python核心高级学习总结3-------python实现进程的三种方式及其区别
python实现进程的三种方式及其区别
1.fork()方法
ret = os.fork()
if ret == 0:
#子进程
else:
#父进程
这是python中实现进程最底层的方法,其他两种从根本上也是利用fork()方法来实现的,下面是fork()方法的原理示意图
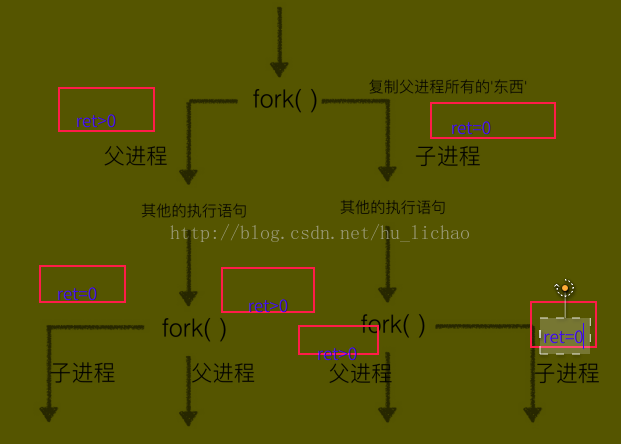
import os
rpid = os.fork()
if rpid<0:
print("fork调⽤失败。 ")
elif rpid == 0:
print("我是⼦进程( %s) , 我的⽗进程是(%s) "%(os.getpid(),os.getppid()))
x+=1
else:
print("我是⽗进程( %s) , 我的⼦进程是( %s) "%(os.getpid(),rpid))
print("⽗⼦进程都可以执⾏这⾥的代码")运行结果:
我是⽗进程( 19360) , 我的⼦进程是( 19361)
⽗⼦进程都可以执⾏这⾥的代码
我是⼦进程( 19361) , 我的⽗进程是( 19360)
⽗⼦进程都可以执⾏这⾥的代码#coding=utf-8
import os
import time
num = 0
# 注意, fork函数, 只在Unix/Linux/Mac上运⾏, windows不可以
pid = os.fork()
if pid == 0:
num+=1
print('哈哈1---num=%d'%num)
else:
time.sleep(1)
num+=1
print('哈哈2---num=%d'%num)运行结果
哈哈1---num=1
哈哈2---num=1
#多进程不共享全局变量多次fork()问题
2,Process方法
from multiprocessing import Process
p1=Process(target=xxxx)
p1.start()#coding=utf-8
from multiprocessing import Process
import os
# ⼦进程要执⾏的代码
def run_proc(name):
print('⼦进程运⾏中, name= %s ,pid=%d...' % (name, os.getpid()))
if __name__=='__main__':
print('⽗进程 %d.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('⼦进程将要执⾏')
p.start()
p.join()
print('⼦进程已结束')⽗进程 4857.
⼦进程将要执⾏
⼦进程运⾏中, name= test ,pid=4858...
