SPFA算法详解
前置知识:Bellman-Ford算法
前排提示:SPFA算法非常容易被卡出翔。所以如果不是图中有负权边,尽量使用Dijkstra!(Dijkstra算法不能能处理负权边,但SPFA能)
前排提示*2:一定要先学Bellman-Ford!
0.引子
在Bellman-Ford算法中,每条边都要松弛\(n-1\)轮,还不一定能松弛成功,这实在是太浪费了。能不能想办法改进呢?
非常幸运,SPFA算法能做到这点。(SPFA又名“Bellman-Ford的队列优化”,就是这个原因。)
1.基本思想
先说一个结论:只有一个点在上一轮被松弛成功时,这一轮从这个点连出的点才有可能被成功松弛。
为什么?显而易见
好吧其实我当初也花了不少时间理解这玩意
松弛的本质其实是通过一个点中转来缩短距离(如果你看了前置很容易理解)。所以,如果起点到一个点的距离因为某种原因变小了,从起点到这个距离变小的点连出的点的距离也有可能变小(因为可以通过变小的点中转)。(通读三遍再往下看)
所以,可以在下一轮只用这一轮松弛成功的点进行松弛,这就是SPFA的基本思想。
2.用队列实现
我们知道了在下一轮只用这一轮松弛成功的点进行松弛,就可以把这一轮松弛成功的点放进队列里,下一轮只用从队列里取出的点进行松弛。
为什么是队列而不是其他的玄学数据结构?因为队列具有“先进先出,后进后出”的特点,可以保证这一轮松弛的点不会在这一轮结束之前取出。
干说可能不太理解,所以还是举个栗子吧。
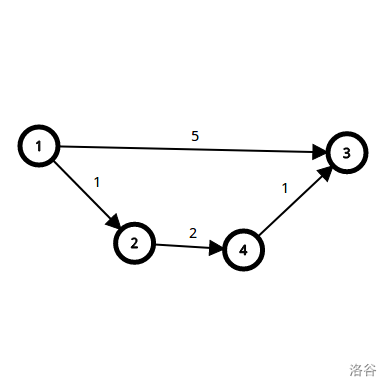
这又是之前的有向图,但是这次我们要用SPFA跑。
最开始,我们要把\(1\)号点放进队列(为什么要这样?先往下看)。\(dis\)数组和队列是这个亚子的:
| \(i\) | \(dis[i]\) |
|---|---|
| \(1\) | \(0\) |
| \(2\) | \(\infty\) |
| \(3\) | \(\infty\) |
| \(4\) | \(\infty\) |
| queue | 1 |
|---|
用\(1\)号点进行松弛(就是\(1\)号到\(1\)号再到目标点):
| \(i\) | \(dis[i]\) |
|---|---|
| \(1\) | \(0\) |
| \(2\) | \(1\) |
| \(3\) | \(5\) |
| \(4\) | \(\infty\) |
| queue | 2 | 3 |
|---|
\(2,3\)号点被松弛成功了,把它们加入到队列里。
\(1\)号点被用过了,把它扔掉。(工具点石锤)
用\(2\)号点进行松弛:
| \(i\) | \(dis[i]\) |
|---|---|
| \(1\) | \(0\) |
| \(2\) | \(1\) |
| \(3\) | \(5\) |
| \(4\) | \(3\) |
| queue | 3 | 4 |
|---|
\(4\)号点被松弛成功了,把它们加入到队列里。
\(2\)号点被用过了,把它扔掉。
用\(3\)号点进行松弛:
| \(i\) | \(dis[i]\) |
|---|---|
| \(1\) | \(0\) |
| \(2\) | \(1\) |
| \(3\) | \(5\) |
| \(4\) | \(3\) |
| queue | 4 |
|---|
没有点被松弛成功。
\(3\)号点被用过了,把它扔掉。
用\(4\)号点进行松弛:
| \(i\) | \(dis[i]\) |
|---|---|
| \(1\) | \(0\) |
| \(2\) | \(1\) |
