pandas 学习 第14篇:索引和选择数据
数据框和序列结构中都有轴标签,轴标签的信息存储在Index对象中,轴标签的最重要的作用是:
- 唯一标识数据,用于定位数据
- 用于数据对齐
- 获取和设置数据集的子集。
本文重点关注如何对序列(Series)和数据框(DataFrame)进行切片(slice),切块(dice)、如何获取和设置子集。
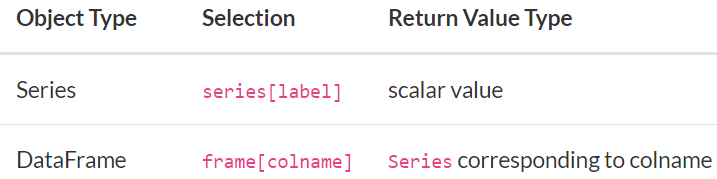
下表列出数据框最基本的操作及其语法:

一,最基本的选择操作
最基本的选择都是使用中括号[]来实现,但是只能实现单个维度的选择。序列(Series)最基本的选择是使用行标签来选择一个标量值,数据框(DataFrame)最基本的选择是使用列名获得一个序列。对于序列来说,如果行索引是整数,那么轴标签就是整数;对于数据框而言,列的标签通常都是文本类型。
创建一个数据框,用于数据演示:
df = pd.DataFrame(np.random.randn(8, 4), columns=['A', 'B', 'C', 'D'])
从数据框中获取A列的数据:
>>> df["A"]
0 -0.053212
1 0.053226
2 0.768993
3 -0.319555
4 0.671913
5 -1.021473
6 1.304257
7 1.215003
Name: A, dtype: float64
从数据框中选择多个列的数据:
df[["A","B"]]
数据框的一列是一个序列,从序列中获得一个标量值:
>>> s=df["A"]
>>> s[0]
-0.05321219353405595
从序列中选择多行的数据:
s[[0,1]]
二,使用loc 和 iloc来选择数据
索引的选择主要是基于标签的选择和基于位置的选择,对于索引来说,位置序号默认从0开始,到length(index)-1 结束。
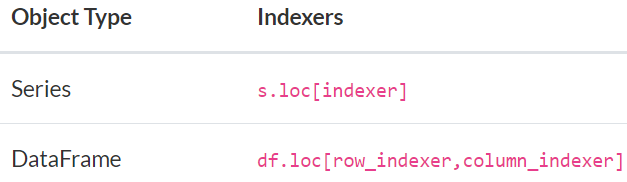
对于数据框而言,如果没有填写row_indexer 或 column_indexer,那么表示所有的row或column。在row_indexer和column_indexer中,可以使用连续的标签,比方说,0:4,表示从0到4的一个range,即0、1、2、3,注意不包含4。
1,基于标签的选择
.loc 属性用于基于轴标签选择特定的轴,df是数据框结构:
- 单个标签:df.loc["row"], df.loc["row","col"]
- 多个离散的标签:df.loc[["row1","row2","row3"]],df.loc[["row1","row2","row3"],["col1","col2"]]
- 连续的标签:df.loc["row0":"row3"],df.loc["row0":"row3","col0":"col3"]
- 布尔掩码数组,对于数据框,所有的行构成一个序列,每行都对应一个掩码,如果掩码为True,表示选择该行;如果为False,表示忽略该行。同理,数据框中的所有列也构成一个序列,每列都对应一个掩码,如果掩码为True,表示选择该列;如果为False,表示忽略该列。
使用连续的标签,获得数据框的一个切片:
df.loc[0:1]
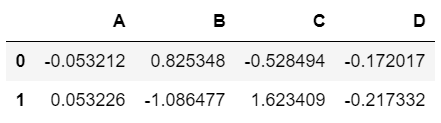
使用多个离散的标签获得特定的行和列:
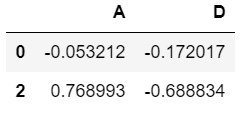
df.loc[[0,2],["A","D"]]
2,基于位置的选择
.iloc属性用于基于位置的选择,位置序号从0开始,到轴长(axis length-1)截止:
- 单个位置
- 多个离散的位置
- 连续的位置
- 布尔掩码数组
跟基于标签的选项相比,只不过把标签换成了位置。
三,布尔掩码索引
布尔操作符是: &, | , ~,分别表示 与、或、非。通过操作符,可以把多个布尔值组合成一个逻辑表达式。
当使用布尔掩码向量来作为索引时,布尔向量的长度必须和索引的长度相同。这就意味着,如果一个序列有5行,那么布尔向量必须有5行;如果一个数据框有6列,那么用于选择列的布尔向量必须有5个元素。
例如,获得列A的数据,获得一个序列,对序列进行逻辑运算,得到一个布尔向量:
df["A"]>0

用布尔向量来过滤数据行,得到基于数据掩码的选择:
df.loc[df["A"]>0,["A","B"]]

