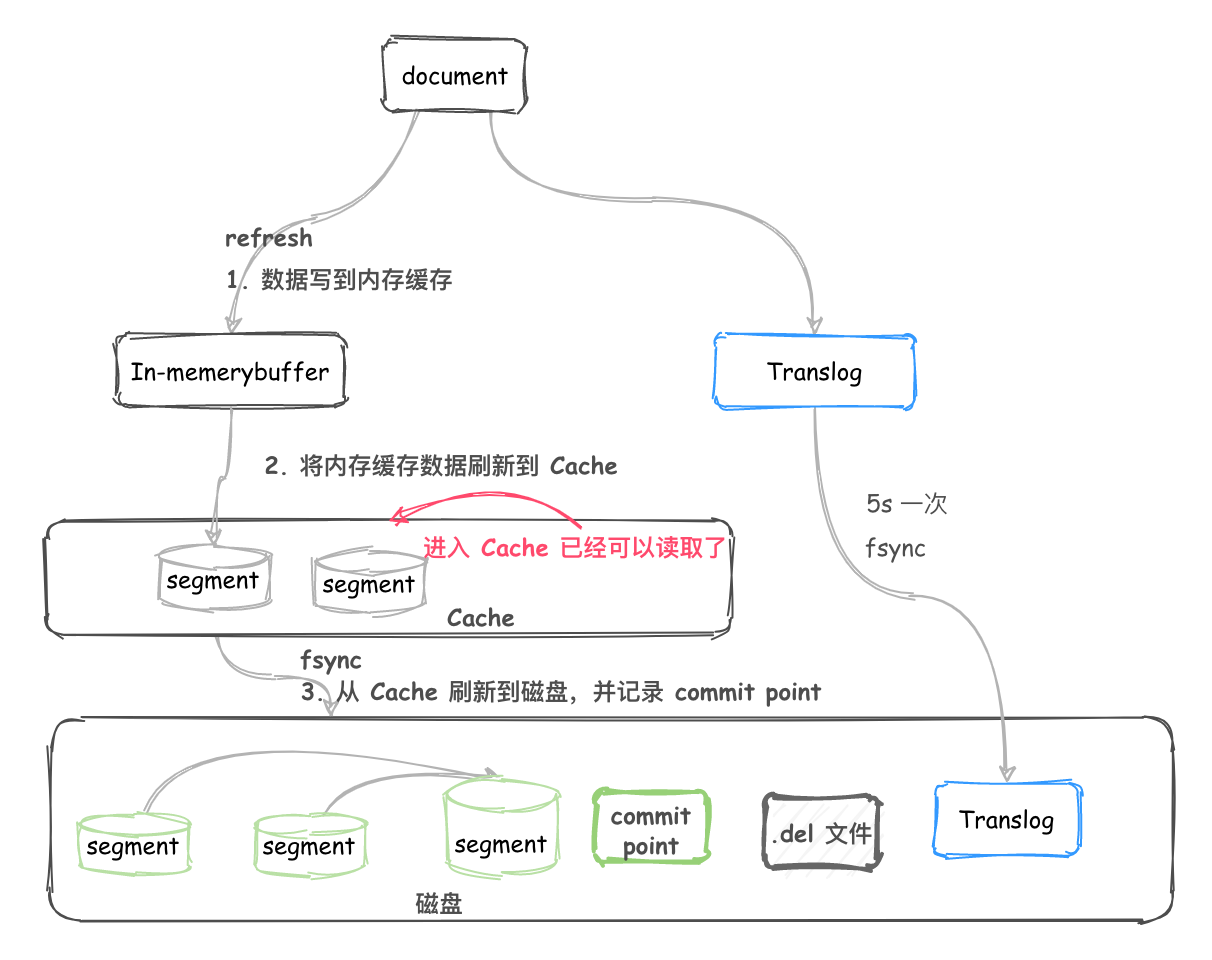
以上就是个人分享的 ES 相关的内容,主要目的是组内技术分享,进行扫盲。不对之处,希望大家留言指正。
相关资料
- 准实时搜索: https://www.elastic.co/guide/en/elasticsearch/reference/7.9/near-real-time.html
- Refresh API:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/indices-refresh.html
- Flush API:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/indices-flush.html
【Elasticsearch 技术分享】—— 十张图带大家看懂 ES 原理 !明白为什么说:ES 是准实时的!的更多相关文章
- SDWebImage实现原理--两张图带你看懂
SDWebImage底层实现有沙盒缓存机制,主要由三块组成:1.内存图片缓存,2.内存操作缓存,3.磁盘沙盒缓存 SDWebImage GitHub地址 版本4.0.0 一.SDWebImage时序图 ...
- 一张图带你看懂SpriteKit中Update Loop究竟做了神马!