⼦进程已结束is_alive(): 判断进程实例是否还在执⾏;
join([timeout]): 是否等待进程实例执⾏结束, 或等待多少秒;
start(): 启动进程实例( 创建⼦进程) ;
run(): 如果没有给定target参数, 对这个对象调⽤start()⽅法时, 就将执⾏对象中的run()⽅法;
terminate(): 不管任务是否完成, ⽴即终⽌;
3,利用进程池Pool
from multiprocessing import Pool
pool=Pool(3)
pool.apply_async(xxxx)from multiprocessing import Pool
import os,time,random
def worker(msg):
t_start = time.time()
print("%s开始执⾏,进程号为%d"%(msg,os.getpid()))
#random.random()随机⽣成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执⾏完毕, 耗时%0.2f"%(t_stop-t_start))
po=Pool(3) #定义⼀个进程池, 最⼤进程数3
for i in range(0,10):
#Pool.apply_async(要调⽤的⽬标,(传递给⽬标的参数元祖,))
#每次循环将会⽤空闲出来的⼦进程去调⽤⽬标
po.apply_async(worker,(i,))
print("----start----")
po.close() #关闭进程池, 关闭后po不再接收新的请求
po.join() #等待po中所有⼦进程执⾏完成, 必须放在close语句之后
print("-----end-----")运行结果
----start----
----start----
0开始执⾏,进程号为5025
----start----
1开始执⾏,进程号为5026
----start----
----start----
----start----
----start----
----start----
----start----
----start----
2开始执⾏,进程号为5027
0 执⾏完毕, 耗时0.58
3开始执⾏,进程号为5025
1 执⾏完毕, 耗时0.70
4开始执⾏,进程号为5026
2 执⾏完毕, 耗时1.36
5开始执⾏,进程号为5027
3 执⾏完毕, 耗时1.03
6开始执⾏,进程号为5025
4 执⾏完毕, 耗时1.12
7开始执⾏,进程号为5026
5 执⾏完毕, 耗时1.25
8开始执⾏,进程号为5027
7 执⾏完毕, 耗时1.28
9开始执⾏,进程号为5026
6 执⾏完毕, 耗时1.91
8 执⾏完毕, 耗时1.23
9 执⾏完毕, 耗时1.38
-----end-----from multiprocessing import Pool
import os,time,random
def worker(msg):
t_start = time.time()
print("%s开始执⾏,进程号为%d"%(msg,os.getpid()))
#random.random()随机⽣成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执⾏完毕, 耗时%0.2f"%(t_stop-t_start))
po=Pool(3) #定义⼀个进程池, 最⼤进程数3
for i in range(0,10):
po.apply(worker,(i,))
print("----start----")
po.close() #关闭进程池, 关闭后po不再接收新的请求
po.join() #等待po中所有⼦进程执⾏完成, 必须放在close语句之后
print("-----end-----")运行结果
0开始执⾏,进程号为5280
0 执⾏完毕, 耗时0.91
1开始执⾏,进程号为5281
1 执⾏完毕, 耗时1.59
2开始执⾏,进程号为5282
2 执⾏完毕, 耗时1.25
3开始执⾏,进程号为5280
3 执⾏完毕, 耗时0.53
4开始执⾏,进程号为5281
4 执⾏完毕, 耗时1.49
5开始执⾏,进程号为5282
5 执⾏完毕, 耗时0.18
6开始执⾏,进程号为5280
6 执⾏完毕, 耗时1.51
7开始执⾏,进程号为5281
7 执⾏完毕, 耗时0.88
8开始执⾏,进程号为5282
8 执⾏完毕, 耗时1.08
9开始执⾏,进程号为5280
9 执⾏完毕, 耗时0.12
----start----
-----end-----apply_async(func[, args[, kwds]]) : 使⽤⾮阻塞⽅式调⽤func( 并⾏执⾏, 堵塞⽅式必须等待上⼀个进程退出才能执⾏下⼀个进程) , args为传递给func的参数列表, kwds为传递给func的关键字参数列表;
python核心高级学习总结3-------python实现进程的三种方式及其区别的更多相关文章
- python实现进程的三种方式及其区别
在python中有三种方式用于实现进程 多进程中, 每个进程中所有数据( 包括全局变量) 都各有拥有⼀份, 互不影响 1.fork()方法 ret = os.fork() if ret == 0: # ...
- python核心高级学习总结5--------python实现线程
在代码实现上,线程的实现与进程的实现很类似,创建对象的格式都差不多,然后执行的时候都是用到start()方法,与进程的区别是进程是资源分配和调度的基本单位,而线程是CPU调度和分派的基本单位.其中多线 ...
- 判断python对象是否可调用的三种方式及其区别
查找资料,基本上判断python对象是否为可调用的函数,有三种方法 使用内置的callable函数 callable(func) 用于检查对象是否可调用,返回True也可能调用失败,但是返回False ...
- python核心高级学习总结7---------正则表达式
正则表达式在爬虫项目中应用很广泛,主要方面就是在字符串处理方面,经常会涉及到字符串格式的校验,用起来经常要查看文档才能完成,所以抽了个时间将正则的内容复习了一下. Start re---导入re模块使 ...