| \(3\) | \(4\) |
| \(4\) | \(3\) |
| queue | 3 |
|---|
\(3\)号点被松弛成功了,把它们加入到队列里。
\(4\)号点被用过了,把它扔掉。
用\(3\)号点进行松弛:
| \(i\) | \(dis[i]\) |
|---|---|
| \(1\) | \(0\) |
| \(2\) | \(1\) |
| \(3\) | \(4\) |
| \(4\) | \(3\) |
| queue |
|---|
没有点被松弛成功。
\(3\)号点被用过了,把它扔掉。
现在队列为空(也就是能松弛的都松弛了),算法结束。
3.Code
SPFA的具体实现,推荐结合上面的栗子食用。
#include <bits/stdc++.h>
using namespace std;
#define MAXN 10005
#define INF 0x7fffffff
int n,m,s,dis[MAXN];
vector<pair<int,int> > g[MAXN];//用vector存图,但是据说链式前向星更快
void spfa(){
queue<int> q;
q.push(s);//把初始点加入队列
fill(dis+1,dis+1+n,INF);//因为一开始所有点都到不了,所以初始化为INF
dis[s]=0;//自己到自己肯定距离为0
while(!q.empty()){
int u=q.front();
q.pop();//从队列里取出第一个元素
for(int i=0;i<g[u].size();i++){
int v=g[u][i].first,w=g[u][i].second;
if(dis[v]>dis[u]+w){
dis[v]=dis[u]+w;
q.push(v);
}
//如果能松弛成功,那么松弛,把松弛成功的目标点放入队列
}
}
}
int main(){
scanf("%d%d%d",&n,&m,&s);
for(int i=1;i<=m;i++){
int u,v,w;
scanf("%d%d%d",&u,&v,&w);
g[u].push_back(make_pair(v,w));
}//输入,建图
spfa();
for(int i=1;i<=n;i++){
printf("%d ",dis[i]);
}//输出
return 0;
}
这个代码能够ACP3371,但是我还是推荐你自己码一遍。
4.特点
- 能够处理有负权边的图,但是隔壁Dijkstra不行。
- 在有负环的情况下,不存在最短路,因为不停在负环上绕就能把最短路刷到任意低。但是SPFA能够判断图中是否存在负环,具体方法为统计每个点的入队次数,如果有一个点入队次数$ \ge n $,那么图上存在负环,也就不存在最短路了。
- 什么?你不知道什么叫负环?下面的就是。
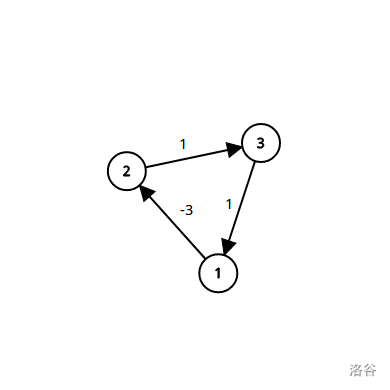
就是一个环,边权和是负。一般用一个名为菜鸡算法的算法判断
——Ynoi
- SPFA的时间复杂度是\(O(km)\),\(k\)是每一个节点的平均入队次数,经过实践,\(k\)一般为\(4\),所以SPFA通常情况下非常高效。但是SPFA非常容易被卡出翔,最坏情况下会变成\(O(nm)\)! 所以如果能用隔壁Dijkstra尽量不要用SPFA。至于具体怎么卡,据说是这样的:
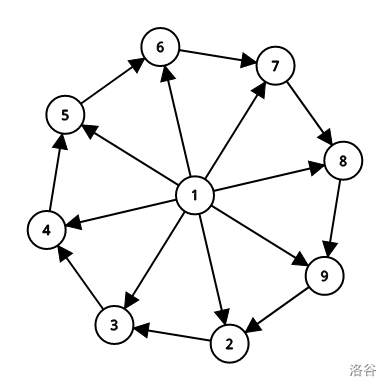
(这种图据说叫菊花图,能欺骗SPFA多次让点进入队列,所以\(k\)会变得非常大(上限为\(n\))。)
5.你都看到这了就不点一个赞吗?