使用布尔掩码向量作为行索引,由于行索引有8个,即Range(8),因此,布尔掩码向量必须有8行。df["A"]>0 返回一个布尔向量,是由8个布尔值构成的向量。当元素值是Ture时,表示选择该行;当元素值是False时,表示忽略该行。
也可以对布尔向量进行逻辑运算,比如:
s[(s < -1) | (s > 0.5)]
四,通过可调用的函数来选择数据
数据框和序列的 .loc, .iloc 和 [] 都可以接收一个可调用的函数( callable function)作为索引, 可调用的函数必须只有一个参数,并且参数是序列或数据框,返回的是布尔掩码向量。
举个例子,使用lambda定义函数,下面两个脚本是等价的。
df.loc[lambda df: df['A'] > 0, ["A","B"]]
df.loc[df["A"]>0,["A","B"]]
五,isin函数
判断单个值或多个值是否存在于序列或数据框中,返回的是布尔值掩码,并可以通过掩码来会返回值:
In [157]: s.isin([v1,v2,...]) In [158]: s[s.isin([v1,v2,...])]
六,where函数和mask函数
where()函数接收的参数是布尔掩码,返回的shape跟原始的序列和数据框相同,只不过布尔值为False的元素被设置为NaN,布尔值为True的元素显示为原始值,即,把布尔掩码为False的元素掩蔽。
例如,序列s是df["A"],s>0是一个布尔掩码,下面的代码返回的是一个序列,只不过掩码为False的元素全部为NaN,where()函数的作用是布尔掩码为True的返回,为False的设置为NaN。
s.where(s>0)

mask()函数接收的参数也是布尔掩码,返回的shape跟原始序列或数据框也相同,只不过布尔值为False的元素显示为原始值,而布尔值为True的元素显示为NaN,即,把不二掩码为True的元素掩蔽。
七,query()函数
query()函数可以使用表达式来选择数据框,以简化数据框的查询,比如,以下两段代码返回的结果是相同的,而使用query()函数的代码更简洁:
# 布尔组合
df[(df['a'] < df['b']) & (df['b'] < df['c'])]
df.query('(a < b) & (b < c)') # isin
df[df['a'].isin(df['b'])]
df.query('a in b') # not in
df.query('a not in b')
df[~df['a'].isin(df['b'])] #布尔组合
df.query('a in b and c < d')
df[df['b'].isin(df['a']) & (df['c'] < df['d'])]
在query()函数中,可以使用关键字 index来代替数据框的index属性:
df.query('index < b < c')
在query()函数中,使用 == [] 等价于 in;使用 != [] 等价于 not in
# in
df.query('b == ["a", "b", "c"]')
df[df['b'].isin(["a", "b", "c"])] # not in
df.query('c != [1, 2]')
df.query('[1, 2] not in c')
参考文档:
pandas 学习 第14篇:索引和选择数据的更多相关文章
- pandas 学习 第5篇:DataFrame - 访问数据框
数据框是用于存储数据的二维结构,分为行和列,一行和一列的交叉位置是一个cell,该cell的位置是由行索引和列索引共同确定的.可以通过at/iat,或loc/iloc属性来访问数据框的元素,该属性后跟 ...
- pandas 学习 第2篇:Series -(创建,属性,转换和索引)
序列(Series)是由一组数据(各种NumPy数据类型),以及一组与之相关的数据标签(索引)组成,序列不要求数据类型是相同的. 序列是一个一维数组,只有一个维度(或称作轴)是行(row),在访问序列 ...
- pandas 学习 第8篇:Index 对象 - (创建、转换、排序)
Index对象负责管理轴标签.轴名称等元数据,是一个不可修改的.有序的.可以索引的ndarry对象.在构建Sereis或DataFrame时,所用到的任何数据或者array-like的标签,都会转换为 ...