- python核心高级学习总结8------动态性、__slots__、生成器、迭代器、装饰、闭包
python的动态性 什么是动态性呢,简单地来说就是可以在运行时可以改变其结构,如:新的函数.对象.代码都可以被引进或者修改,除了Python外,还有Ruby.PHP.javascript等也是动态语 ...
- python核心高级学习总结6------面向对象进阶之元类
元类引入 在多数语言中,类就是一组用来描述如何生成对象的代码段,在python中同样如此,但是在python中把类也称为类对象,是的,你没听错,在这里你只要使用class关键字定义了类,其解释器在执行 ...
- python核心高级学习总结1---------*args和**kwargs
*args 和 ** kwargs 的用法 首先,这两者在用法上都是用来补充python中对不定参数的接受. 比如下面的列子 def wrappedfunc(*args, **kwargs): pri ...
- python核心高级学习总结4-------python实现进程通信
Queue的使用 Queue在数据结构中也接触过,在操作系统里面叫消息队列. 使用示例 # coding=utf-8 from multiprocessing import Queue q = Que ...
- python核心高级学习总结2----------pdb的调试
PDB调试 def getAverage(a,b): result =a+b print("result=%d"%result) return result a=100 b=200 ...
随机推荐
- 1_Two Sum
1.Two Sum Given an array of integers, return indices of the two numbers such that they add up to a s ...
- windows本地破解用户口令
实验所属系列:操作系统安全 实验对象: 本科/专科信息安全专业 相关课程及专业:信息网络安全概论.计算机网络 实验时数(学分):2学时 实验类别:实践实验类 实验目的 1.了解Windows2000/ ...
- leetcode132:4sum
题目描述 给出一个有n个元素的数组S,S中是否有元素a,b,c和d满足a+b+c+d=目标值?找出数组S中所有满足条件的四元组. 注意: 四元组(a.b.c.d)中的元素必须按非降序排列.(即a≤b≤ ...
- 7 apache和nginx的区别
7 apache和nginx的区别 nginx 相对 apache 的优点: 轻量级,同样起web 服务,比apache 占用更少的内存及资源 抗并发,nginx 处理请求是异步非阻塞的,支持更多的并 ...
- 3.2spring源码系列----循环依赖源码分析
首先,我们在3.1 spring5源码系列--循环依赖 之 手写代码模拟spring循环依赖 中手写了循环依赖的实现. 这个实现就是模拟的spring的循环依赖. 目的是为了更容易理解spring源码 ...
- 消息队列--ActiveMQ集群部署
一.activeMQ主要的部署方式? 1,默认的单机部署(kahadb) activeMQ默认的存储单机模式,如果配置文件不做修改,则默认使用此模式.以本地的kahadb文件的方式进行存储,性能完全依 ...
- 弹性盒模型flex-grow的计算
flex-grow属性是弹性盒布局模块的子属性. 它定义了弹性项目在必要时增长的能力. 它接受作为比例的无单位值. 它决定了项目应在伸缩容器内部占用多少可用空间. 例如,如果所有项目的flex-gro ...
- 用 Cloud Performance Test怎么录制测试脚本
Cloud Performance Test 云压力测试平台(以下简称:CPT)可以提供一站式全链路云压力测试服务,通过分布式压力负载机,快速搭建系统高并发运行场景,按需模拟千万级用户实时访问,并结合 ...
- 怎样禁止Ceph OSD的自动挂载
前言 本篇来源于群里一个人的问题,有没有办法让ceph的磁盘不自动挂载,一般人的问题都是怎样让ceph能够自动挂载,在centos 7 平台下 ceph jewel版本以后都是有自动挂载的处理的,这个 ...
- 使用日志系统graylog获取Ceph集群状态
前言 在看集群的配置文件的时候看到ceph里面有一个graylog的输出选择,目前看到的是可以收集mon日志和clog,osd单个的日志没有看到,Elasticsearch有整套的日志收集系统,可以很 ...