这个最重要了qwq
SPFA算法详解的更多相关文章
- 图的最短路径-----------SPFA算法详解(TjuOj2831_Wormholes)
这次整理了一下SPFA算法,首先相比Dijkstra算法,SPFA可以处理带有负权变的图.(个人认为原因是SPFA在进行松弛操作时可以对某一条边重复进行松弛,如果存在负权边,在多次松弛某边时可以更新该 ...
- SPFA 算法详解
适用范围:给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了. 我们约定有向加权图G不存在负权回路,即最短路径 ...
- SPFA 算法详解( 强大图解,不会都难!) (转)
适用范围:给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了. 我们约定有向加权图G不存在负权回路,即最短路径 ...
- Bellman-Ford算法与SPFA算法详解
PS:如果您只需要Bellman-Ford/SPFA/判负环模板,请到相应的模板部分 上一篇中简单讲解了用于多源最短路的Floyd算法.本篇要介绍的则是用与单源最短路的Bellman-Ford算法和它 ...
- Bellman-Ford&&SPFA算法详解
Dijkstra在正权图上运行速度很快,但是它不能解决有负权的最短路,如下图: Dijkstra运行的结果是(以1为原点):0 2 12 6 14: 但手算的结果,dist[4]的结果显然是5,为什么 ...
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
随机推荐
- SpringBoot动态注入Bean
目的: 在程序运行期间,动态添加Bean进入到Spring容器. 目前使用到的场景: 对当当网的ElasticJob进行封装,通过自定义注解@ElasticJob的方式开启分布式定时任务. 当所有的B ...
- PHP chop() 函数
实例 移除字符串右侧的字符: <?php$str = "Hello World!";高佣联盟 www.cgewang.comecho $str . "<br& ...
- 海华大赛第一名团队聊比赛经验和心得:AI在垃圾分类中的应用
摘要:为了探究垃圾的智能分类等问题,由中关村海华信息研究院.清华大学交叉信息研究院以及Biendata举办的2020海华AI垃圾分类大赛吸引了大量工程师以及高校学生的参与 01赛题介绍 随着我国经济的 ...
- Golang SQL连接池梳理
目录 一.如何理解数据库连接 二.连接池的工作原理 三.database/sql包结构 四.三个重要的结构体 4.1.DB 4.2.driverConn 4.3.Conn 五.流程梳理 5.1.先获取 ...
- Efficient Knowledge Graph Accuracy Evaluation 论文笔记
前言 这篇论文主要讲的是知识图谱正确率的评估,将知识图谱的正确率定义为知识图谱中三元组表述正确的比例.如果要计算知识图谱的正确率,可以用人力一一标注是否正确,计算比例.但是实际上,知识图谱往往很大,不 ...
- jar包冲突解决
背景: 新需求需要引入新jar包,引入后发现本地启动没有报错,发到测试环境提示某个bean无法创建,nested exception is java.lang.VerifyError: Bad typ ...
- 数据结构C语言实现----快速排序
快速排序算法 首先看下面这个例子: 我们取第一个元素为基准元素: 之后,从右边开始与基准元素挨个比较,如果比基准元素大,右指针往左移,如果比基准元素小,就与左指针指的元素交换(因为左指针永远停留在一 ...
- 实验04——java保留小数的两种方法、字符串转数值
package cn.tedu.demo; import java.text.DecimalFormat; /** * @author 赵瑞鑫 E-mail:1922250303@qq.com * @ ...
- excel-格式处理
问题[1]:将excl中数据导出txt,并且每列之间距离一个空格 在C1(任意空列) 输入=A1&" "&B1" "中间是一个半角英文空格下拉 ...
- Springboot Xss注入过滤
1.编写 XssHttpServletRequestWrapper import javax.servlet.http.HttpServletRequest; import javax.servle ...