1首先Scene中只有开始一点时间用来回调其中的update方法 ;] 2然后是Scene中所有动作的模拟 3接下来是上一步完成之后,给你一个机会执行一些代码 4然后是Scene模拟其中的物理世界 5 ...
- 一张图带你看懂原始dao与SQL动态代理开发的区别-Mybatis
//转载请注明出处:https://www.cnblogs.com/nreg/p/11156167.html 1.项目结构区别: 2.开发区别: 注:其中原始dao开发的实现类UserDaoImpl ...
- RocketMQ入门到入土(一)新手也能看懂的原理和实战!
学任何技术都是两步骤: 搭建环境 helloworld 我也不例外,直接搞起来. 一.RocketMQ的安装 1.文档 官方网站 http://rocketmq.apache.org GitHub h ...
- 教你看懂Code128条形码
首 页 条码控件 条码技术 条码新闻 合作伙伴 联系我们 常见问题 电话:010-84827961 当前位置:条形码控件网 > 条形码控件技术文章 > >正文 教你看懂C ...
- 腾讯技术分享:微信小程序音视频与WebRTC互通的技术思路和实践
1.概述 本文来自腾讯视频云终端技术总监rexchang(常青)技术分享,内容分别介绍了微信小程序视音视频和WebRTC的技术特征.差异等,并针对两者的技术差异分享和总结了微信小程序视音视频和WebR ...
- 腾讯技术分享:微信小程序音视频技术背后的故事
1.引言 微信小程序自2017年1月9日正式对外公布以来,越来越受到关注和重视,小程序上的各种技术体验也越来越丰富.而音视频作为高速移动网络时代下增长最快的应用形式之一,在微信小程序中也当然不能错过. ...
- FUNMVP:几张图看懂区块链技术到底是什么?(转载)
几张图看懂区块链技术到底是什么? 本文转载自:http://www.cnblogs.com/behindman/p/8873191.html “区块链”的概念可以说是异常火爆,好像互联网金融峰会上没人 ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
随机推荐
- 【Hadoop】伪分布式安装
创建hadoop用户 创建用户命令: sudo useradd -m hadoop -s /bin/bash 创建好后需要更改hadoop用户的密码,命令如下: sudo passwd hadoop ...
- 实验 6:OpenDaylight 实验——OpenDaylight 及 Postman 实现流表下发
一.实验目的 熟悉 Postman 的使用;熟悉如何使用 OpenDaylight 通过 Postman 下发流表. 二.实验任务 流表有软超时和硬超时的概念,分别对应流表中的 idle_timeou ...
- Object.assign()的使用
一.Object.assign()对象的拷贝 1 Object.assign() 方法用于将所有可枚举属性的值从一个或多个源对象复制到目标对象.它将返回目标对象. 2 Object.assign(ta ...
- 项目使用eslint
今天eslint版本更新了,然后昂,有些奇奇怪怪的错误提示了,然后想,这我得 1.配置一个保存时根据eslint规则自动修复 2.欸,之前编码遇到未使用的变量都会有标记黄线,我很好定位,这会怎么没了 ...
- xxe 新手学习记录
在做某题时遇到了xxe漏洞,学习+记录 这里因为环境暂时关了,现在复现不了,所以在网络上又找到了一些xxe题目环境 这里有 PikaChu靶场里的xxe环境,这个环境可以在BUUCTF里开,但是这里我 ...
- springmvc执行原理
大家是否遇到过被面试官问了这样一句话:"来聊聊springmvc执行原理".是的,springmvc的执行流程是面试的高频点,今天我就来浅谈它! 一.下面通过一个简单的spring ...
- MeteoInfoLab脚本示例:利用比湿、温度计算相对湿度
利用比湿和温度计算相对湿度的函数是qair2rh(qair, temp, press=1013.25),三个参数分别是比湿.温度和气压,气压有一个缺省值1013.25,因此计算地面相对湿度的时候也可以 ...
- Celery---一个懂得异步任务,延时任务,周期任务的芹菜
Celery是什么? celey是芹菜 celery是基于Python实现的模块,用于执行异步延时周期任务的 其结构组成是由 1.用户任务 app 2.管道任务broker用于存储任务 官方推荐red ...
- 《python 网络数据采集》代码更新
<python 网络数据采集>这本书中会出现很多这一段代码: 1 from urllib.request import urlopen 2 from bs4 import Beautifu ...
- 学不动了!微信官方推出 Web 前端和小程序统一框架 Kbone
听说最近微信官方推出了一个统一 Web 前端和小程序的框架 -- Kbone ,特意去看了下... 为什么微信要搞Kbone? 微信小程序的底层模型和 Web 端不同,开发者无法直接把 Web 端的代 ...