- Pandas 学习 第9篇:DataFrame - 数据的输入输出
常用的数据存储介质是数据库和csv文件,pandas模块包含了相应的API对数据进行输入和输出: 对于格式化的平面文件:read_table() 对于csv文件:read_csv().to_csv() ...
- Python 数据分析 - 索引和选择数据
loc,iloc,ix三者间的区别和联系 loc .loc is primarily label based, but may also be used with a boolean array. 就 ...
- pandas 学习 第7篇:DataFrame - 数据处理(应用、操作索引、重命名、合并)
DataFrame的这些操作和Series很相似,这里简单介绍一下. 一,应用和应用映射 apply()函数对每个轴应用一个函数,applymap()函数对每个元素应用一个函数: DataFrame. ...
- Pandas索引和选择数据
在本章中,我们将讨论如何切割和丢弃日期,并获取Pandas中大对象的子集. Python和NumPy索引运算符"[]"和属性运算符".". 可以在广泛的用例中快 ...
- Pandas | 13 索引和选择数据
Pandas现在支持三种类型的多轴索引; 编号 索引 描述 1 .loc() 基于标签 2 .iloc() 基于整数 3 .ix() 基于标签和整数 .loc() Pandas提供了各种方法来完成基于 ...
- pandas 学习 —— 逻辑表达式与布尔索引
>> df = pd.DataFrame(np.random.randint(0, 10, (5, 4)), columns=list('ABCD')) A B C D 0 0 4 8 4 ...
随机推荐
- txt文件覆盖恢复
1.txt文件恢复到之前保存的版本 2.电脑未重启 方式:如果你使用系统还原可以用"还原以前的版本"功能来轻松找回. 右击.txt文件-还原以前的版本-选择时间点-还原
- [head first 设计模式]第二章 观察者模式
[head first 设计模式]第二章 观察者模式 假如我们有一个开发需求--建造一个气象观测站展示系统.需求方给我们提供了一个WeatherObject对象,能够自动获得最新的测量数据.而我们要建 ...
- 苹果电脑不安装flash的话怎么看直播
直播这种娱乐方式的兴起,让很多游戏玩家.脱口秀演员.歌手等拥有了一个更加宽广的舞台,可以更好地展现自己的才能.大部分的直播都是采取视频影像的方式直播,只有少部分才会采用纯音频的方式. 由于很多直播网站 ...
- FL Studio中的文件设置介绍
在fl中,我们想要找到文件设置选项,可以在主菜单中选择选项-文件设置来打开,也可以通过按"F10"快捷键来一步打开." 文件设置"页面可以将其他文件夹链接到浏览 ...
- JS 数组对象
定义数组: 数组对象用来在单独的变量名中存储一系列的值. 创建一个数组有三种方法. 1: 常规方式: var myCars=new Array(); myCars[0]="Saab" ...
- go学习路线资料
编辑器 JetBrains公司出品的,goland go初步学习路线 Go 指南 如何使用Go编程 实效Go编程 Go by Example 中文版 参考: Go 语言学习资料与社区索引 Go入门指南 ...
- css万能清除原理
如果现在能有清理浮动的办法,但不至于在文档中多一个没有用的空标记,这时的效果是最好的!引入:after伪元素选择器,可以在指定的元素的内容添加最后一个子元素 .container:after{ } 如 ...
- 使用KVM的API编写一个简易的AArch64虚拟机
参考资料: Linux虚拟化KVM-Qemu分析(一) Linux虚拟化KVM-Qemu分析(二)之ARMv8虚拟化 Linux虚拟化KVM-Qemu分析(三)之KVM源码(1) Linux虚拟化KV ...
- Cys_Control(二) MButton
一.添加自定义Button 二.Xaml文件自动关联 Custom Control 取名与资源文件相同加.cs文件将自动关联 Themes文件下Generic.xaml引入该控件,用于对外公布样式 & ...
- 第5章函数进阶 第5.1节 Python函数的位置参数、关键字参数精讲
前面第二章简单介绍了函数定义的语法,经过后面一系列的学习,函数有必要再次介绍一下相关内容. 一. 关于函数的语法 1. 语法 def 函数名([参数]): 函数文档字符串 函数体 ...